1 简介
在线性分类一节中,在给出图像的情况下,是使用(s=W x)来计算不同视觉类别的评分,其中(W)是一个矩阵,(x)是一个输入列向量,它包含了图像的全部像素数据。
在使用数据库CIFAR-10的案例中,(x)是一个([3072 imes 1])的列向量,(W)是一个([10 imes 3072])的矩阵,所以输出的评分是一个包含10个分类评分的向量。
神经网络算法则不同,它的计算公式是(s=W_{2} max left(0, W_{1} x ight))。
其中(W_{1})的含义是这样的:举个例子来说,它可以是一个[100x3072]的矩阵,其作用是将图像转化为一个100维的过渡向量。
函数(max (0,-))是非线性的,它会作用到每个元素。这个非线性函数有多种选择。
矩阵(W_{2})的尺寸是[10x100],因此将得到10个数字,这10个数字可以解释为是分类的评分。
注意非线性函数在计算上是至关重要的,如果略去这一步,那么两个矩阵将会合二为一,对于分类的评分计算将重新变成关于输入的线性函数。
参数(W_{1}, W_{2})将通过随机梯度下降来学习到,他们的梯度在反向传播过程中,通过链式法则来求导计算得出。
一个三层的神经网络可以类比地看做(s=W_{3} max left(0, W_{2} max left(0, W_{1} x ight) ight))。
2 单个神经元建模
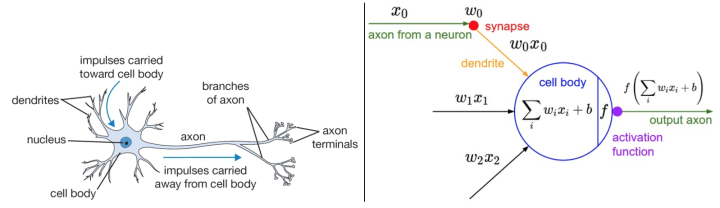
神经网络算法领域最初是被对生物神经系统建模这一目标启发。下面图表的左边展示了一个生物学的神经元,右边展示了一个常用的数学模型。
一个神经元前向传播的实例代码如下:
class Neuron(object):
# ...
def forward(inputs):
""" 假设输入和权重是1-D的numpy数组,偏差是一个数字 """
cell_body_sum = np.sum(inputs * self.weights) + self.bias
firing_rate = 1.0 / (1.0 + math.exp(-cell_body_sum)) # sigmoid激活函数
return firing_rate
注意:这种对于生物神经元的数学建模是非常粗糙的。
3 常用激活函数
3.1 Sigmoid与Tanh
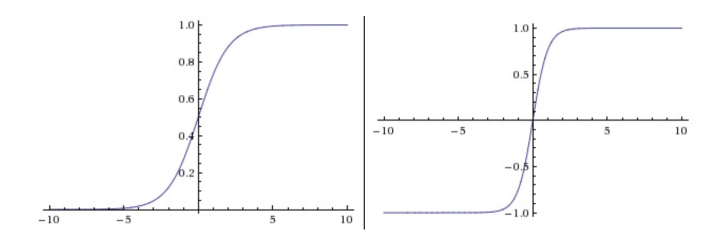
Sigmoid与Tanh非线性函数图像如下所示:
3.1.1 Sigmoid
sigmoid非线性函数的数学公式是(sigma(x)=1 /left(1+e^{-x} ight)),它输入实数值并将其“挤压”到0到1范围内。更具体地说,很大的负数变成0,很大的正数变成1。
然而现在sigmoid函数实际很少使用了,这是因为它有两个主要缺点:
- sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。
- sigmoid函数的输出不是零中心的,这一情况将影响梯度下降的运作。
3.1.2 Tanh
tanh非线性函数将实数值压缩到[-1,1]之间。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。
注意tanh神经元是一个简单放大的sigmoid神经元,具体说来就是:( anh (x)=2 sigma(2 x)-1)。
3.2 ReLU与Leaky ReLU
3.2.1 ReLU
下图中左边是ReLU(校正线性单元:Rectified Linear Unit)激活函数,当x=0时函数值为0。当x>0函数的斜率为1。右边是从 Krizhevsky等的论文中截取的图表,指明使用ReLU比使用tanh的收敛快6倍。
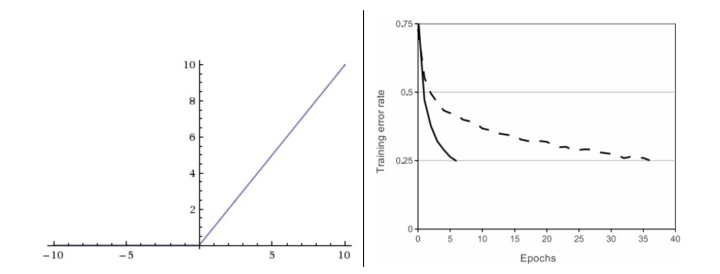
在近些年ReLU变得非常流行。它的函数公式是(f(x)=max (0, x))。
