spark streaming的相关概念:
spark的核心是创建一个RDD对象,然后对RDD对象进行计算操作等
streaming可以理解为是 一个连续不断的数据流 ,然后将每个固定时间段里的数据构建成一个RDD,然后就会创一连串的RDD流,这就是DStream(streaming的主要操作对象)
batch 就是上面所说的固定时间段的时间表示,可以为5秒,10秒or ect ,DStream中每个RDD接收数据的时间,也作 mini-batch
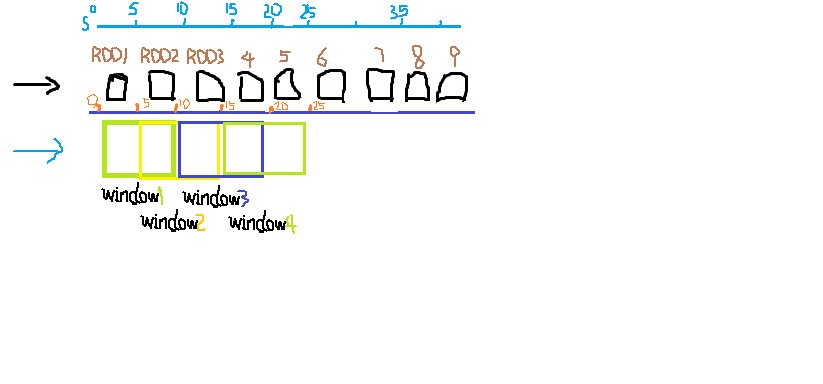
window 用于装载上述【一个bactch内数据所创建的RDD】 的容器,容器的大小用时间表示(毫秒,秒,分钟等),必须为 batch的倍数,window 内的RDD也会随时间而不断更新,window的更新间隔称为duration ,必须为batch的倍数。
如下图 可理解为一个RDD的batch为5秒 ,一个window的容积是2个RDD的batch即10秒,window的duration为一个batch 5秒。
即window每次滑动的距离为5秒,1个RDD。
使用checkpointing更新数据的代码示例
统计文件中的数据,并使用updateStateByKey来更新结果
Scala版
package wordcounttest import org.apache.spark._ import org.apache.spark.streaming._ import java.sql.Timestamp import org.apache.spark.streaming.dstream.DStream Object SteamingTest{ def main(args:Array[String]){ val conf = new SparkConf().setMaster("local[4]").setAppName("test1") val sc = new SparkContext(conf) // 这里设置 Dstream 的batch 是 5 秒 val ssc = new StreamingContext(sc,Seconds(5)) val filestream = ssc.textFileStream("/home/spark/cho6input") //设置dstream 数据来源,在ssc.start()后这个目录中新生成的txt文件都会被读入 //定义一个处理order的class case class Order(time:java.sql.TimeStamp, OrderId:Long, clientId:Long,symbol:String,amount:Int,price:Double,buy:Boolean) val orders = filestream.flatMap(line => { val dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss") //设置要解析的时间数据的字符型式 val s = line.split(",") try{ assert(s(6) == "B" || s(6) == "S") List(Order(new Timestamp(dateFormat.parse(s(0)).getTime()),s(1).toLong,s(2).toLong,s(3),s(4).toInt,s(5).toDouble,s(6) == "B")) } catch{ case e: Throwable => println("Wrong line format(" + e + "):" +line) List() } }) val numPerType = orders.map(o => (o.buy,1L)).reduceByKey((c1,c2) => c1+c2) val amountPerClient = orders.map(o => (o.clientId,o.amount*o.price))
val amountState = amountPerClient.updateStateByKey((vals,totalOpt:Option[Double]) => { totalOpt match{ case Some(total) => Some(total +vals.sum) case None => Some(vals.sum) } } val updateAmountState = (clinetId:Long,amount:Option[Double],state:State[Double]) => { var total = amount.getOrElse(0.toDouble) if(state.exists()) total += state.get() state.update(total) Some((clientId,total)) }
