一、python 基础语法
python 的解释器在启动时会自动加载一个内建的模块,因此我们在使用 print()、input()等函数时不用导入其他模块文件。
基本语法:
- 每条语句结尾没有分号
- 定义变量不需要前置声明变量的类型(动态语言)
- 定义常量不需要特殊关键字,如 PI=3.14,但是PI可改变如PI=5
- 注释,采用 # 进行单行注释,用""“xxx”""或’’‘xxx’’'多行注释
基本数据类型
-
整型(int):类似于C语言中的 long long类型,取值范围取决于计算机内存大小,甚至一个数可以占满整个内存。
进制表示 十进制 二进制 八进制 十六进制 不同进制表示 整数10 0b1010 0o12 0xa 进制转换 任意整数x bin(x) oct(x) hex(x) 转换成十进制 任意数xxx int(‘xxx’,2) int(‘xxx’,8) int(‘xxx’,16) -
浮点数类型(float)
-
字符串类型(str):用
""或''之间的的字符为一个字符串。该类型支持+拼接、*重复运算。用print()输出,支持转义字符,加参数r屏蔽转义功能。 -
bool 类型:True、False(首字母大写)。非0为True, 0、空字符、空列表、空元组、None都认为是False。
-
None 类型:类似C语言的NULL,表示一个空值。
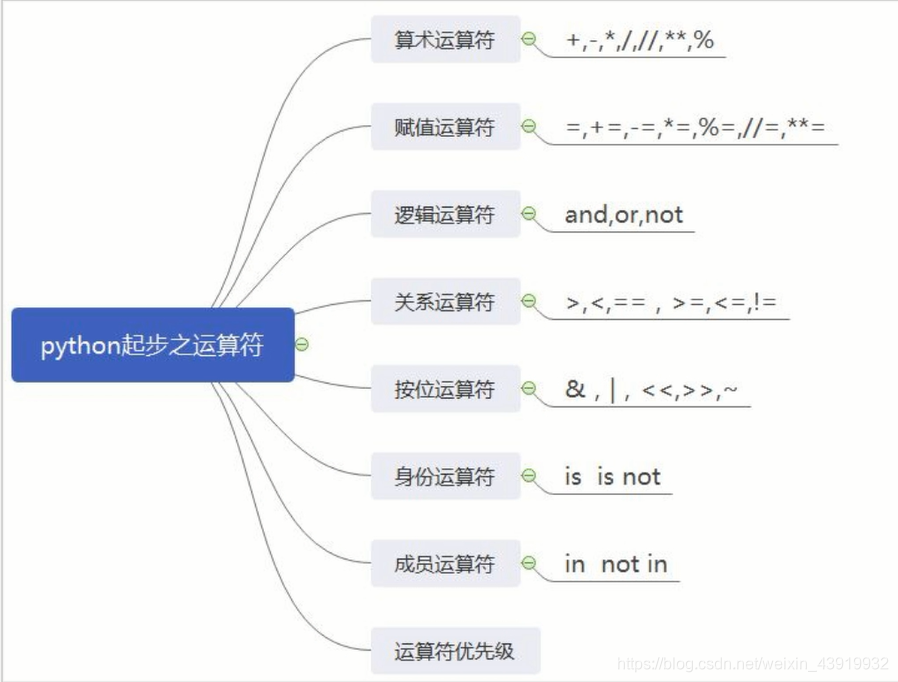
运算符
二、 字符编码
1. 常见的字符编码
- ASCII 码:单字节编码
- MBCS 码:(2字节编码类),规定如果第一个字节是 x80 以下,则任然使用ASCII码;反之,则使用两个字节表示一个字符。如windows的ANSI码格式
- Unicode 码:所有字符的字符集(UCS-2 两个字节表示一个字符、UCS-4四个字节表示一个字符,常用USC-2),UCS(Unicode Character Set)仅仅是字符对应码位的一张表,具体如何传输和存储有UTF(UCS Transformation Format)负责。
直接使用UCS的码位来保存,这就是UTF-16,由于以前使用ASCII码表示英文字符只需要一个字节,而使用UCS-2需要2个字节,空间消耗过大,于是UTF-8出现了。
- UTF-8 码:一种可变长的编码,它把一个Unicode字符根据不同数字大小编码成1~6个字节。常用的英文字母被编码成1个字节,汉字通常是3个字节,生僻的字符会被编码成4 ~ 6个字节。
另外,在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:所以你看到很多网页的源码上会有类似如下的信息,表示该网页正是用的UTF-8编码。<meta charset="UTF-8"/>
2. 字符编码的声明
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/python
# -*- coding: utf-8 -*-12
- 第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
- 第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
实际上,python只检查#、coding和编码字符串,其它字符串使为了美观加上的。其中UTF-8也可以写成u8 。另外需要注意的是,声明的编码需要与文件实际保存的编码一致,否则可能会出现代码解析异常。
bytes 类型
Python bytes 类型(由字节表示字符串)。bytes() 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
字节串(bytes)和字符串(string)的对比:
- 字符串由若干个字符组成,以字符为单位进行操作;bytes由若干个字节组成,以字节为单位进行操作。
- bytes和字符串除了操作的数据单元不同之外,它们支持的所有方法都基本相同。
- bytes和字符串都是不可变序列,不能随意增加和删除数据。
bytes 只负责以字节序列的形式(二进制形式)来存储数据,至于这些数据到底表示什么内容(字符串、数字、图片、音频等),完全由程序的解析方式决定。如果采用合适的字符编码方式(字符集),bytes可以恢复成字符串;反之亦然,字符串也可以转换成字节串。bytes 只是简单地记录内存中的原始数据。
bytes 类型的数据非常适合在互联网上传输,可以用于网络通信编程,如果字符串想要在网络上传输就必须先转换成bytes类型;bytes 也可以用来存储图片、音频、视频等二进制格式的文件。
