深度学习的过程:
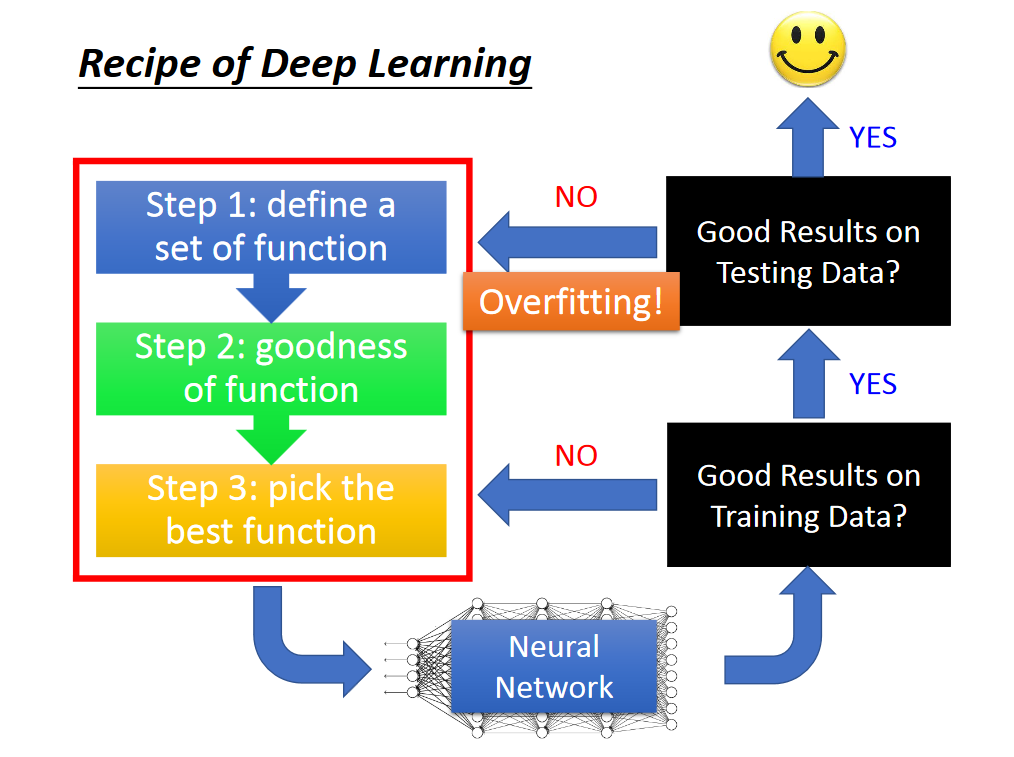
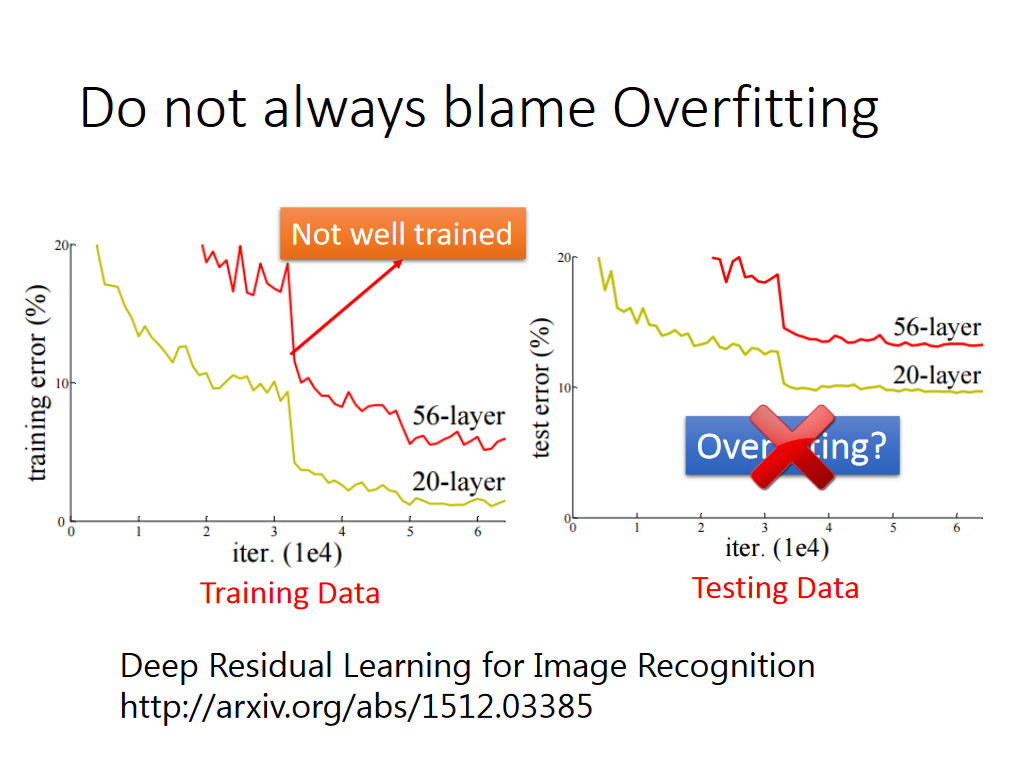
通过上述的过程,我们知道,我们训练好的model需要先在training set上测试性能,并且准确率很可能不是100%。有时候我们发现我们的model在testing set上表现不好时,不一定就是over fitting,也可能是training set 上没有train好。
针对是在training set 或者是 testing set上性能不好,有不同的解决方式:
