OpenCV中的图像处理
颜色空间的转换:
最常用的:BGR->Gray和BGR->HSV
我们要用到的函数是:cv2.cvtColor(input_image,flag),其中 flag就是转换类型。
在 OpenCV 的 HSV 格式中,H(色彩/色度)的取值范围是 [0,179], S(饱和度)的取值范围 [0,255],V(亮度)的取值范围 [0,255]。但是不 同的软件使用的值可能不同。所以当你需要拿 OpenCV 的 HSV 值与其他软 件的 HSV 值进行对比时,一定要记得归一化。
物体跟踪
现在我们知道怎样将一幅图像从 BGR 转换到 HSV 了,我们可以利用这一点来提取带有某个特定颜色的物体。在 HSV 颜色空间中要比在 BGR 空间中更容易表示一个特定颜色。在我们的程序中,我们要提取的是一个蓝色的物
# 可以检测到蓝色的物品 import cv2 import numpy as np # 打开摄像头 cap=cv2.VideoCapture(0) while(1): # 获取每一帧 ret,frame=cap.read() # 转换到 HSV hsv=cv2.cvtColor(frame,cv2.COLOR_BGR2HSV) # 设定蓝色的阈值 lower_blue=np.array([110,50,50]) upper_blue=np.array([130,255,255]) # 根据阈值构建蒙版 mask=cv2.inRange(hsv,lower_blue,upper_blue) # 对原图像和蒙版进行位运算 res=cv2.bitwise_and(frame,frame,mask=mask) # 显示图像 cv2.imshow('frame',frame) cv2.imshow('mask',mask) cv2.imshow('res',res) k=cv2.waitKey(5)&0xFF if k==27: break # 关闭窗口 cv2.destroyAllWindows()

图像中仍然有一些噪音,我们会在后面的章节中介绍如何消减噪音。
这是物体跟踪中最简单的方法。当你学习了轮廓之后,你就会学到更多相关知识,那是你就可以找到物体的重心,并根据重心来跟踪物体,仅仅在摄像头前挥挥手就可以画出同的图形,或者其他更有趣的事。
src: 输入图像
lowerb: 像素值的下边界,如果图中的像素低于这个值,就变为0
upperb: 像素值的上边界,如果图中的像素高于这个值,就变为0,lowerb~upperb之间的值变为255
dst: 输出的是二值化的图像
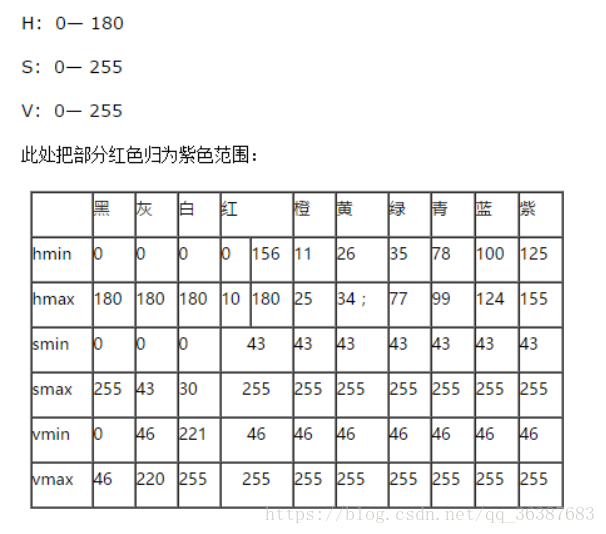
怎样找到要跟踪对象的 HSV 值?
import cv2 import numpy as np img = cv2.imread("goods.jpg") img = img[:,:,[2,1,0]] green=np.uint8([[[0,255,0]]]) lower_blue=np.array([10,50,50]) upper_blue=np.array([130,255,255]) hsv = cv2.cvtColor(img,cv2.COLOR_RGB2HSV) mask=cv2.inRange(hsv,lower_blue,upper_blue) res=cv2.bitwise_and(img,img,mask=mask) constant= cv2.copyMakeBorder(img,10,10,10,10,cv2.BORDER_CONSTANT,value=[255,0,0]) import matplotlib.pyplot as plt import matplotlib as mpl mpl.rcParams["font.sans-serif"] = ["SimHei"] plt.subplot(221),plt.imshow(img,'gray'),plt.title('原图') plt.subplot(222),plt.imshow(mask,'gray'),plt.title('HSV提取图') plt.subplot(223),plt.imshow(res,'gray'),plt.title('进行与运算') plt.subplot(224),plt.imshow(constant,'gray'),plt.title('加边框') plt.show()

