1.1. 计算操作
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致,不再赘述
●官网示例代码:
|
caseclassDeviceData(device:String, deviceType:String, signal:Double, time:DateTime) val df:DataFrame=...// streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string } val ds:Dataset[DeviceData]= df.as[DeviceData] // streaming Dataset with IOT device data // Select the devices which have signal more than 10 df.select("device").where("signal > 10") // using untyped APIs ds.filter(_.signal >10).map(_.device) // using typed APIs // Running count of the number of updates for each device type df.groupBy("deviceType").count() // using untyped API // Running average signal for each device type importorg.apache.spark.sql.expressions.scalalang.typed ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API |
1.2. 输出
计算结果可以选择输出到多种设备并进行如下设定
1.output mode:以哪种方式将result table的数据写入sink
2.format/output sink的一些细节:数据格式、位置等。
3.query name:指定查询的标识。类似tempview的名字
4.trigger interval:触发间隔,如果不指定,默认会尽可能快速地处理数据
5.checkpoint地址:一般是hdfs上的目录。注意:Socket不支持数据恢复,如果设置了,第二次启动会报错
1.2.1. output mode
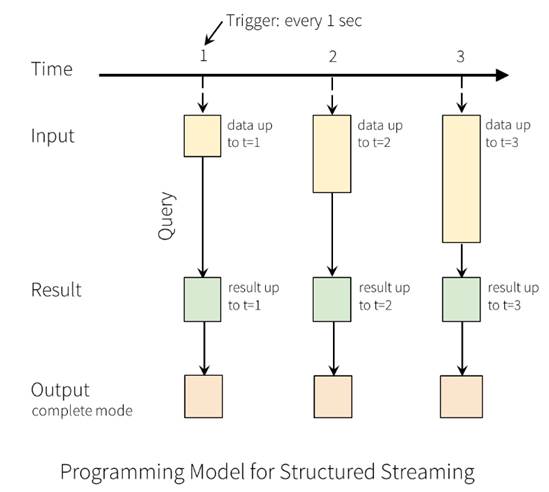
每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。
这里有三种输出模型:
1.Append mode:默认模式,新增的行才输出,每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持那些添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询select,where,map,flatMap,filter,join等会支持追加模式。不支持聚合
2.Complete mode: 所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
3.Update mode:更新的行才输出,每次更新结果集时,仅将被更新的结果行输出到接收器(自Spark 2.1.1起可用),不支持排序
1.2.2. output sink
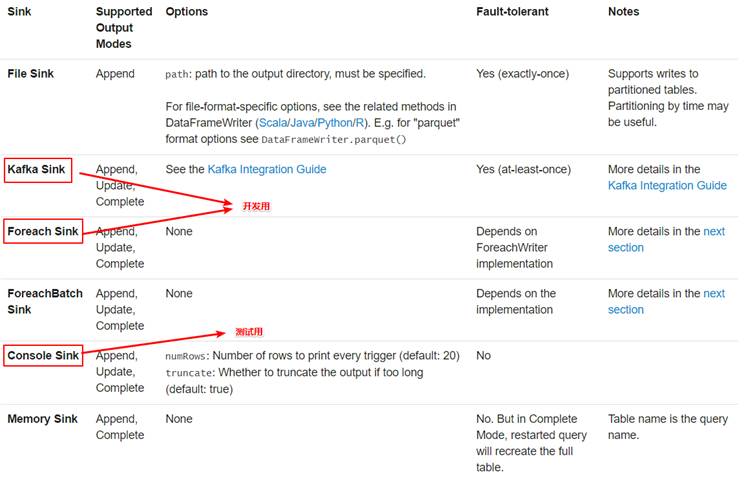
●使用说明
File sink - Stores the output to a directory.支持parquet文件,以及append模式
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path","path/to/destination/dir")
.start()
Kafka sink - Stores the output to one or more topics in Kafka.
writeStream
.format("kafka")
.option("kafka.bootstrap.servers","host1:port1,host2:port2")
.option("topic","updates")
.start()
Foreach sink - Runs arbitrary computation on the records in the output. See later in the section for more details.
writeStream
.foreach(...)
.start()
Console sink (for debugging) - Prints the output to the console/stdout every time there is a trigger. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory after every trigger.
writeStream
.format("console")
.start()
Memory sink (for debugging) - The output is stored in memory as an in-memory table. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory. Hence, use it with caution.
writeStream
.format("memory")
.queryName("tableName")
.start()
●官网示例代码
|
// ========== DF with no aggregations ========== val noAggDF = deviceDataDf.select("device").where("signal > 10") // Print new data to console noAggDF .writeStream .format("console") .start() // Write new data to Parquet files noAggDF .writeStream .format("parquet") .option("checkpointLocation","path/to/checkpoint/dir") .option("path","path/to/destination/dir") .start() // ========== DF with aggregation ========== val aggDF = df.groupBy("device").count() // Print updated aggregations to console aggDF .writeStream .outputMode("complete") .format("console") .start() // Have all the aggregates in an in-memory table aggDF .writeStream .queryName("aggregates") // this query name will be the table name .outputMode("complete") .format("memory") .start()
spark.sql("select * from aggregates").show() // interactively query in-memory table |