ReLU的优点:
- 相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用。
- sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
ReLU的缺点:
在训练的时候,ReLU单元比较脆弱并且可能“死掉”。
举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。
例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
3.2.2 Leaky ReLU
Leaky ReLU是为解决“ReLU死亡”问题的尝试。
ReLU中当x<0时,函数值为0。而Leaky ReLU则是给出一个很小的负数梯度值,比如0.01。所以其函数公式为(f(x)=1(x<0)(alpha x)+1(x>=0)(x))。其中(alpha)是一个小的常量。
3.3 Maxout
一些其他类型的单元被提了出来,它们对于权重和数据的内积结果不再使用(fleft(w^{T} x+b ight))函数形式。
一个相关的流行选择是Maxout神经元。Maxout是对ReLU和leaky ReLU的一般化归纳,它的函数是:(max left(w_{1}^{T} x+b_{1}, w_{2}^{T} x+b_{2} ight))。ReLU和Leaky ReLU都是这个公式的特殊情况(比如ReLU就是当(w_{1}, b_{1}=0)的时候)。
这样Maxout神经元就拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)。
然而和ReLU对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
4 神经网络结构
4.1 概述
神经网络被建模成神经元的集合,神经元之间以无环图的形式进行连接。也就是说,一些神经元的输出是另一些神经元的输入。在网络中是不允许循环的,因为这样会导致前向传播的无限循环。
对于普通神经网络,最普通的层的类型是全连接层(fully-connected layer)。全连接层中的神经元与其前后两层的神经元是完全成对连接的,但是在同一个全连接层内的神经元之间没有连接。
下面是两个神经网络的图例,都使用的全连接层:
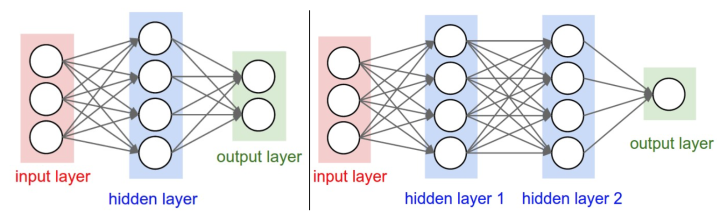
左边是一个2层神经网络,隐层由4个神经元(也可称为单元(unit))组成,输出层由2个神经元组成,输入层是3个神经元。
右边是一个3层神经网络,两个含4个神经元的隐层。
有以下几点需要补充:
(1)当我们说N层神经网络的时候,我们没有把输入层算入。
(2)和神经网络中其他层不同,输出层的神经元一般是不会有激活函数的
(3)用来度量神经网络的尺寸的标准主要有两个:一个是神经元的个数,另一个是参数的个数,用上面图示的两个网络举例:
第一个网络有4+2=6个神经元(输入层不算),[3x4]+[4x2]=20个权重,还有4+2=6个偏置,共26个可学习的参数。
第二个网络有4+4+1=9个神经元,[3x4]+[4x4]+[4x1]=32个权重,4+4+1=9个偏置,共41个可学习的参数。
(4)含有一个隐层的神经网络就能近似任何连续函数。
既然一个隐层就能近似任何函数,那为什么还要构建更多层来将网络做得更深?答案是:虽然一个2层网络在数学理论上能完美地近似所有连续函数,但在实际操作中效果相对较差。
在实践中3层的神经网络会比2层的表现好,然而继续加深(做到4,5,6层)很少有太大帮助。卷积神经网络的情况却不同,在卷积神经网络中,对于一个良好的识别系统来说,深度是一个极端重要的因素(比如数十(以10为量级)个可学习的层)。
4.2 如何设置层的数量和尺寸
在面对一个具体问题的时候该确定网络结构呢?到底是不用隐层呢?还是一个隐层?两个隐层或更多?每个层的尺寸该多大?