几何变换
扩展缩放
扩展缩放只是改变图像的尺寸大小。OpenCV 提供的函数 cv2.resize()可以实现这个功能。图像的尺寸可以自己手动设置,你也可以指定缩放因子。我们可以选择使用不同的插值方法。在缩放时我们推荐使用 cv2.INTER_AREA, 在扩展时我们推荐使用 v2.INTER_CUBIC(慢) 和 v2.INTER_LINEAR。默认情况下所有改变图像尺寸大小的操作使用的插值方法都是 cv2.INTER_LINEAR。你可以使用下面任意一种方法改变图像的尺寸:
import cv2 img=cv2.imread('dmn.jpg') # 下面的 None 本应该是输出图像的尺寸,但是因为后边我们设置了缩放因子 # 因此这里为 None res=cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_CUBIC) #OR # 这里呢,我们直接设置输出图像的尺寸,所以不用设置缩放因子 height,width=img.shape[:2] res=cv2.resize(img,(2*width,2*height),interpolation=cv2.INTER_CUBIC) while(1): cv2.imshow('res',res) cv2.imshow('img',img) if cv2.waitKey(1) & 0xFF == 27: break cv2.destroyAllWindows()
平移
平移就是将对象换一个位置。如果你要沿(x,y)方向移动,移动的距离是(tx,ty),你可以以下面的方式构建移动矩阵:
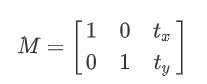
你可以使用 Numpy 数组构建这个矩阵(数据类型是 np.float32),然后把它传给函数 cv2.warpAffine()。看看下面这个例子吧,它被移动了(100,50)个像素。
import cv2 img = cv2.imread('dmn.jpg') img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) rows, cols = img.shape import numpy as np # 注意这里的数据类型必须是float32 100是x移动的大小,200是y移动的大小 M= np.array([[1,0,100],[0,1,200]],dtype=np.float32) # 这里M是乘于的矩阵,后面的元组是画板的大小 dst = cv2.warpAffine(img, M, (cols+100 , rows+100 )) while (1): cv2.imshow('img', dst) if cv2.waitKey(1) & 0xFF == 27: break cv2.destroyAllWindows()

旋转
对一个图像旋转角度 θ, 需要使用到下面形式的旋转矩阵。
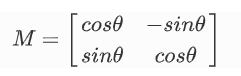
但是 OpenCV 允许你在任意地方进行旋转,但是旋转矩阵的形式应该修 改为
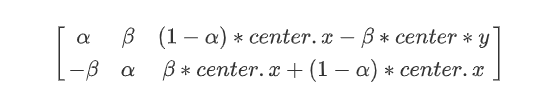
其中: α = scale · cos θ β = scale · sin θ 为了构建这个旋转矩阵,OpenCV 提供了一个函数:cv2.getRotationMatrix2D。 下面的例子是在不缩放的情况下将图像旋转 90 度。
import cv2 img = cv2.imread('dmn.jpg') img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) rows, cols = img.shape # 这里的第一个参数为旋转中心,第二个为旋转角度,第三个为旋转后的缩放因子 # 可以通过设置旋转中心,缩放因子,以及窗口大小来防止旋转后超出边界的问题 M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 90, 0.6) # 第三个参数是输出图像的尺寸中心 dst = cv2.warpAffine(img, M, (cols + 10, rows + 10)) while (1): cv2.imshow('img', dst) if cv2.waitKey(1) & 0xFF == 27: break cv2.destroyAllWindows()

