在日常的工作中,我们经常需要进行一些二进制文件或协议的读写操作,用C#解析二进制文件常常是一件比较麻烦且容易出错的工作,本文介绍了一种在C#中实现快速读写二进制文件通用的方法。
以一个解析Mp3 ID3V1标签头为例,ID3V1标签保存在MP3文件尾的最后128个字节用来存放ID3信息,其格式具体如下表:
|
字节 |
长度 (字节) |
说明 |
|
1-3 |
3 |
存放"TAG"字符,表示ID3 V1.0标准。 |
|
4-33 |
30 |
歌名 |
|
34-63 |
30 |
作者 |
|
64-93 |
30 |
专辑名 |
|
94-97 |
4 |
年份 |
|
98-127 |
30 |
附注 |
|
128 |
1 |
MP3音乐类别,共147种。 |
如果要用C/C++语言来解析这个标签头,一般需要经过如下两个步骤:
首先定义标签头数据结构,
typedefstructtagID3V1
{
char Header[3]; /*标签头必须是"TAG"否则认为没有标签*/
char Title[30]; /*标题*/
char Artist[30]; /*作者*/
char Album[30]; /*专集*/
char Year[4]; /*出品年代*/
char Comment[28]; /*备注*/
char reserve; /*保留*/
char track; /*音轨*/
char Genre; /*类型*/
}ID3V1;C/C++语言定义的数据结构非常清晰的指明了各字段所占用的内存和偏移位置,由于C语言定义的数据结构是和内存中的偏移位置直接对应上的,因此,定义后数据结构后,从文件中获取数据到数据结构是非常简单的事情。PS:这是个c++的版本,由于只是个示例代码,去掉了异常处理相关流程,C语言版本类似,这里就不举例了。
void main()
{
ifstream file("r:\\te2st.mp3");
ID3V1 id3v1 = {0}; //存放读取的mp3 ID3V1信息
file.seekg((int)(-1*sizeof(id3v1)), ios::end);
file.read((char*)(&id3v1), sizeof(id3v1));
}从这段代码中可以看到,只需要通过内存拷贝函数就可以将数据从数据一口气复制到数据结构中来,无需手动一个个成员赋值,非常简洁。
现在我们再来看看如何用C#实现这一功能,一般来讲,首先也是定义一个数据结构:
class ID3V1
{
publicstring Header { get; set; }
publicstring Title { get; set; }
publicstring Artist { get; set; }
publicstring Album { get; set; }
publicstring Year { get; set; }
publicstring Comment { get; set; }
publicbyte Reserve { get; set; }
publicbyte Track { get; set; }
publicbyte Genre { get; set; }
}和C语言相比,C#定义的数据结构相对较为抽象,从数据结构中看不到和ID3V1的各字段长度的对应关系,因此只能一个个字段的手动复制,解析函数实现如下:
public static ID3V1 ReadFormFile(string file)
{
var tagLength = 128;
var id3v1 = newID3V1();
byte[] data = newbyte[tagLength];
using (var stream = File.OpenRead(file))
{
stream.Seek(-1 * tagLength, SeekOrigin.End);
stream.Read(data, 0, data.Length);
}
var encoding = Encoding.Default;
id3v1.Header = encoding.GetString(data, 0, 3);
id3v1.Title = encoding.GetString(data, 3, 30).TrimEnd('\0');
id3v1.Artist = encoding.GetString(data, 33, 30).TrimEnd('\0');
id3v1.Album = encoding.GetString(data, 63, 30).TrimEnd('\0');
id3v1.Year = encoding.GetString(data, 93, 4);
id3v1.Comment = encoding.GetString(data, 97, 28).TrimEnd('\0');
id3v1.Reserve = data[125];
id3v1.Track = data[126];
id3v1.Genre = data[127];
return id3v1;
}从上面代码可以看出,C#把其数据格式的解析放在解析函数里面来了,比起C语言来说复杂的多,主要体现在如下地方:
-
C#定义的数据结构中无法获取结构体大小,需要定义变量保存,而C语言可以通过sizeof获取,具有通用性。
-
C#的数据结构中看不到每个字段的长度的偏移位置,每个字段的长度和偏移位置都需要定义变量保存,而C语言的数据结构的长度非常明确,偏移位置直接由编译器推算。
-
C#无法从文件流中读出来的字节编码和各个字段的具体类型互相转换,读写时需要每个字段进行单独编码赋值,一旦需要解析的字段较多很容易出错和漏掉,并且没有通用性,而C语言直接通过memcopy、read & write等函数可以一行代码搞定,具有通用性。
有鉴于以上几点,导致C#读写二进制文件没有通用性,成了非常麻烦的一件事情。那么有没有办法可以让C#也想C语言那样使用一种通用的方式快速读写二进制文件呢?