首先,要知道当我们增加层的数量和尺寸时,网络的容量上升了。即神经元们可以合作表达许多复杂函数,所以表达函数的空间增加。
例如,如果有一个在二维平面上的二分类问题。我们可以训练3个不同的神经网络,每个网络都只有一个隐层,但是每层的神经元数目不同:
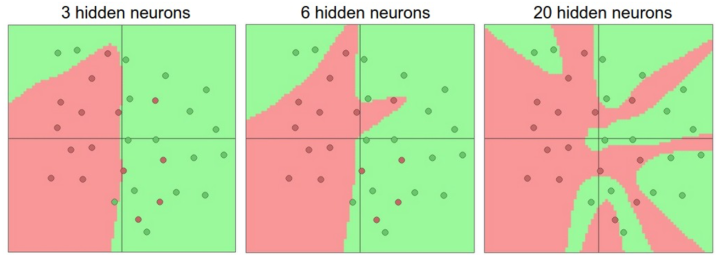
对于上图,更大的神经网络可以表达更复杂的函数。数据是用不同颜色的圆点表示他们的不同类别,决策边界是由训练过的神经网络做出的。
然而对于“有更多神经元的神经网络可以表达更复杂的函数”这个现象来说。这既是优势也是不足,优势是可以分类更复杂的数据,不足是可能造成对训练数据的过拟合。
看起来如果数据不是足够复杂,则似乎小一点的网络更好,因为可以防止过拟合。然而并非如此,防止神经网络的过拟合有很多方法(L2正则化,dropout和输入噪音等)。在实践中,使用这些方法来控制过拟合比减少网络神经元数目要好得多。
不要减少网络神经元数目的主要原因在于小网络更难使用梯度下降等局部方法来进行训练。
虽然小型网络的损失函数的局部极小值更少,也比较容易收敛到这些局部极小值,但是这些最小值一般都很差,损失值很高。相反,大网络拥有更多的局部极小值,但就实际损失值来看,这些局部极小值表现更好,损失更小。
在实际中,你将发现如果训练的是一个小网络,那么最终的损失值将展现出多变性:某些情况下运气好会收敛到一个好的地方,某些情况下就收敛到一个不好的极值。
从另一方面来说,如果你训练一个大的网络,你将发现许多不同的解决方法,但是最终损失值的差异将会小很多。这就是说,所有的解决办法都差不多,而且对于随机初始化参数好坏的依赖也会小很多。
最后拿正则化来说,其强度是控制神经网络过拟合的好方法。看下图结果:
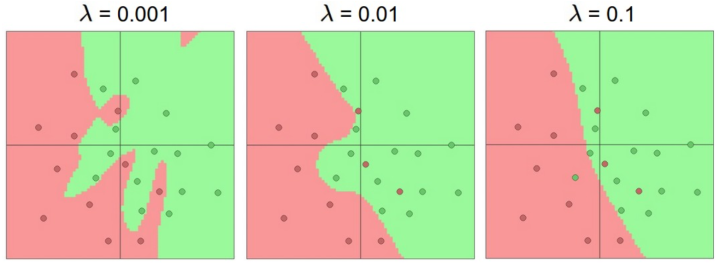
上图中每个神经网络都有20个隐层神经元,但是随着正则化强度增加,它的决策边界变得更加平滑。