仿射变换
在仿射变换中,原图中所有的平行线在结果图像中同样平行。为了创建这个矩阵我们需要从原图像中找到三个点以及他们在输出图像中的位置。然后cv2.getAffineTransform 会创建一个 2x3 的矩阵,最后这个矩阵会被传给函数 cv2.warpAffine。
import cv2 import numpy as np from matplotlib import pyplot as plt img=cv2.imread('dmn.jpg') img = img[:,:,[2,1,0]] rows,cols,ch=img.shape pts1=np.float32([[50,50],[200,50],[50,200]]) pts2=np.float32([[10,100],[200,50],[100,250]]) M=cv2.getAffineTransform(pts1,pts2) dst=cv2.warpAffine(img,M,(cols,rows)) plt.subplot(121),plt.imshow(img) plt.subplot(122),plt.imshow(dst) plt.show()
透视变换
对于视角变换,我们需要一个 3x3 变换矩阵。在变换前后直线还是直线。要构建这个变换矩阵,你需要在输入图像上找 4 个点,以及他们在输出图像上对应的位置。这四个点中的任意三个都不能共线。这个变换矩阵可以有函数 cv2.getPerspectiveTransform() 构建。然后把这个矩阵传给函数 cv2.warpPerspective。
import cv2 import numpy as np from matplotlib import pyplot as plt img=cv2.imread('img/fnn.jpg') rows,cols,ch=img.shape pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]]) pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]]) M=cv2.getPerspectiveTransform(pts1,pts2) dst=cv2.warpPerspective(img,M,(300,300)) plt.subplot(121),plt.imshow(img) plt.subplot(122),plt.imshow(dst) plt.show()
图像阈值
简单阈值
与名字一样,这种方法非常简单。但像素值高于阈值时,我们给这个像素赋予一个新值(可能是白色),否则我们给它赋予另外一种颜色(也许是黑色)。这个函数就是 cv2.threshhold()。这个函数的第一个参数就是原图像,原图像应该是灰度图。第二个参数就是用来对像素值进行分类的阈值。第三个参数就是当像素值高于(有时是小于)阈值时应该被赋予的新的像素值。OpenCV提供了多种不同的阈值方法,这是有第四个参数来决定的。这些方法包括:
import cv2 from matplotlib import pyplot as plt img=cv2.imread('../img/fnn.jpg',0) ret,thresh1=cv2.threshold(img,127,255,cv2.THRESH_BINARY) ret,thresh2=cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV) ret,thresh3=cv2.threshold(img,127,255,cv2.THRESH_TRUNC) ret,thresh4=cv2.threshold(img,127,255,cv2.THRESH_TOZERO) ret,thresh5=cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV) titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV'] images = [img, thresh1, thresh2, thresh3, thresh4, thresh5] for i in range(6): plt.subplot(2,3,i+1),plt.imshow(images[i],'gray') plt.title(titles[i]) plt.xticks([]),plt.yticks([]) plt.show()