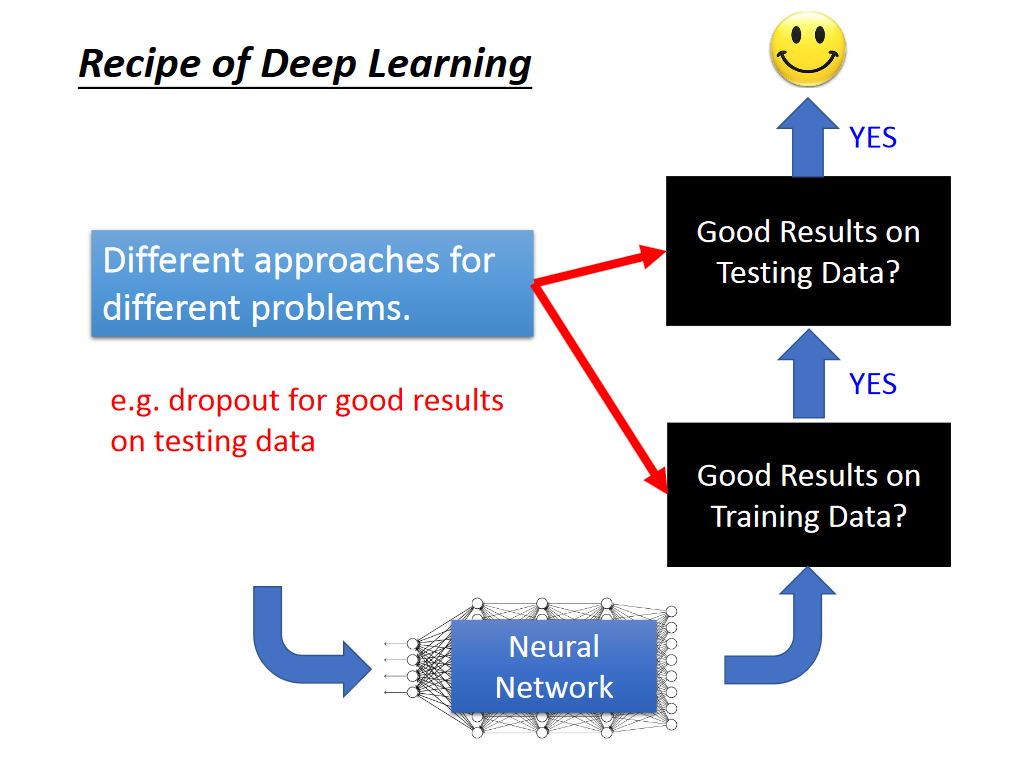
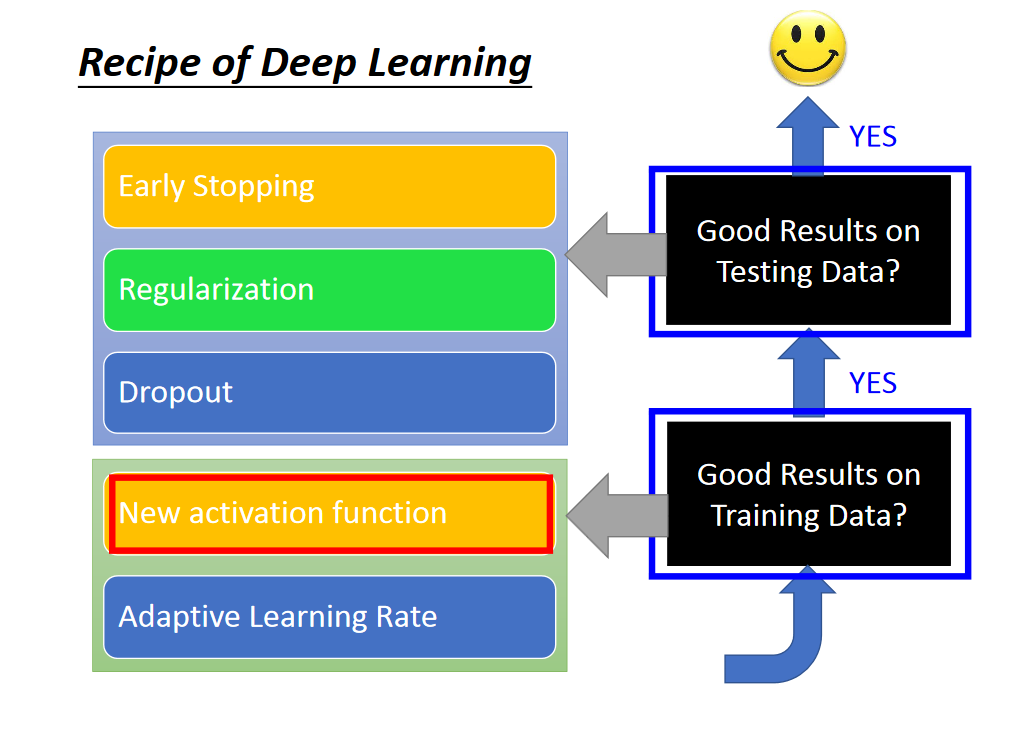
在training set上performance不好
New activation function
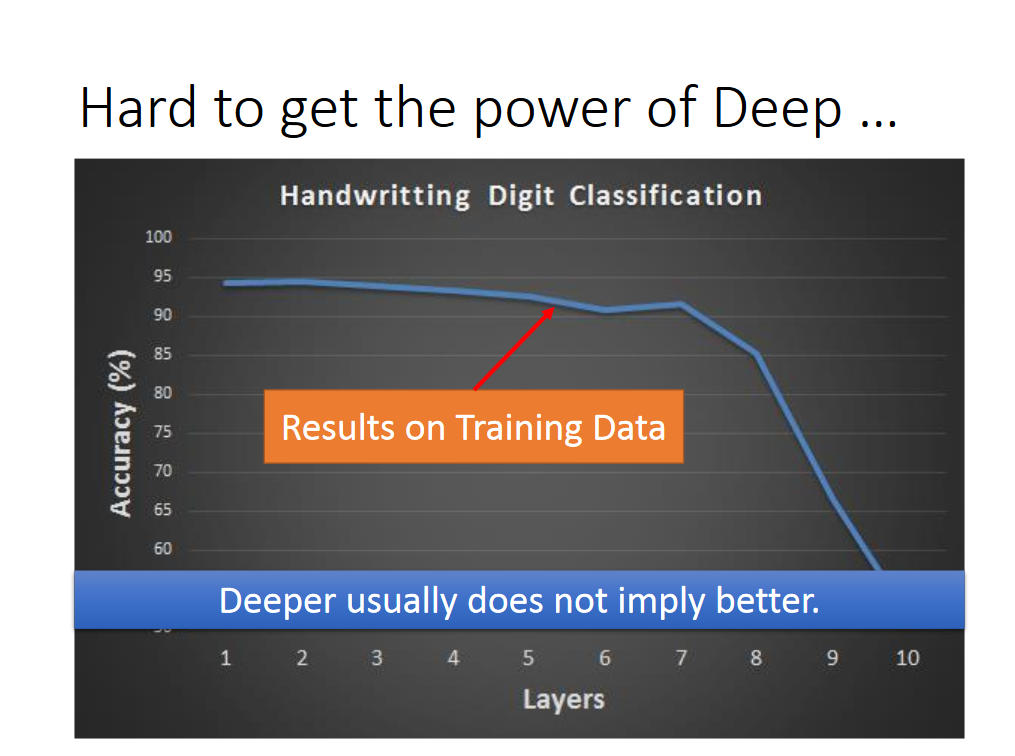
通常说:对于深度学习,并不是深度越深就意味着性能更好
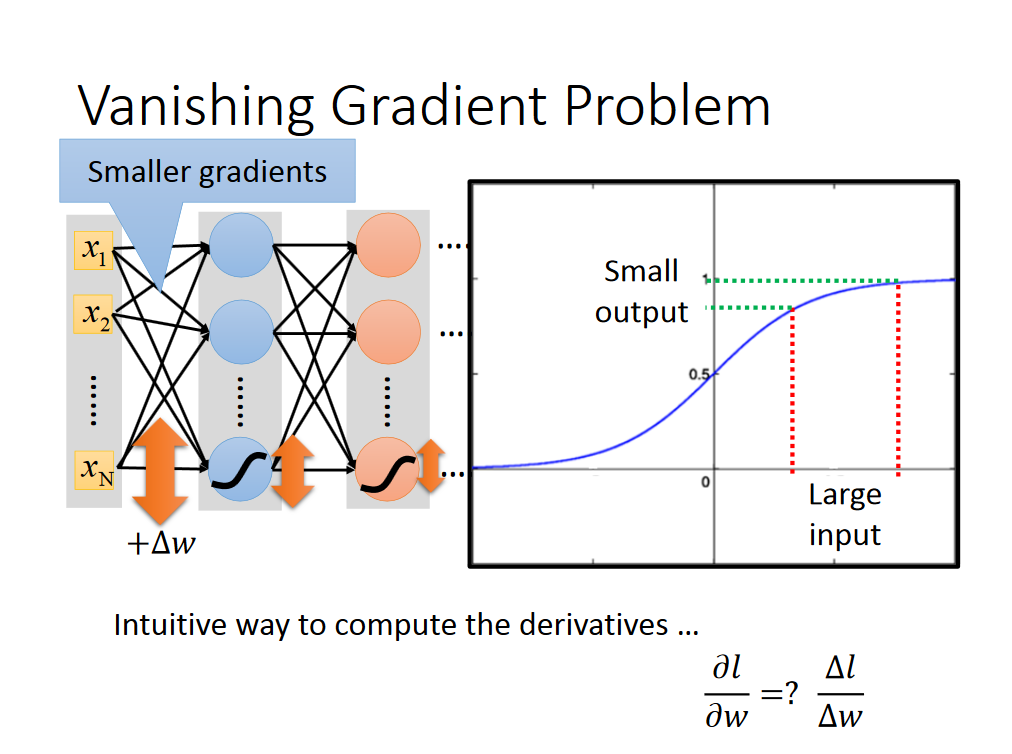
