最早的计算机是由美国人发明的,最早的编码系统就是ASCII码,通过八位二进制(一个字节)表示128个字符abcAbc+- 等等。。。
问题来了:那么ASCII码只能表示英文字符和些特殊符号,那其他非英语国家怎么办呢?
于是中国发明了gbk编码,印度发明了....
世界编码变得混乱,于是国际组织发布了一套编码,把所有编码归纳进来=>Unicode编码。这套编码表的编号从0一直算到了100多万(三个字节)。每一个区间都对应着一种语言的编码。目前几乎收纳了全世界大部分的字符。所有的字符都有唯一的编号,这就解决了解码的冲突,于是天下大定!
问题又来了:Unicode把大家都归纳进来,为解决了字符的显示,却没有为编码的二进制传输和二进制解码做出规定。
如果使用Unicode码表解码的话,每次都使用三个字节来存储,传输一个字符,这样就会造成资源浪费,本来一个ASCII码就可以所有英文字符了,所以美国人当然不愿意了。
于是,就出现了如下解决方案:uft-8,utf-16,utf-32这些编码方案。utf-16是用两个字节来编码所有的字符,utf-32则选择用4个字节来编码。下面只讲一下utf-8这种解决方案,因为它用的最多,用得最多是因为在当时它的方案最好,最节省资源。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编 码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
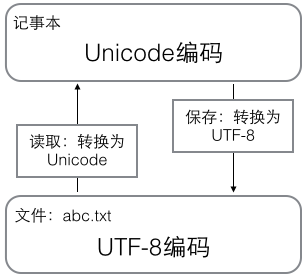
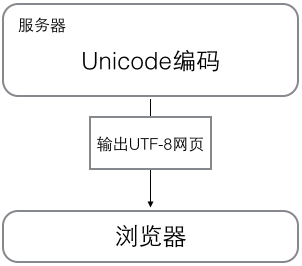
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码