单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序。
Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则做出最终的分类决策。随机选取特征。
GBDT:按照一定次序搭建多个分类模型,模型之间存在依赖关系,一般,每一个后续加入的模型都需要对集成模型的综合性能有所贡献,最终期望整合多个弱分类器,搭建出具有更强分类能力的模型。
#coding=utf8 # 导入pandas用于数据分析。 import pandas as pd # 从sklearn.tree中导入决策树分类器。 from sklearn.tree import DecisionTreeClassifier # 使用随机森林分类器进行集成模型的训练以及预测分析。 from sklearn.ensemble import RandomForestClassifier # 使用梯度提升决策树进行集成模型的训练以及预测分析。 from sklearn.ensemble import GradientBoostingClassifier # 从sklearn.model_selection中导入train_test_split用于数据分割。 from sklearn.model_selection import train_test_split # 我们使用scikit-learn.feature_extraction中的特征转换器 from sklearn.feature_extraction import DictVectorizer # 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。 from sklearn.metrics import classification_report titanic = pd.read_csv('./Datasets/Titanic/train.csv') # 机器学习有一个不太被初学者重视,并且耗时,但是十分重要的一环,特征的选择,这个需要基于一些背景知识。根据我们对这场事故的了解,sex, age, pclass这些都很有可能是决定幸免与否的关键因素。 print titanic.info() X = titanic[['Pclass', 'Age', 'Sex']] y = titanic['Survived'] # 对当前选择的特征进行探查。 X['Age'].fillna(X['Age'].mean(), inplace=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state = 33) vec = DictVectorizer(sparse=False) # 转换特征后,我们发现凡是类别型的特征都单独剥离出来,独成一列特征,数值型的则保持不变。 X_train = vec.fit_transform(X_train.to_dict(orient='record')) # 同样需要对测试数据的特征进行转换。 X_test = vec.transform(X_test.to_dict(orient='record')) # 使用默认配置初始化单一决策树分类器。 dtc = DecisionTreeClassifier() # 使用分割到的训练数据进行模型学习。 dtc.fit(X_train, y_train) # 用训练好的决策树模型对测试特征数据进行预测。 y_predict = dtc.predict(X_test) # 使用随机森林分类器进行集成模型的训练以及预测分析。 rfc = RandomForestClassifier() rfc.fit(X_train, y_train) rfc_y_pred = rfc.predict(X_test) # 使用梯度提升决策树进行集成模型的训练以及预测分析。 gbc = GradientBoostingClassifier() gbc.fit(X_train, y_train) gbc_y_pred = gbc.predict(X_test) print dtc.score(X_test, y_test) # 输出更加详细的分类性能。 print classification_report(y_predict, y_test, target_names = ['died', 'survived']) # 输出随机森林分类器在测试集上的分类准确性,以及更加详细的精确率、召回率、F1指标。 print 'The accuracy of random forest classifier is', rfc.score(X_test, y_test) print classification_report(rfc_y_pred, y_test) # 输出梯度提升决策树在测试集上的分类准确性,以及更加详细的精确率、召回率、F1指标。 print 'The accuracy of gradient tree boosting is', gbc.score(X_test, y_test) print classification_report(gbc_y_pred, y_test)
单一决策树结果:

随机森林,GDBT结果:
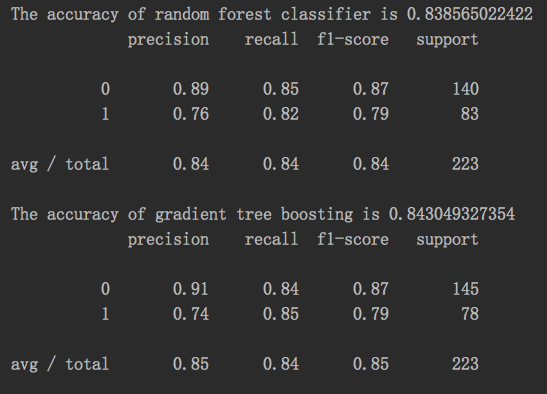
预测性能: GDBT最佳,随机森林次之
一般,工业界为了追求更加强劲的预测性能,使用随机森林作为基线系统(Baseline System)。