这是因为存在着梯度消失的问题,因为对于sigmoid函数来说,很大的输入对应着很小的输出:

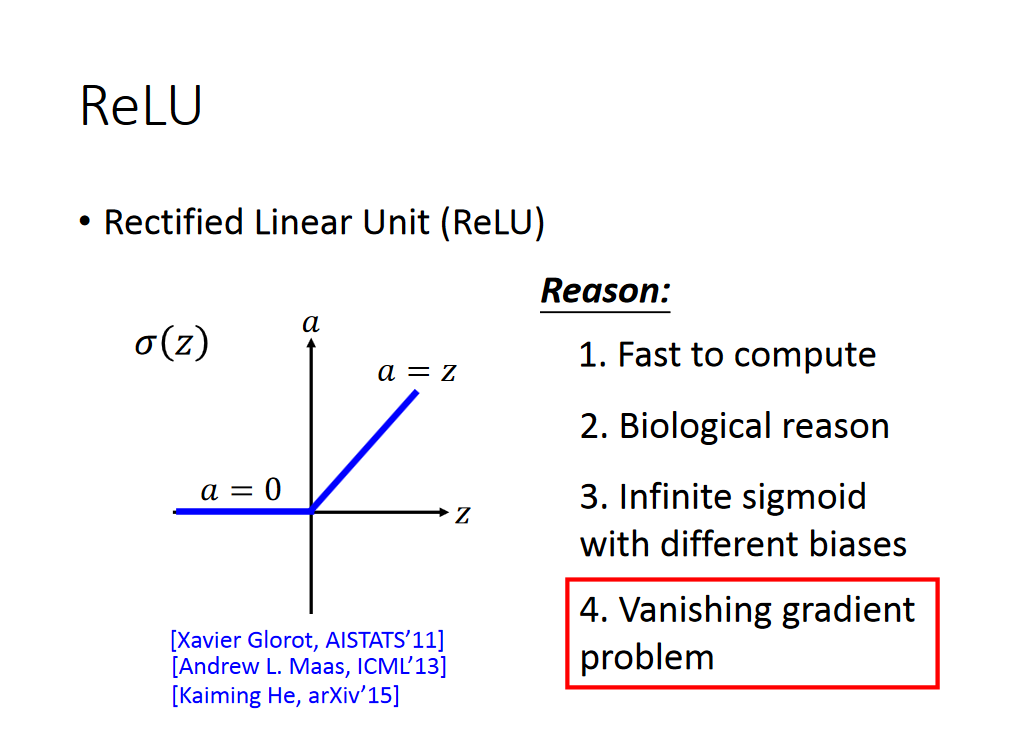
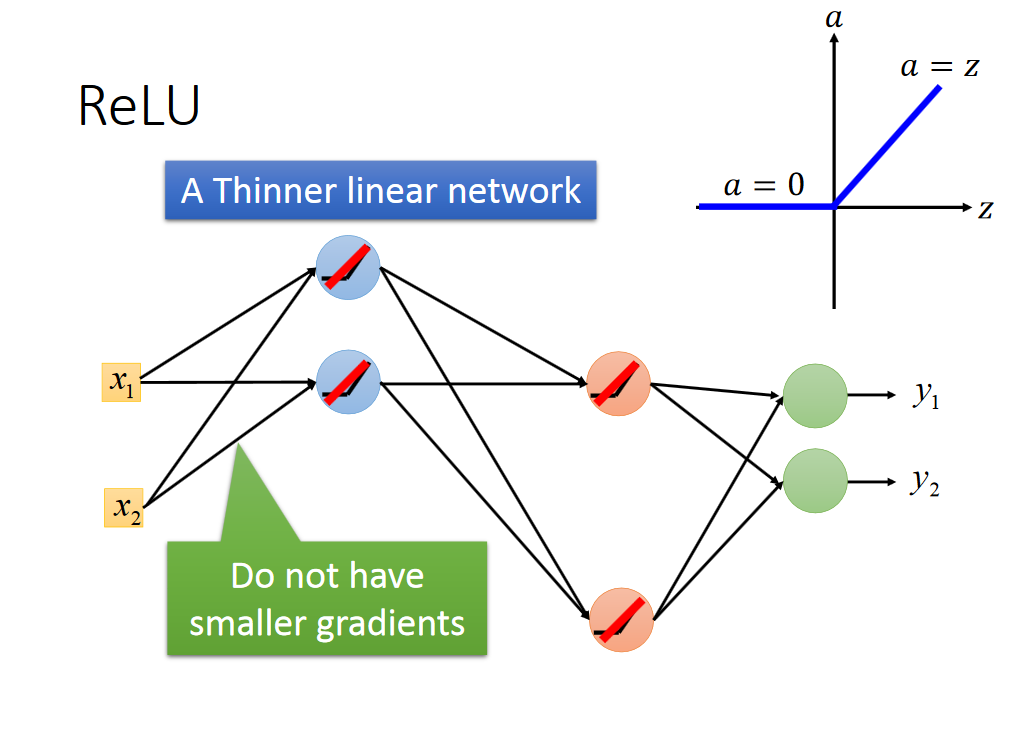
其中一个解决办法是替换activation function,改用Relu
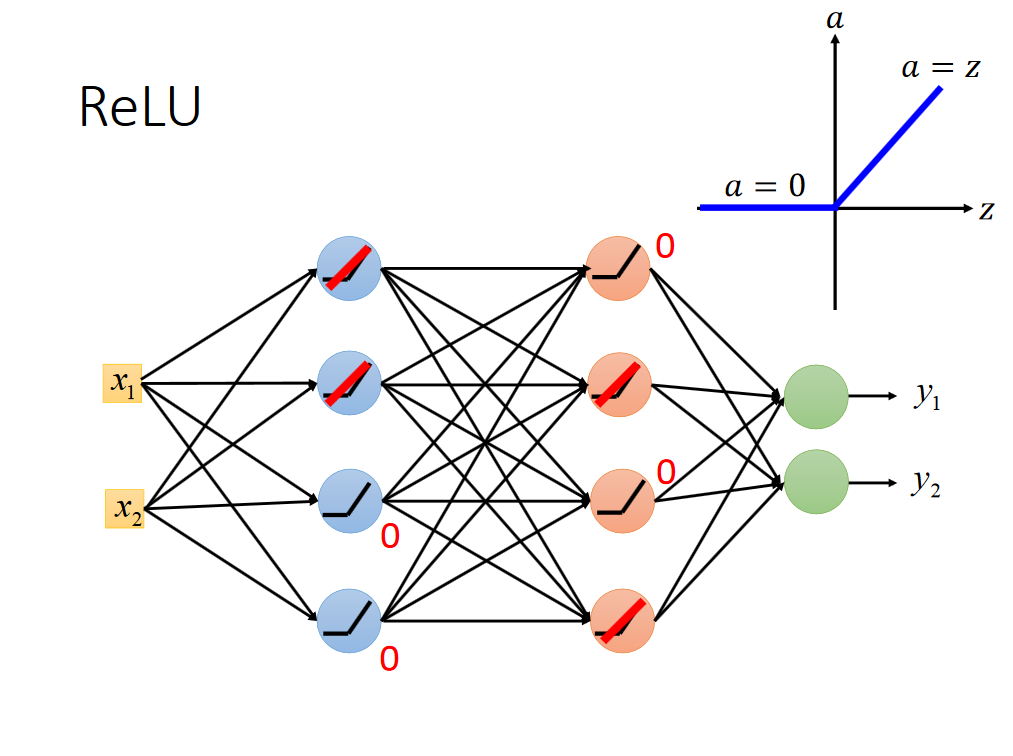
简化成了一个更简单的线性网络
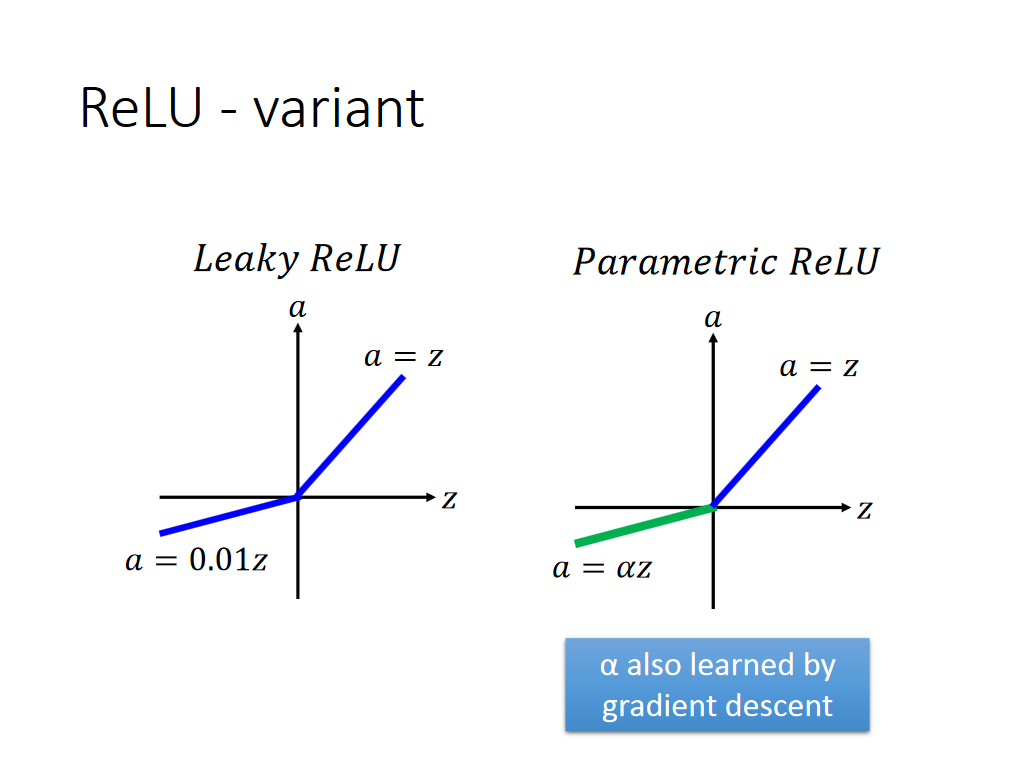