经常通过P/Invoke调用Win32 API的码农们可能知道,有的时候,win32 api的参数或返回值是一个数据结构,此时则需要我们在C#定义一个等价的数据结构,也就是说,C#中也是可以定义出像C语言那样对成员在内存中的布局进行精确控制的,通过这种方式,也可以实现类似C语言那样读写二进制文件的通用算法。
关于C#控制成员布局的方法,请参看MSDN文章:LayoutKind枚举和MarshalAsAttribute类相关内容,如下两篇博客StructLayout特性和C# struct实例字段的内存布局介绍的也比较详细,我这里就不累述了。不过,就算有了相关知识,把C#对象做到像C对象那样精确控制还是一件比较麻烦的事情,很容易出错,我们可以借助一个P/Invoke Interop Assistant的工具把C语言结构自动转换为C#结构,然后再在工具生成的数据结构基础上润色下就快多了。
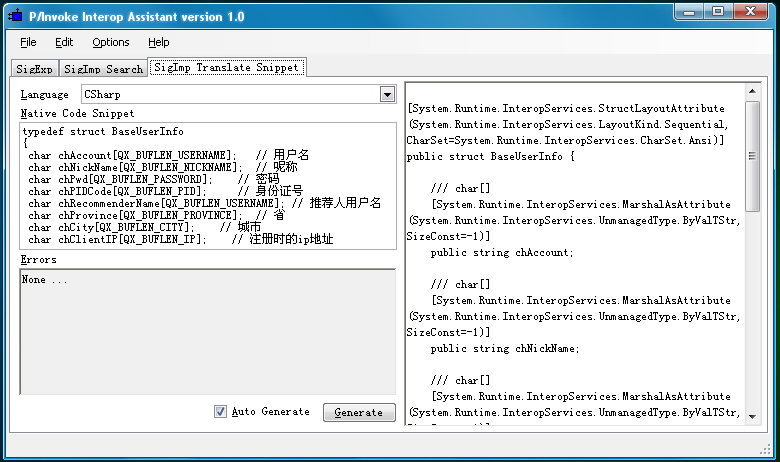
还是拿前面的ID3V1 Tag为例,首先我们通过P/Invoke Interop Assistant把C语言定义的结构转换为C#的结构,生成的数据结构如下:
[StructLayoutAttribute(LayoutKind.Sequential, CharSet = CharSet.Ansi)]
publicclassID3V1
{
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 3)]
publicstring Header;
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 30)]
publicstring Title;
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 30)]
publicstring Artist;
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 30)]
publicstring Album;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 4)]
publicchar[] Year;
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 28)]
publicstring Comment;
publicbyte Reserve;
publicbyte Track;
publicbyte Genre;
}微软官方的工具还是比较厉害的,像位域之类的也能转换,但还不算完美,存在如下几个需要改进的地方:
-
有的字符串不是以'\0'结尾的,像ID3V1的Header和Year字段,这个时候翻译为string的时候会导致最后一位信息丢掉,但没有让人手动修改的地方。
-
没有把字段封装为属性。
-
没有去掉名字空间System.Runtime.InteropServices的前缀,生成的代码过长。
因此,基于这个生成的结构,还需要手动修改一下。最后为如下形式:
[StructLayoutAttribute(LayoutKind.Sequential, CharSet = CharSet.Ansi)]
publicclassID3V1
{
[MarshalAs(UnmanagedType.ByValArray, SizeConst = 3)]
char[] header = "TAG".ToCharArray();
publicstring Header
{
get { returnnewstring(header); }
set { header = value.ToCharArray(); }
}
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 30)]
privatestring title;
publicstring Title
{
get { return title; }
set { title = value; }
}
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 30)]
privatestring artist;
publicstring Artist
{
get { return artist; }
set { artist = value; }
}
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 30)]
privatestring album;
publicstring Album
{
get { return album; }
set { album = value; }
}
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 4)]