字符串和 bytes 存在着千丝万缕的联系,我们可以通过字符串来创建 bytes 对象,或者说将字符串转换成 bytes 对象。有以下三种方法可以达到这个目的:
- 如果字符串的内容都是 ASCII 字符,那么直接在字符串前面添加
b前缀就可以转换成 bytes。 - bytes 是一个类,调用它的构造方法,也就是 bytes(),可以将字符串按照指定的字符集转换成 bytes;如果不指定字符集,那么默认采用 UTF-8。
- 字符串本身有一个 encode() 方法,该方法专门用来将字符串按照指定的字符集转换成对应的字节串;如果不指定字符集,那么默认采用 UTF-8。
以下是 bytes() 的语法:
class bytes([source[, encoding[, errors]]])
参数
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
bytes 类型实例
# 以下模拟交互界面
# 使用 b 前缀
>>> btr=b"abc"
>>> type(btr) #查看btr类型
<class 'bytes'>
>>> btr
b'abc'
# 使用 bytes()函数
>>> a = bytes([1,2,3,4])
>>> a
b'x01x02x03x04'
>>> type(a)
<class 'bytes'>
# class bytes([source[, encoding[, errors]]])
>>> b = bytes('hello','ascii')
>>> b
b'hello'
>>> type(b)
<class 'bytes'>
# 使用 encode()转码 decode()解码
>>> "我爱学习".encode("utf-8")
b'xe6x88x91xe7x88xb1xe5xadxa6xe4xb9xa0'
>>>b'xe6x88x91xe7x88xb1xe5xadxa6xe4xb9xa0'.decode("UTF-8")
'我爱学习'
# gbk双字节编码,包含全部中文字符
>>> str = "我爱学习".encode("gbk")
>>> str
b'xcexd2xb0xaexd1xa7xcfxb0'
>>> str.decode("gbk")
'我爱学习'
查看字符对应的Unicode码(Ascii码)
# 以下模拟交互界面
# 使用 ord() 查看字符编码(Ascii或Unicode)
# chr()用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符
# unichr(),与chr()函数功能基本一样, 只不过是返回 unicode 的字符
>>> ord("我")
25105
>>> chr(25105)
'我'
# 查看当前所采用的编码标椎
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
与编码相关的方法:
import sys
import locale
def p(f):
print('%s.%s(): %s' % (f.__module__, f.__name__, f()) )
# 返回当前系统所使用的默认字符编码
p(sys.getdefaultencoding)
# 返回用于转换Unicode文件名至系统文件名所使用的编码
p(sys.getfilesystemencoding)
# 获取默认的区域设置并返回元祖(语言, 编码)
p(locale.getdefaultlocale)
# 返回用户设定的文本数据编码
# 文档提到this function only returns a guess
p(locale.getpreferredencoding)
# xbaxba是'汉'的GBK编码
# mbcs是不推荐使用的编码,这里仅作测试表明为什么不应该用
print(r"'xbaxba'.decode('mbcs'):", repr('xbaxba'.decode('mbcs')) )
#Windows上的结果(区域设置为中文(简体, 中国))
sys.getdefaultencoding(): utf-8
sys.getfilesystemencoding(): utf-8
locale.getdefaultlocale(): ('zh_CN', 'cp936')
locale.getpreferredencoding(): cp936'
编码部分参考博客:Python字符编码详解