激活函数Relu还有另外两种变形,如下所示
Relu也可以看做是Maxout函数的一个特例,解释如下:
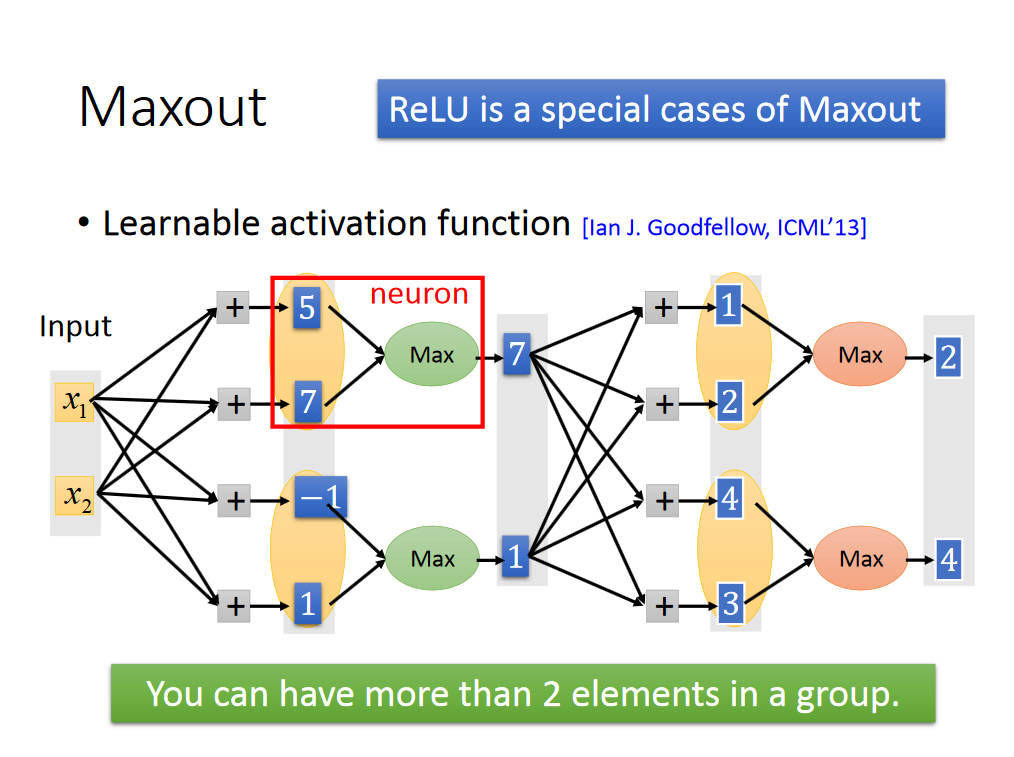
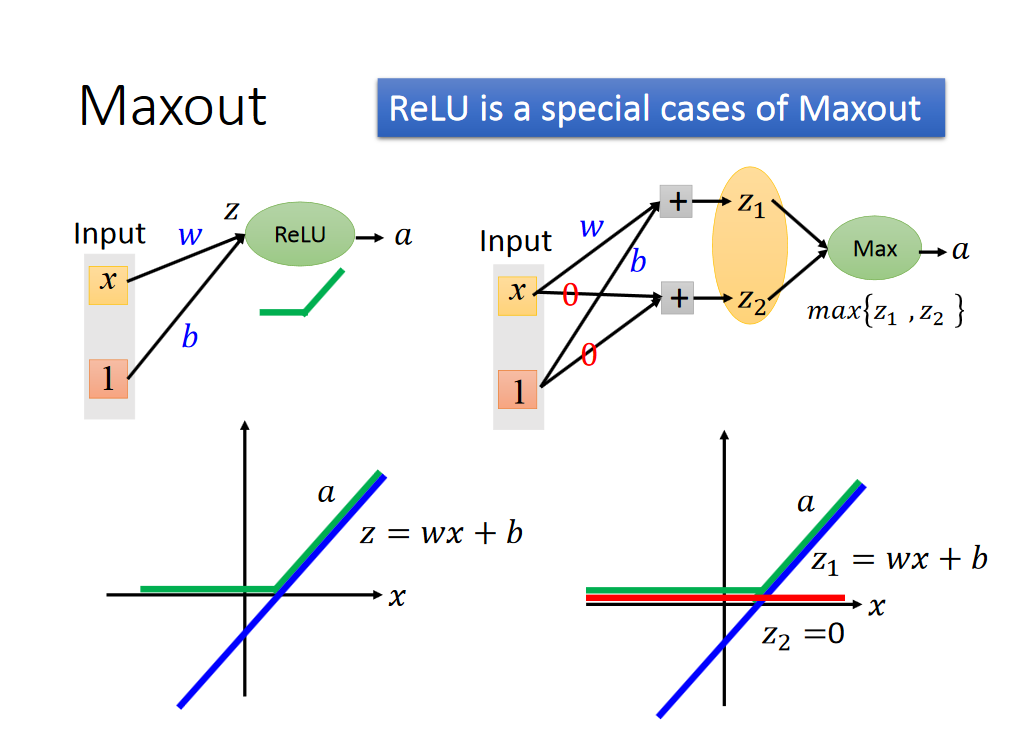
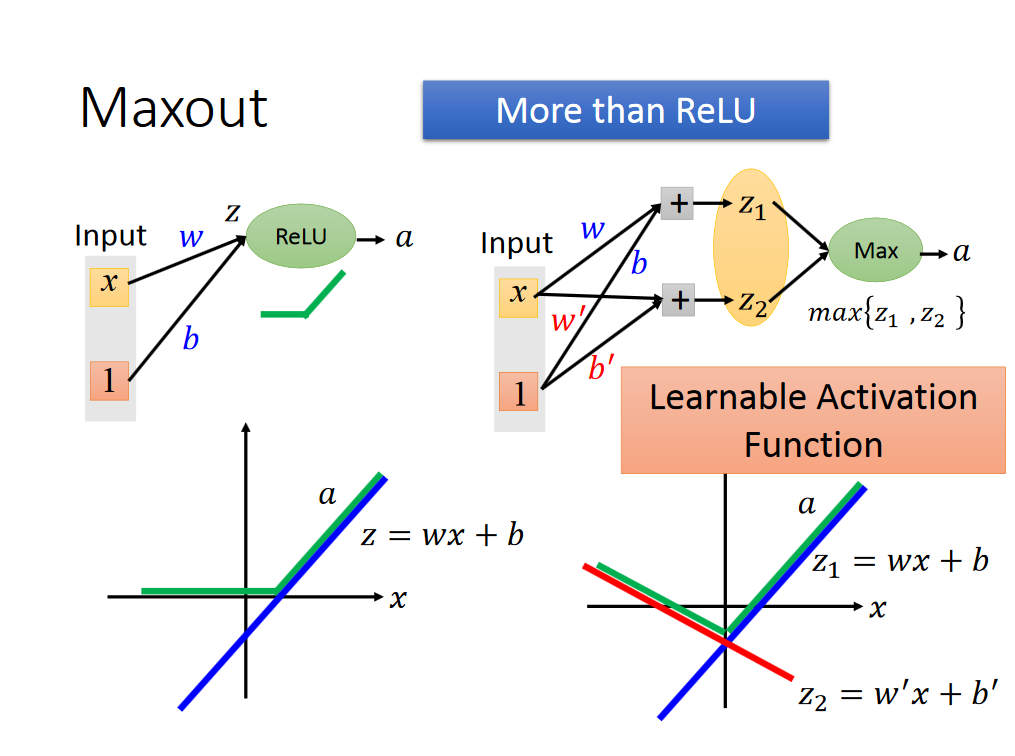
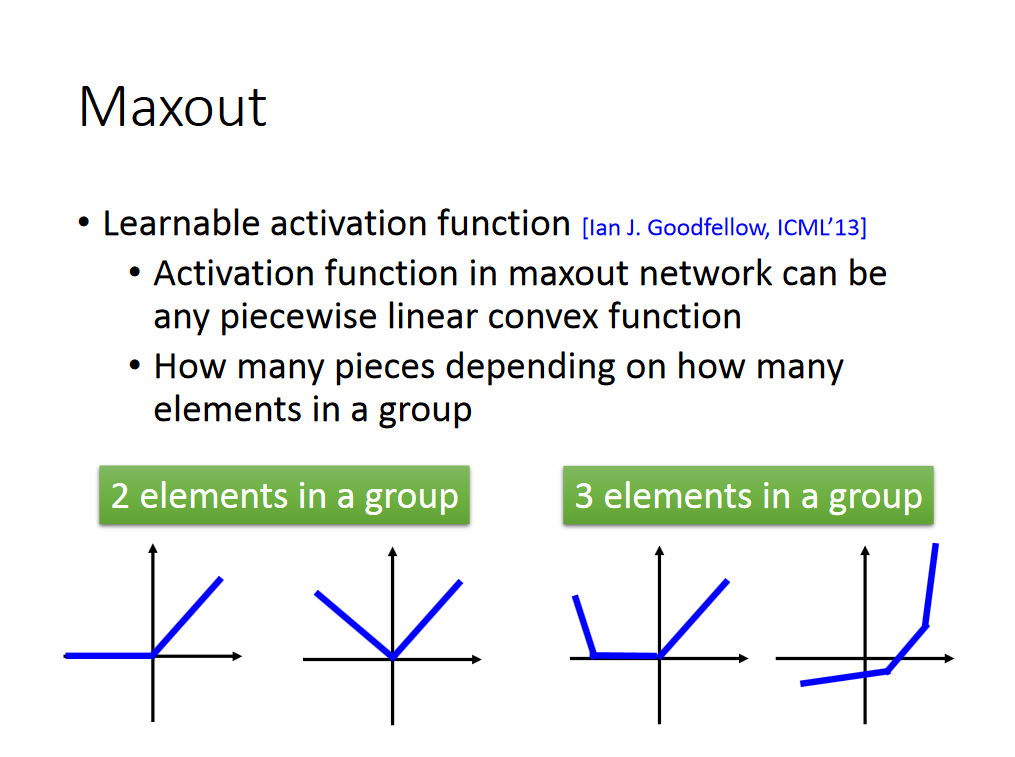
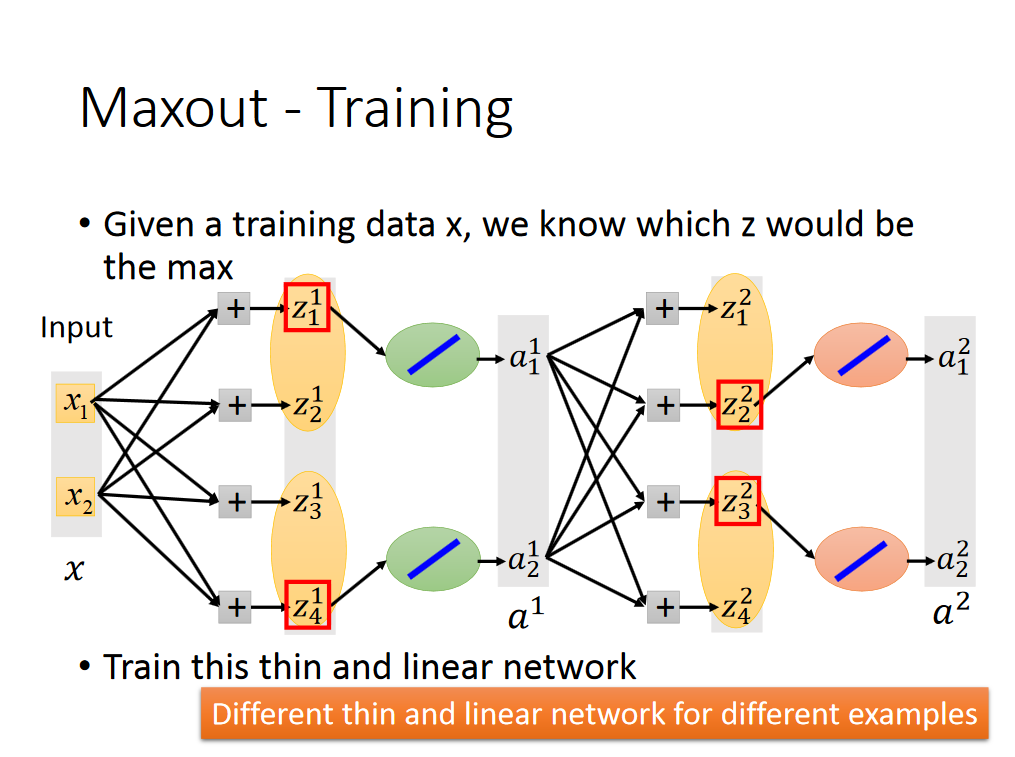