privatechar[] year;
publicchar[] Year
{
get { return year; }
set { year = value; }
}
[MarshalAsAttribute(UnmanagedType.ByValTStr, SizeConst = 28)]
privatestring comment;
publicstring Comment
{
get { return comment; }
set { comment = value; }
}
publicbyte Reserve { get; set; }
publicbyte Track { get; set; }
publicbyte Genre { get; set; }
}有了这个带有和二进制格式一一对应的数据结构后,下一步就是需要写一个类似memcopy的通用函数实现读写操作。.net提供了一个Marshal类可以实现类似memcopy的内存复制功能,我利用它写了一个字节数组到object的互像转换函数,并基于它们提供了两个BinaryReader的扩展函数,以方便使用。
staticclassMarshalExtend
{
publicstatic T GetObject<T>(byte[] data, int size)
{
Contract.Assume(size == Marshal.SizeOf(typeof(T)));
IntPtr pnt = Marshal.AllocHGlobal(size);
try
{
// Copy the array to unmanaged memory.
Marshal.Copy(data, 0, pnt, size);
return (T)Marshal.PtrToStructure(pnt, typeof(T));
}
finally
{
// Free the unmanaged memory.
Marshal.FreeHGlobal(pnt);
}
}
publicstaticbyte[] GetData(object obj)
{
var size = Marshal.SizeOf(obj.GetType());
var data = newbyte[size];
IntPtr pnt = Marshal.AllocHGlobal(size);
try
{
Marshal.StructureToPtr(obj, pnt, true);
// Copy the array to unmanaged memory.
Marshal.Copy(pnt, data, 0, size);
return data;
}
finally
{
// Free the unmanaged memory.
Marshal.FreeHGlobal(pnt);
}
}
publicstatic T ReadMarshal<T>(this System.IO.BinaryReader reader)
{
var length = Marshal.SizeOf(typeof(T));
var data = reader.ReadBytes(length);
return GetObject<T>(data, data.Length);
}
publicstaticvoid WriteMarshal<T>(this System.IO.BinaryWriter writer, T obj)
{
writer.Write(GetData(obj));
}
}这个类和前面的ID3V1数据结构没有任何联系,也就是说,它是一个通用函数,只要定义好了数据结构,就可以直接用它来实现通用的读写操作了:
using (var reader = newBinaryReader(File.OpenRead(@"r:\test.mp3")))
{
reader.BaseStream.Seek(-1 * Marshal.SizeOf(typeof(ID3V1)), SeekOrigin.End);
var id3Tag = reader.ReadMarshal<ID3V1>();
}PS:
-
这种方式具有一定的通用性,并且非常简洁,我常常用这种方法实现二进制文件和协议的解析,但估计效率不高,没有具体测试过。平时也只是拿它来用于客户端这种对性能要求不高的地方,没遇到啥海量数据处理的场合。如果谁有这方面的测试,欢迎共享下性能数据,应该还是有些性能提升的空间的。
-
读写二进制文件除了用BinaryReader直接读写文件外,内存映射文件也是一直非常有效的方式。这里附两篇相关文章:使用内存映射文件实现进程通讯、[译].NET 4 中玩耍内存映射文件,有兴趣的朋友可以了解下。
-
如果遇到BigEndian的数字,可以使用我以前的文章在C#中实现BigEndian的数字中定义的数据结构。
转:http://www.cnblogs.com/TianFang/archive/2012/10/06/2712987.html