// map val amountState2 = amountPerClient.mapWithState(StateSpec.function(updateAmountState)).stateSnapshots() val top5clients = amountState.transform( _.sortBy(_._2,false).map(_._1).zipWithIndex.filter(x =>x._2 <5)) val buySellList = numPerType.map( t => if(t._1) ("BUYS",List(t._2.toString)) else ("SELLS",List(t._2.toString)) ) val top5clList = top5clients.repartition(1).map(x => x._1.toString).glom().map(arr => ("TOP5CLIENTS",arr.toList)) val finaleStream = buySellList.union(top5clList) finalStream.repartition(1).saveAsTextFiles("/home/spark/ch06output/output","txt") sc.setCheckpointDir("/home/spark/checkpoint") ssc.start() }
updateStateByKey(func)使用说明
updateStateByKey一般只需要一个参数 -- func(vals,optdata) 这个func的入参是(一个数据队列vals 和一个Option类型的数据) 返回值是Option类型数据
vals是当前新的batch中接收的数据队列 ,Option类型的数据是 上个batch的计算的保存的结果 , 返回值option类型的数据是当前计算的结果
通过设置 checkpoint 使用updateStateByKey计算所得的结果会自动保存,下个batch计算时会自动读取
mapWithState(func)使用说明
mapWithState(func)的入参 也只需一个func ,这个func通过org.apache.spark.streaming.StateSpec.function()包裹
的一个方法,这个方法的形式为(key,value,optionstate,maptypestate) 即入参为 key,value,上次保存的option类型的状态值,
返回值为option类型的另一种类型的状态值。即上次保存的状态值类型和 当前生成的状态值类型可以不同。
区别: updateStateByKey的func的入参 上次保存的状态值 和 生成的状态值类型 需要相同
mapWithState的func的入参 上次保存的状态值 和 生成的状态值类型 可以不同
checkpointing说明
如果通过 sc.setCheckpointDir('some/path')设置了checkpoint的目录
streaming就会自动在某些时刻 对当前的 DStreaming的信息保存,以便下一次需要历史数据时不用重新计算,可以直接获取;
也可用于故障恢复,streaming重启时根据之前保存 的RDD信息来创建RDD。
使用 checkpoint时一般只需设置CheckpointDir保存当前状态信息的目录,也可设置checkpoint的各个保存点的时间间隔,即每隔多长时间保存一次当前RDD的信息。
chekPoint 是spark streaming 内部自动机制,根据流程图中是否有使用到【需要状态保存点的转换函数】来自动保存某个点的状态信息及计算结果
checkpointing saves an RDD's data and its complete DAG(an RDD's calculation plan),当一个executor异常,RDD不需要从头开始计算,可以从硬盘
中读取存储的结果
【需要考虑过去的计算状态的方法】spark主要提供了两个updateStateByKey 和mapWithState 这两个方法的使用者必须是PairDStream对象,
即(key,value)形式的DStream。 使用updateStateByKey时,state会随每一个新batch变化而变化
http://spark.apache.org/docs/2.3.3/streaming-programming-guide.html#checkpointing
如果需要应用从异常中进行故障恢复 , 就需要改进 streaming 应用,使其 实现了如下逻辑
- 当应用是第一个被开启, 则它会创建一个新的 StreamingContext ,来启动所有的streams 然后call start()
- 当应用是在故障后被重启 ,则它会根据 checkpoint目录中的checkpoint 数据来重新创建一个StreamingContext
实现逻辑 ,使用StreamingContext.getOrCreate
Python
def functionToCreateContext():
sc = SparkContext(...)
ssc = StreamingContext(...)
lines = ssc.socketTextStream(...)
...
ssc.checkpoint(checkpointDirectory) #设置 checkpoint 目录
return ssc
context = StreamingContext.getOrCreate(checkpointDirectory,functionToCreateContext)
#context的其他的操作
context. ...
