sklearn中boston数据集--------波士顿房价数据集包含506组数据,每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等。因此,波士顿房价数据集能够应用到回归问题上。
要求:用正则化的线性回归算法(ridge)去拟合数据,并输出使用不同α时,对应的预测精度图。具体可以按照以下步骤来完成
- 加载数据并做预处理(切分训练集、测试集)。
- 正确建立ridge模型并对数据进行训练,输出不同α时对应的预测精度
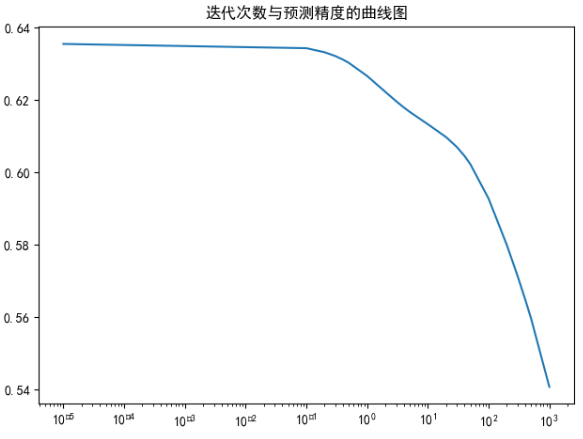
- 画出迭代次数与预测精度的曲线图。
import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import Ridge from sklearn.datasets import load_boston import matplotlib.pyplot as plt # 正常显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示负数 plt.rcParams['axes.unicode_minus'] = False # 加载数据 data = load_boston() # 提取数据 X = data.data y = data.target # 切分数据为 训练集和测试集数据 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0) # 初始化alphas alphas = [0.00001,0.1,0.2,0.3,0.4,0.5,1,2,3,4,5,10,20,30,40,50,100,200,300,400,500,1000] scores = [] for alpha in alphas: # 建立Ridge模型 model = Ridge(alpha=alpha) # 训练模型 model.fit(X_train,y_train) # 计算精度 scores.append(model.score(X_test,y_test)) print(scores) # 画出迭代次数与预测精度的曲线图 plt.title('迭代次数与预测精度的曲线图') plt.plot(alphas,scores) plt.xscale('log') plt.show()