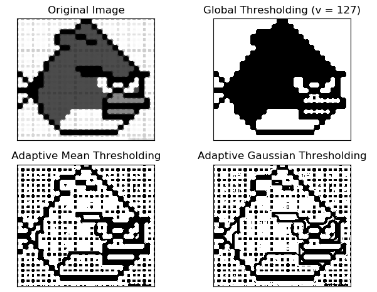
自适应阈值
在前面的部分我们使用是全局阈值,整幅图像采用同一个数作为阈值。当时这种方法并不适应与所有情况,尤其是当同一幅图像上的不同部分的具有不同亮度时。这种情况下我们需要采用自适应阈值。此时的阈值是根据图像上的每一个小区域计算与其对应的阈值。因此在同一幅图像上的不同区域采用的是不同的阈值,从而使我们能在亮度不同的情况下得到更好的结果。这种方法需要我们指定三个参数,返回值只有一个。
Adaptive Method- 指定计算阈值的方法。 – cv2.ADPTIVE_THRESH_MEAN_C:阈值取自相邻区域的平均值 – cv2.ADPTIVE_THRESH_GAUSSIAN_C:阈值取值相邻区域的加权和,权重为一个高斯窗口。 • Block Size - 邻域大小(用来计算阈值的区域大小)。 • C - 这就是是一个常数,阈值就等于的平均值或者加权平均值减去这个常数。
import cv2 import numpy as np from matplotlib import pyplot as plt img = cv2.imread('../img/fnn.jpg',0) # 中值滤波 img = cv2.medianBlur(img,5) ret,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY) #11 为 Block size, 2 为 C 值 th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2) th3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2) titles = ['Original Image', 'Global Thresholding (v = 127)','Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding'] images = [img, th1, th2, th3] for i in range(4): plt.subplot(2,2,i+1),plt.imshow(images[i],'gray') plt.title(titles[i]) plt.xticks([]),plt.yticks([]) plt.show()
Otsu’s 二值化
在使用全局阈值时,我们就是随便给了一个数来做阈值,那我们怎么知道我们选取的这个数的好坏呢?答案就是不停的尝试。如果是一副双峰图像(简单来说双峰图像是指图像直方图中存在两个峰)呢?我们岂不是应该在两个峰之间的峰谷选一个值作为阈值?这就是 Otsu 二值化要做的。简单来说就是对一副双峰图像自动根据其直方图计算出一个阈值。(对于非双峰图像,这种方法得到的结果可能会不理想)。
这里用到到的函数还是 cv2.threshold(),但是需要多传入一个参数(flag):cv2.THRESH_OTSU。这时要把阈值设为 0。然后算法会找到最优阈值,这个最优阈值就是返回值 retVal。如果不使用 Otsu 二值化,返回的retVal 值与设定的阈值相等。下面的例子中,输入图像是一副带有噪声的图像。第一种方法,我们设127 为全局阈值。第二种方法,我们直接使用 Otsu 二值化。第三种方法,我们首先使用一个 5x5 的高斯核除去噪音,然后再使用 Otsu 二值化。看看噪音去除对结果的影响有多大吧。
import cv2 import numpy as np from matplotlib import pyplot as plt img = cv2.imread('../img/fnn.jpg',0) # global thresholding ret1,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY) # Otsu's thresholding ret2,th2 = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) #(5,5)为高斯核的大小,0 为标准差 blur = cv2.GaussianBlur(img,(5,5),0) # 阈值一定要设为 0! ret3,th3 = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) # plot all the images and their histograms images = [img, 0, th1, img, 0, th2, blur, 0, th3] titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)', 'Original Noisy Image','Histogram',"Otsu's Thresholding", 'Gaussian filtered Image','Histogram',"Otsu's Thresholding"] # 这里使用了 pyplot 中画直方图的方法,plt.hist, 要注意的是它的参数是一维数组 # 所以这里使用了(numpy)ravel 方法,将多维数组转换成一维,也可以使用 flatten 方法 for i in range(3): plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray') plt.title(titles[i*3]), plt.xticks([]), plt.yticks([]) plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256) plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([]) plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray') plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([]) plt.show()

在这一部分我们会演示怎样使用 Python 来实现 Otsu 二值化算法,从而告诉大家它是如何工作的。如果你不感兴趣的话可以跳过这一节。因为是双峰图,Otsu 算法就是要找到一个阈值(t), 使得同一类加权方差最小,需要满足下列关系式:
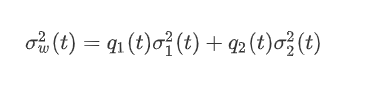
其中:

其实就是在两个峰之间找到一个阈值 t,将这两个峰分开,并且使每一个峰内的方差最小。实现这个算法的 Python 代码如下:
import cv2 import numpy as np import warnings warnings.filterwarnings("ignore") img = cv2.imread('../img/fnn.jpg',0) blur = cv2.GaussianBlur(img,(5,5),0) # find normalized_histogram, and its cumulative distribution function # 计算归一化直方图 #CalcHist(image, accumulate=0, mask=NULL) hist = cv2.calcHist([blur],[0],None,[256],[0,256]) hist_norm = hist.ravel()/hist.max() Q = hist_norm.cumsum() bins = np.arange(256) fn_min = np.inf thresh = -1 for i in range(1,256): p1,p2 = np.hsplit(hist_norm,[i]) # probabilities q1,q2 = Q[i],Q[255]-Q[i] # cum sum of classes b1,b2 = np.hsplit(bins,[i]) # weights # finding means and variances m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2 v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2 # calculates the minimization function fn = v1*q1 + v2*q2 if fn < fn_min: fn_min = fn thresh = i # find otsu's threshold value with OpenCV function ret, otsu = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) print(thresh,ret) # 结果:140 139.0