写到这里,可能会有人问,我们选出每组的最大值,那么怎么训练数据呢,应该不可以使用梯度下降法了吧,其实还是可以的,具体train的方法如下:
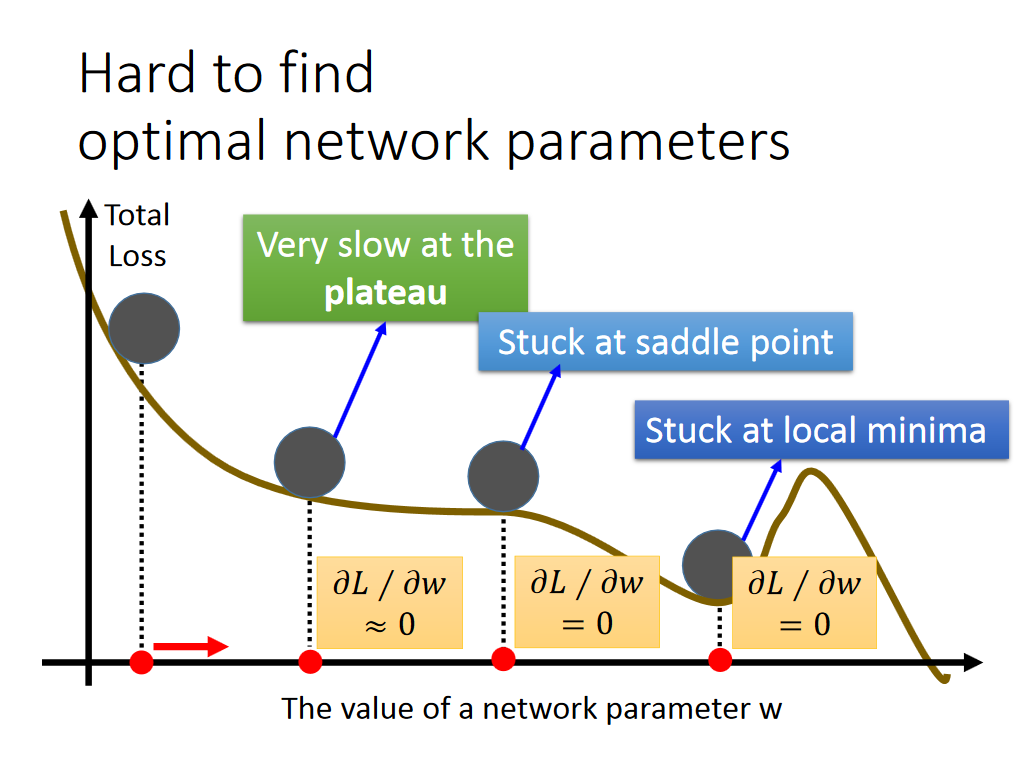
Adaptive Learning Rate
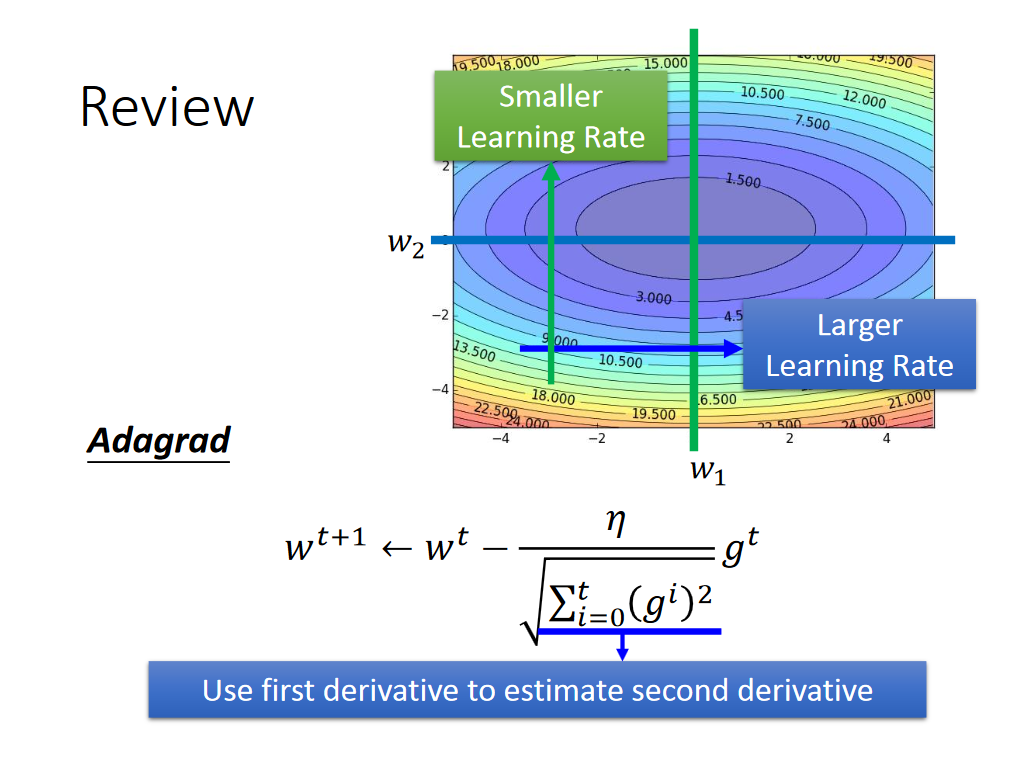
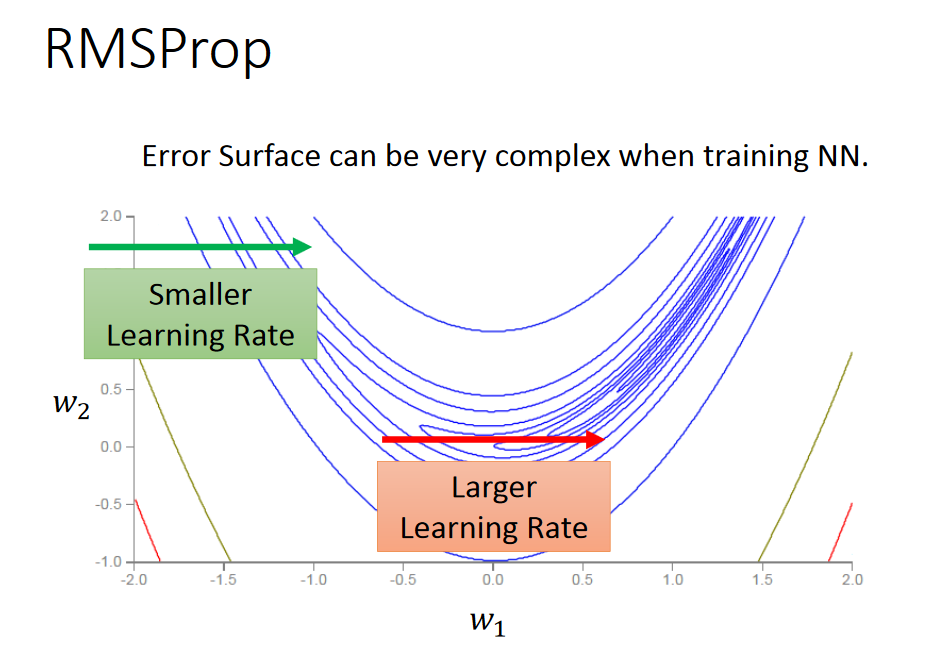