context.start()
context.awaitTermination()
如果 checkpointDirectory 存在 ,context就会被根据checkpoint data重新创建
如果不存在(比如说第一次运行),方法 functionToCreateContext就会创建一个新的context 然后启动DStreams
python wordCount故障恢复示例
https://github.com/apache/spark/blob/master/examples/src/main/python/streaming/recoverable_network_wordcount.py
另外 要使用getOrCreate的特性,还需要让driver进程在失败时能自动重启。这只能通过运行这个application 的部署基础设施来实现
RDD的checkpointing会导致性能消耗用于 保存到稳定的存储系统 。 会导致执行了 checkpoint的那些batches处理时间变成 。
因此 checkpointing的时间间隔需要仔细设置 ,对于短时间间隔的batch(比如1秒),在每个batch都进行checkpointing会严重减少处理的数据量
checkpoint太频繁会导致流程线延长和task size增长 。
对于需要rdd checkpointing 的状态性的transformations ,默认的check 间隔是batch间隔的倍数,至少为10秒。
可以通过 dstream.checkpoint(checkpointInterval)进行设置 ,将checkpoint间隔设置为sliding间隔的5-10倍是比较好的做法
Accumulators 累加器 ,Broadcast Variables 广播变量 , checkpoints 检查点
Accumulators ,Broadcast variables 并不能从spark streaming的checkpoint中恢复,所以如果你开启了checkpointing 并且使用了Accumulators或Broadcast variables ,
就需要创建一个 惰性的可实例化单个实例的方法,是它们可以在driver重启时,重新实例化
def getWordBlacklist(sparkContext): if ("wordBlacklist" not in globals()): globals()["wordBlacklist"] = sparkContext.broadcast(["a", "b", "c"]) return globals()["wordBlacklist"] def getDroppedWordsCounter(sparkContext): if ("droppedWordsCounter" not in globals()): globals()["droppedWordsCounter"] = sparkContext.accumulator(0) return globals()["droppedWordsCounter"] def echo(time, rdd): # Get or register the blacklist Broadcast blacklist = getWordBlacklist(rdd.context) # Get or register the droppedWordsCounter Accumulator droppedWordsCounter = getDroppedWordsCounter(rdd.context) # Use blacklist to drop words and use droppedWordsCounter to count them def filterFunc(wordCount): if wordCount[0] in blacklist.value: droppedWordsCounter.add(wordCount[1]) False else: True counts = "Counts at time %s %s" % (time, rdd.filter(filterFunc).collect()) wordCounts.foreachRDD(echo)
window窗口函数(scala版)
window的操作作用于一系列的mini-batches 上进行滑动,
每个window DStream 决定因素 = ‘window的容量duration持续时间’+ ‘window的滑动间隔(即一个窗口的数据计算的频度)’
这连个参数都是mini-batches的倍数
要统计每个窗口中每种交易量的前5名可以使用window方法,如果wnidow的mini-batch为5分钟,则表示 每5分钟统计一次近60分钟内交易量最大的前5名
先计算近1小时内每个类型的总交易量
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)).window(Minutes(60)).reduceByKey((a1:Int,a2:Int) => a1+a2)
再取前5名
val topStocks = stocksPerWindow.transform(_.sortBy(_._2,false).map(_._1).zipWithIndex.filter(x => x._2 < 5)).repartition(1).
map(x=>x._1.toString).glom().map(arr=>("TOP5STOCKS",arr.toList))
val finalStream = buySellList.union(top5clList).union(topStocks)
finalStream.repartition(1).saveAsTextFiles("/home/spark/ch06output/output","txt")
sc.setCheckpointDir("/home/spark/checkpoint/")
ssc.start()
window相关函数不需要设置checkpoint ,一般的DStream都可以使用,有些需要(k,v)类型的pair DStream才能使用
相关函数如下
window(winDur,[slideDur])
|
函数 |
说明 |
| window(winDur,[slideDur]) | 每隔slideDur时间段,就对windowDur中的RDD计算一次, winDur- 窗口的大小;slideDur窗口滑动的间隔,默认为mini-batch(一个DStream的时间间隔) |
| countByWindow(winDur,slideDur) | 统计当前windowDur中所有RDD包含的元素个数 ,winDur- 窗口的大小;slideDur窗口滑动的间隔 |
| countByValueAndWindow(winDur,slideDur,[numParts]) | 统计当前窗口中distinct元素(无重复元素)的个数,numParts用于修改当前DStream的默认分区数 |
| reduceByWindow(reduceFunc,winDur,slideDur) | 对window中所有RDD的元素应用 reduceFunc方法 |
| reduceByWindow(reduceFunc,invReduceFunc,winDur,slideDur) | 更高效的reduceByWindow方法,对每个window中所有RDD的元素应用reduceFunc方法;去除不属于当前window的rdd元素,使用方法invReduceFunc |
| groupByKeyAndWindow(winDur,[slideDur],[numParts/partitioner]) | 根据key 对window中所有元素进行分组,slideDur可选参数,numParts设置 |