基于AI专用的APiM架构,无需外部缓存的模块化深度神经网络学习加速器,用于高性能边缘计算领域,可作为基于视觉的深度学习运算和AI算法加速。外形小巧,极低功耗,拥有着强劲算力,配套完整易用的模型训练工具、网络训练模型实例,搭配专业硬件平台,可快速应用于人工智能行业中。

5.6Tops强劲算力
NCC S1基于AI嵌入式神经网络处理器(NPU),拥有28000个并行神经计算核,支持芯片上并行与原位计算,峰值运算能力高达5.6Tops,是市面上其他方案的数十倍。其强劲的算力,能进行复杂的高密度计算,适用于高性能边缘计算领域。

AI处理架构APiM
采用AI专用的MPE矩阵引擎和APiM(AI processing in Memory,存储中的AI处理)架构,以革命性的方式处理AI,一次升级网络预加载,无需指令、总线,无需外部DDR缓存,大量数据可直接输入/输出硅片,从而大大提高了AI的处理速度,降低处理能耗。

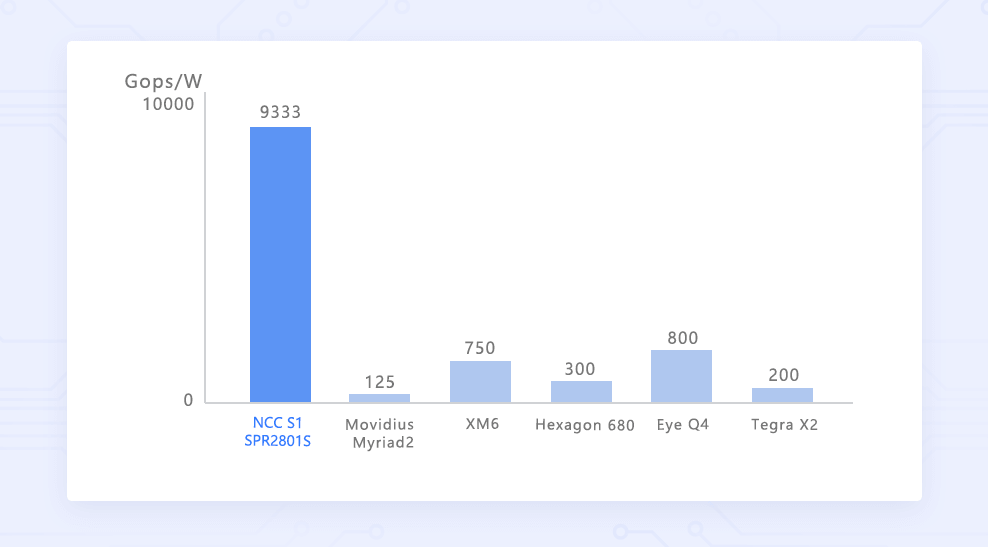
9.3 Tops/W超高效能
NCC S1神经网络计算卡的核心采用28nm工艺制程,在2.8 Tops算力时功率仅300mW,效率能耗比高达为9.3 Tops/W,在拥有超强的算力同时保持了极低的能耗,让其应用在终端设备的边缘计算领域中极具优势。
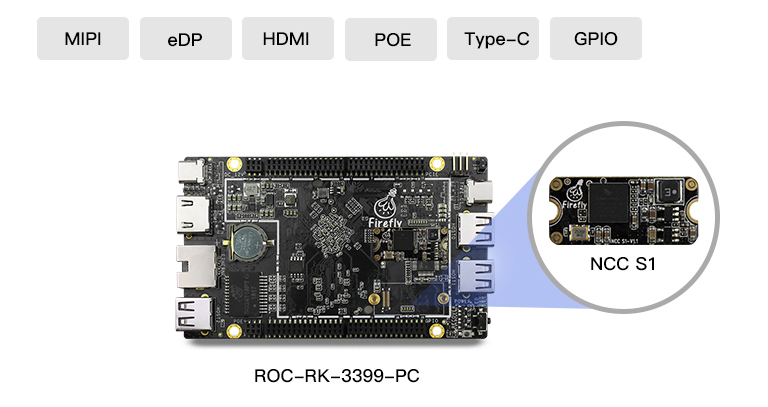
高性能硬件平台
NCC S1神经网络计算卡可搭配ROC-RK3399-PC开源主板,配置高性能RK3399六核处理器,拥有丰富的硬件接口,可快速集成边缘计算的硬件平台,搭建产品原型,加速AI产品的项目进程。
配套模型训练工具
提供基于PyTorch完整易用的模型训练工具PLAI(People Learn AI), 可在Windows 10与Ubuntu 16.04系统上开发,更简单快捷地添加自定义网络模型,大大降低了使用AI的技术门槛,让更多人能更容易打开AI的大门。

提供网络训练模型
支持GNet1,GNet18和GNetfc三种网络训练模型实例,后续会持续增加网络实例,轻松在设备上测试大量深度学习应用。

进入Firefly官网,可了解NCC S1神经网络计算卡更多内容。