但是当情况复杂时,需要Learning Rate 变动更加灵活,adgrad的方法不在实用,我们采用RMSProp的方法。

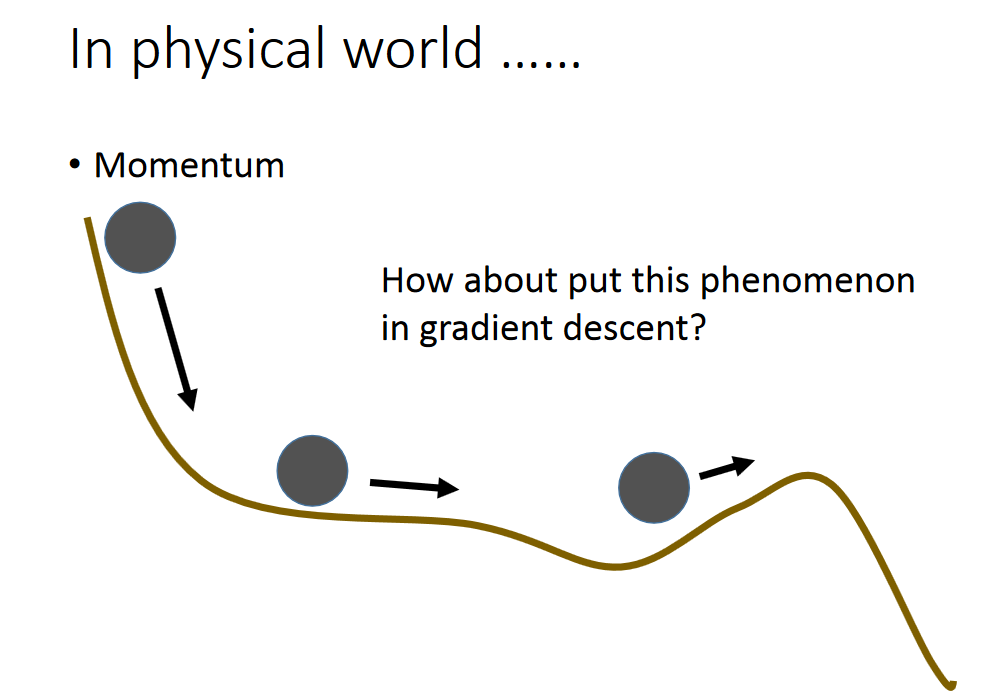
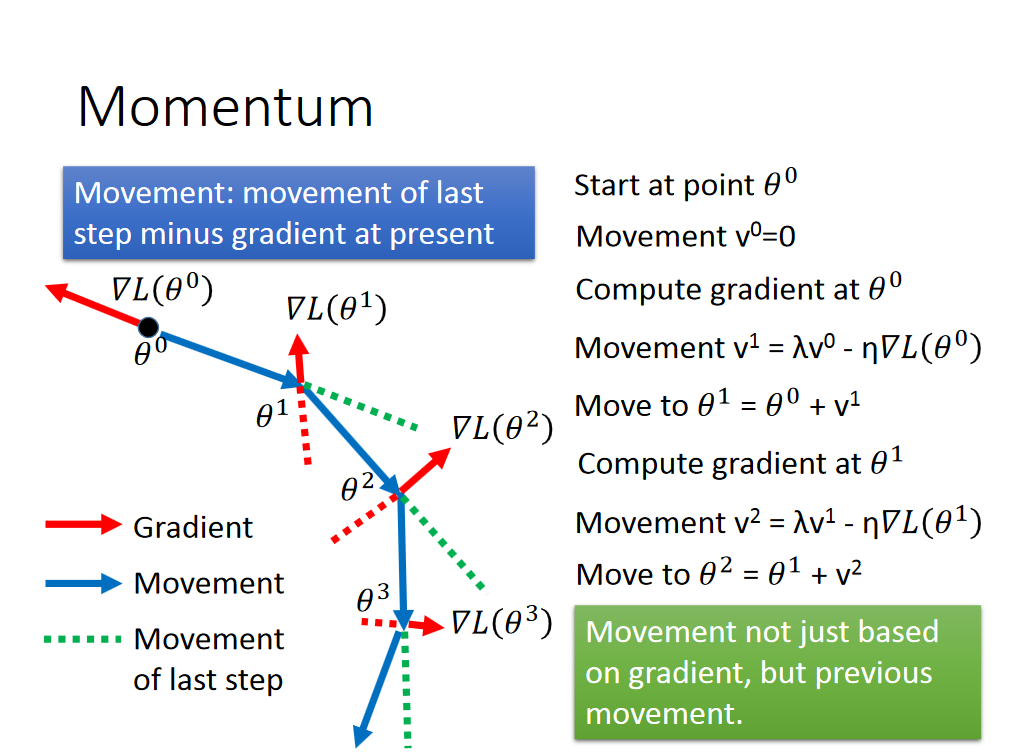
Momentum(gradient descent 融入惯性作用)


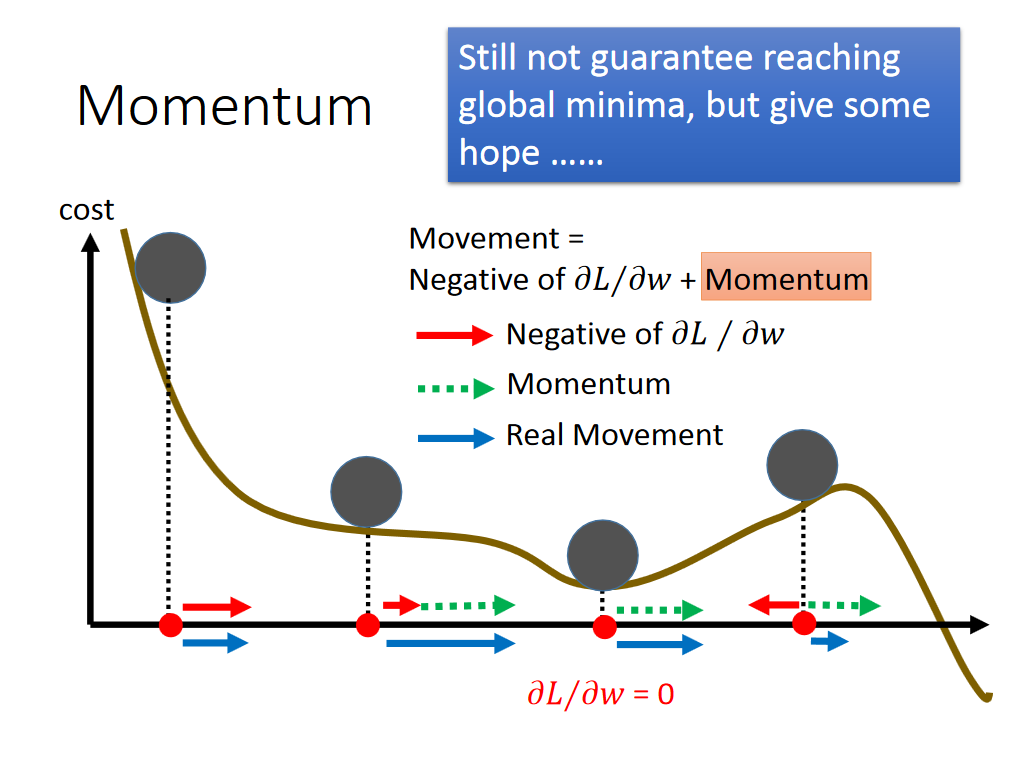
Adam

在testing data上performance不好
Early Stopping
