Apache spark2.1.0 编译 hadoop-2.6-cdh5.11.2 的对应版本
搞了两天,终于把spark编译成功了,把编译过程记录一下
编译失败的坑:
1)linux内存不足,maven编译过程中内存溢出
2)找不到cloudera仓库
3)报各种错误
考虑到maven下载可能会被墙,于是买了国外的云主机,内存4g,终于编译成功了,并且编译速度相当快,只花了8分钟
成功编译Apaceh spark成对应的chd版本基本步骤如下(使用make-distribution.sh打包编译):
1.安装maven,有版本要求3.x以上的,用最新的就行了
2.安装jdk 1.7+,2.x以上的spark尽量使用 jdk1.8,并且不要使用自带的open jdk ,下载oracle的jdk
3.确认maven,jdk都配置完成
4.下载spark,解压
5.因为要编译成对应hadoop cdh版本,所以需要在spark HOME目录下的pom.xml文件找到repository位置添加
<repository> <id>cloudera</id> <name>cloudera repository</name> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository>
6.为了加快编译速度,修改dev/make-distribution.sh文件
添加以下内容,并把之前的内容注释,因为默认是通过扫描来获得这些值的,会消耗一些时间
VERSION=2.1.0 #spark的版本 SCALA_VERSION=2.10.6 #scala的版本,可以在pom.xml文件的scala.version中找到 SPARK_HADOOP_VERSION=2.6.0-cdh5.11.2 #编译对应具体的hadoop版本 SPARK_HIVE=1 #支持HIVE
7.避免内存溢出
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
可以根据自己电脑内存情况调整
8.开始编译
./dev/make-distribution.sh --name spark2.1.0-cdh5.11.2 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.11.2 -Phive -Phive-thriftserver -Pyarn
--tgz 打包成 tgz
--name 编译打包的名称 spark2.1.0-cdh5.11.2 默认会在前面添加spark2.1.0-bin,如果编译成功那么全名应该是 spark2.1.0-bin-spark2.1.0-cdh5.11.2 -Phadoop 对应hadoop的大版本 -Dhadoop.version 对应hadoop的具体版本 -Phive -Pyarn 支持hive,yarn
9.等待完成,编译成功后会在 spark 的home目录下生成打包的文件
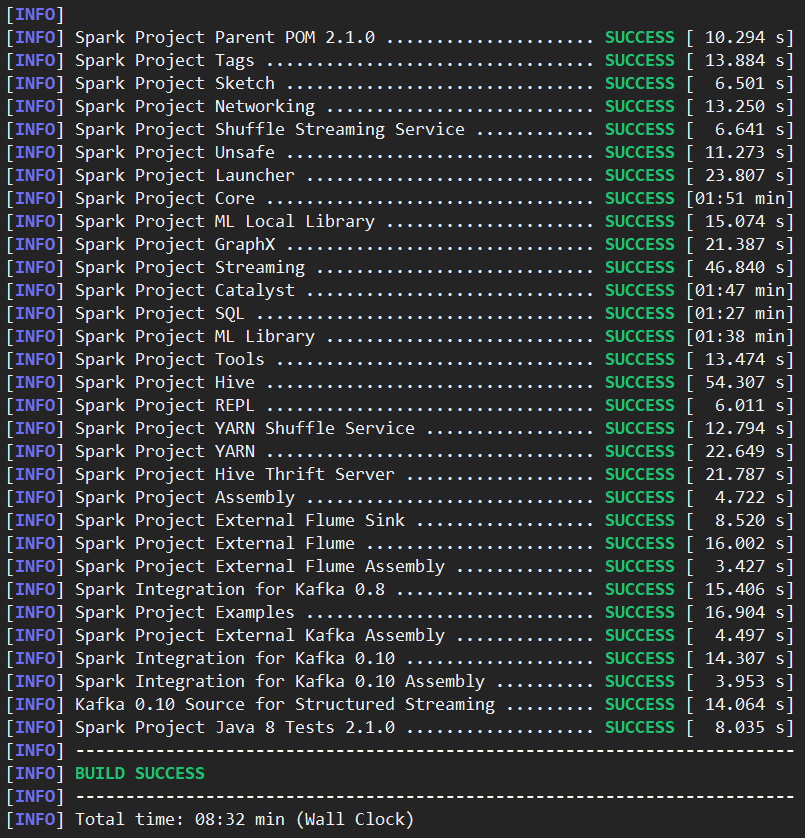

10.然后使用xftp软件把编译成功的包传回本地就行
ps:博客上的代码,直接复制到linux文件上可能会用问题,所以建议手动输入