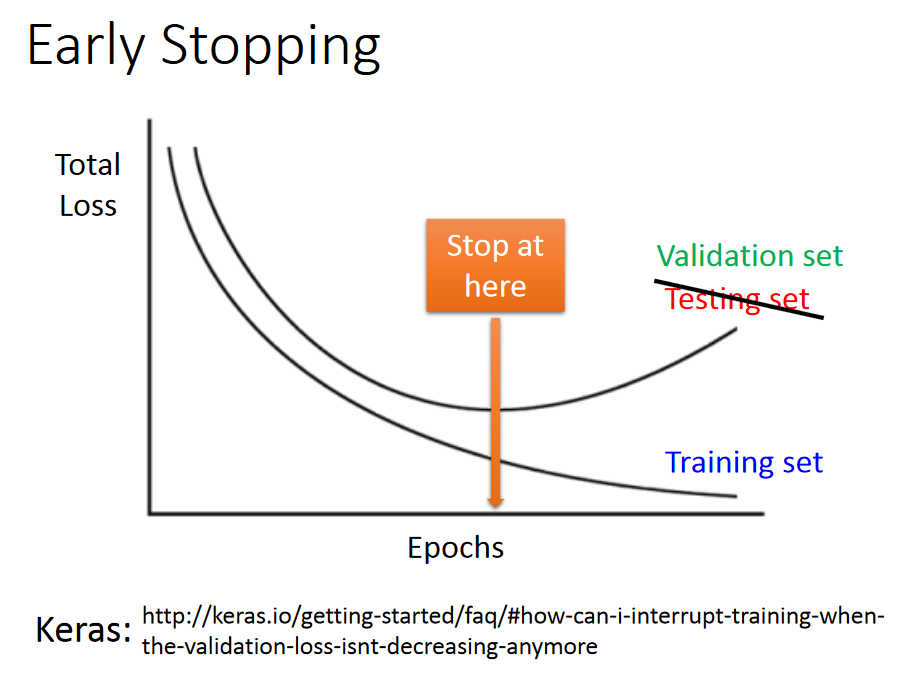
Regularization



正则的作用是:像人脑一样,不经常用的神经元会消失。

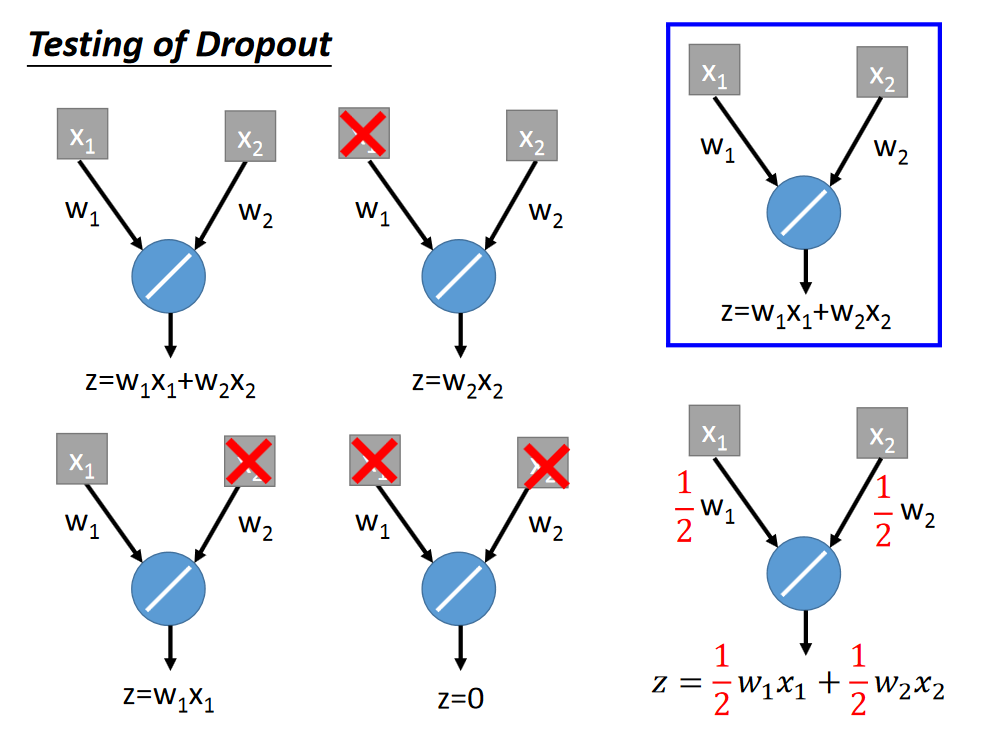
Dropout
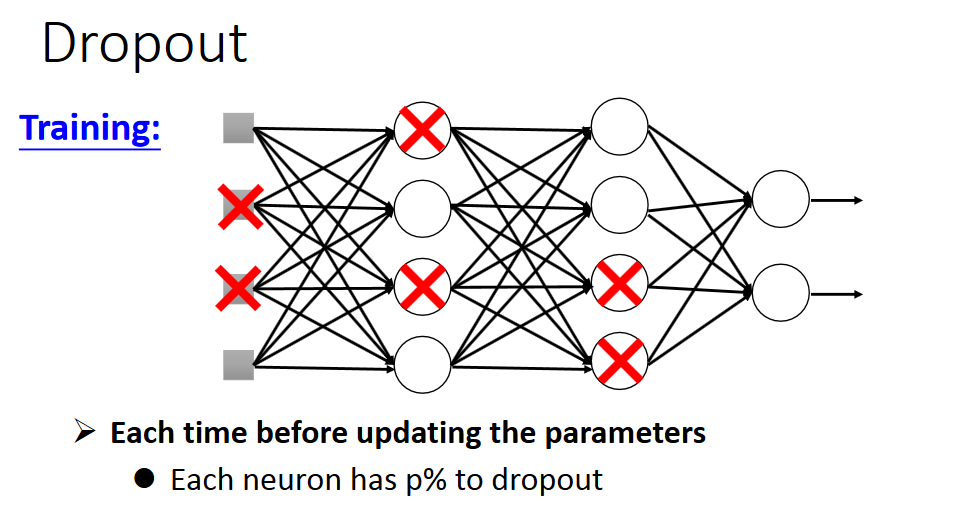
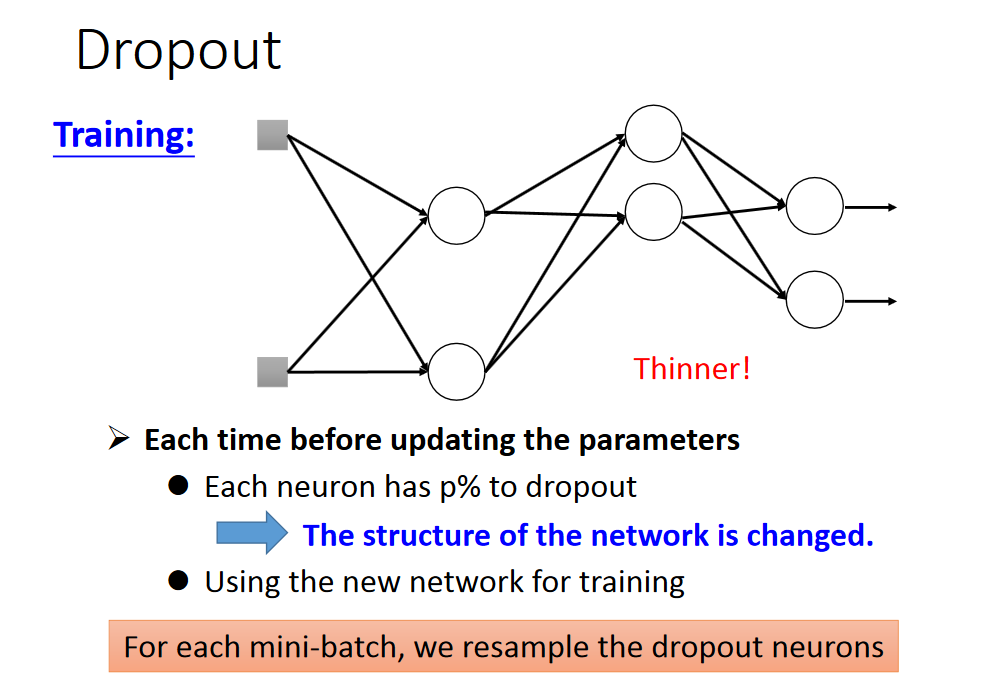

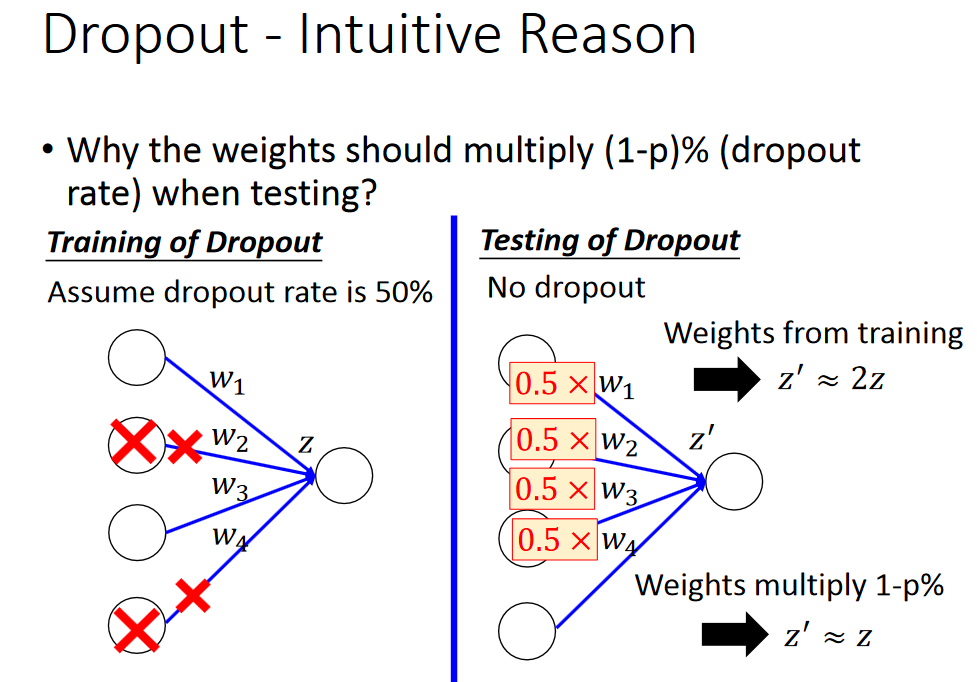
直观的解释


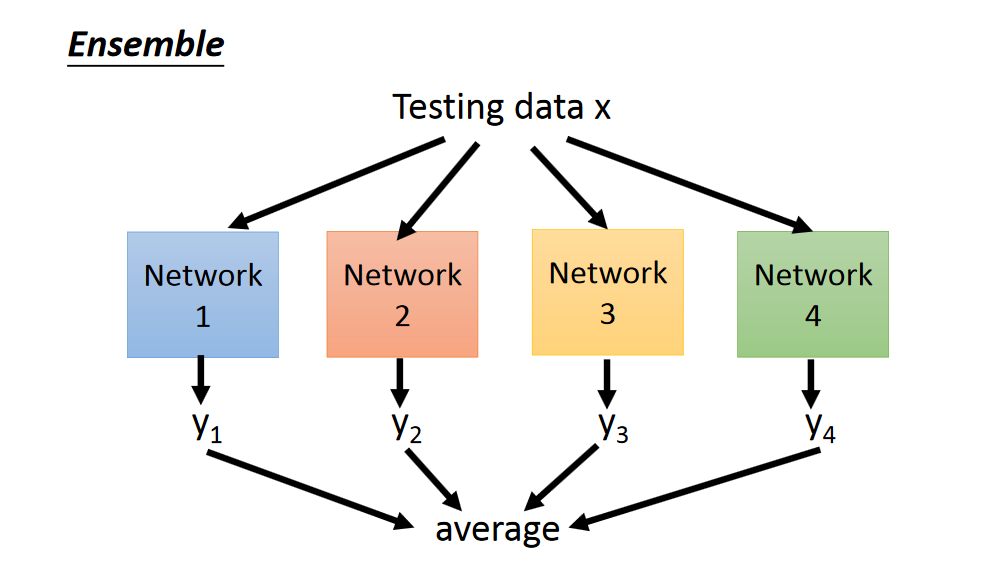
Dropout是ensemble的一种类型

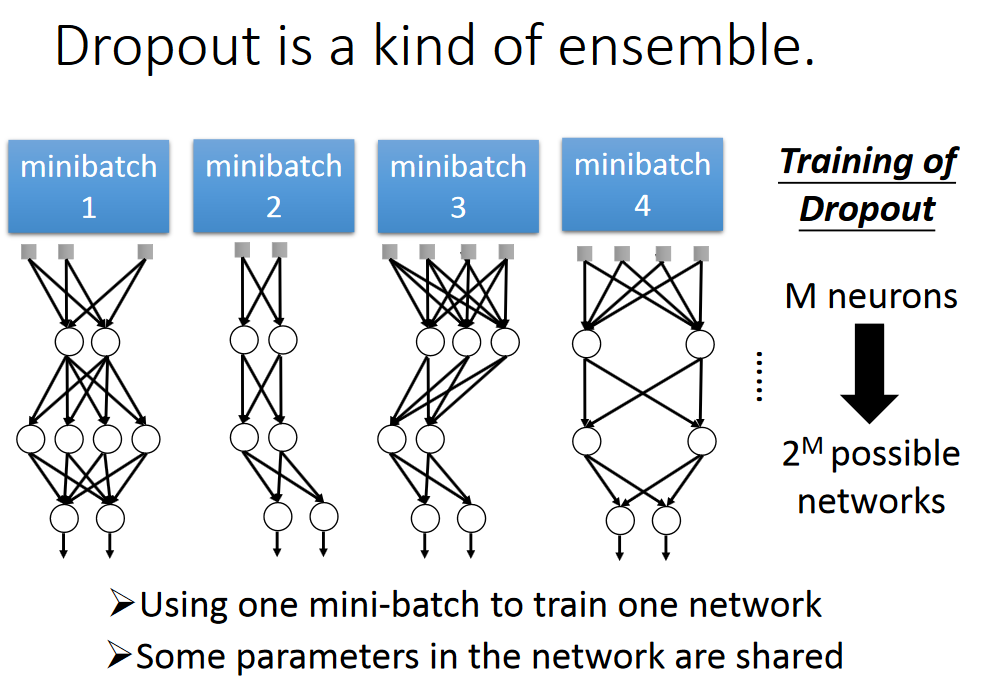
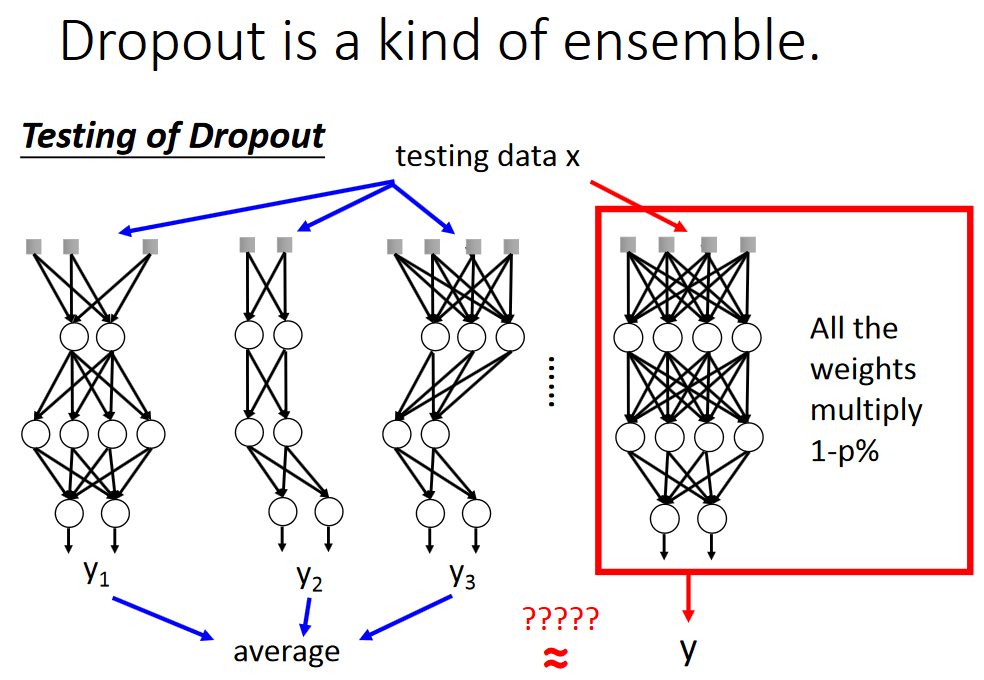
上述两种是等价的,简单的线性证明如下,非线性的不能证明,不过Dropout还是起作用。
参考:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/DNN%20tip.pdf