@description@
给定一棵树,求无序三元组 (a, b, c) 的个数,使得 dis(a, b) = dis(b, c) = dis(c, a),且 a ≠ b, b ≠ c, c ≠ a。
input
第一行一个数 n,n<=100000。
接下来 n-1 行,每行两个数 x, y,表示 x 和 y 之间有一条边相连。
output
三元组个数。
sample input
7
1 2
5 7
2 5
2 3
5 6
4 5
sample output
5
sample explain
(1, 3, 5), (2, 4, 6), (2, 4, 7), (2, 6, 7), (4, 6, 7)
【原题面说与 bzoj3522 相同,然而这道题不是权限题,而 3522 是权限题 hhhh】
@solution@
@part - 1@
我们把这个树转为有根树,则这 3 个点在树上的位置总可以归结为下图的样子:
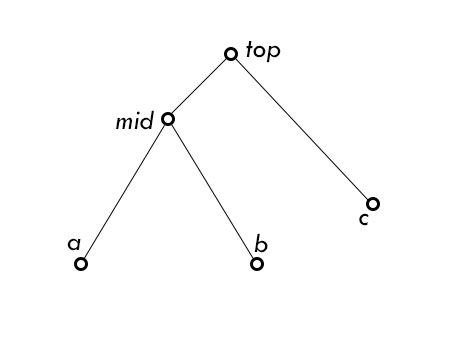
其中 dis(a, mid) = dis(b, mid) = dis(c, mid),且 dis(mid, top), dis(top, c) 可以等于 0
嗯。我觉得应该很显然就不证明了。
我们在 top 处统计这个三元组的贡献。使用树形 dp 来统计答案。
定义 (f[i][j]) 表示在 i 这棵子树中与 i 号点距离为 j 的点数。
再定义 (g[i][j]) 表示在 i 这棵子树中,以 i 作为 top,dis(a/b, mid) - dis(mid, top) = j 的二元组 (a, b) 个数。
则根据定义,我们可以得出这样一个 dp(其中 mxdep[i] 表示在 i 这棵子树中,与点 i 距离最远的点距离 i 多远):
void dfs(int rt, int pre) {
f[rt][0] = 1;
for(edge *p=adj[rt];p!=NULL;p=p->nxt) {
if( p->to == pre ) continue;
dfs(p->to, rt);
for(int j=0;j<mxdep[p->to];j++)
ans += f[p->to][j]*g[rt][j+1];
for(int j=1;j<mxdep[p->to];j++)
ans += g[p->to][j]*f[rt][j-1];
for(int j=0;j<mxdep[p->to];j++)
g[rt][j+1] += f[p->to][j]*f[rt][j+1];
for(int j=1;j<mxdep[p->to];j++)
g[rt][j-1] += g[p->to][j];
for(int j=0;j<mxdep[p->to];j++)
f[rt][j+1] += f[p->to][j];
}
}
最后 ans 就是三元组的数量。
可以发现这个 dp 时间空间复杂度都为 O(n^2),对于这道题而言肯定过不了。
我们考虑优化。
@part - 2@
观察上面那段代码。最初进入这个循环时,除了 (f[rt][0]) 以外,其他与 rt 有关的数都为 0。
所以当最初进入循环时,实际有用的语句只有:ans += g[p->to][1],g[rt][j-1] += g[p->to][j] 与 f[rt][j+1] += f[p->to][j]。
第一条是 O(1) 的,直接搞就可以了。
而第二条相当于将 g 数组整体向左移动一位然后复制,第三条相当于将 f 数组整体向右移动一位然后复制。
让 rt 与 p->to 共用同一个数组,只是它们的数组头指针相差 1 位,第二条和第三条就是 O(1) 的了。
但是这种 O(1) 的转移仅仅只限于刚刚进入循环的那一次转移。其他的转移依然是暴力搞。
其实可以发现,这就是启发式合并的过程。
我们如果像平常一样,选取 size 最大的儿子作为 i 的重儿子,与 i 共用同一数组。则该算法的时间复杂度与空间复杂度就应该是标准的 O(nlog n)。
但是对于这种题,我们还可以采用独特的方法使时间复杂度与空间复杂度降为 O(n)。
也就是所谓的长链剖分。
具体来说,就是我们不再选取 size 最大的儿子作为 i 的重儿子,而是选取 mxdep(子树中与根距离最远的点距离根多远)最大的儿子作为 i 的重儿子。
为什么这样是 O(n) 的呢?
首先空间复杂度,基于我们的定义,每一条链所用的空间就是链长。所以总空间就为链长之和 <= 边数,就是 O(n) 的。
然后时间复杂度。我们对于每条边,如果这条边是重边相当于重儿子向父亲转移,是 O(1) 的;如果是轻边相当于一条重链向另一条重链转移,是 O(前一条链长)。
因为每一条重链只会唯一地向另一条重链转移,即一条重链顶端的那一条轻边,即轻边转移的总时间复杂度也是链长之和,也是 O(n) 的。
其实就是启发式合并,只不过我们平时合并按照子树大小来,这个长链剖分合并按照深度来。
@accepted code@
为了避免使用繁琐的指针,所以我的代码里面的实现是使用预处理给每个结点一个位置编号(有点像树链剖分),然后直接在同一个数组上作 dp。
#include<cstdio>
typedef long long ll;
const int MAXN = 100000;
struct edge{
int to; edge *nxt;
}edges[2*MAXN + 5], *adj[MAXN + 5], *ecnt;
void addedge(int u, int v) {
edge *p = (++ecnt);
p->to = v, p->nxt = adj[u], adj[u] = p;
p = (++ecnt);
p->to = u, p->nxt = adj[v], adj[v] = p;
}
int n, dcnt; ll ans;
ll f[MAXN + 5], g[2*MAXN + 5];//依照我的实现,g数组必须要开两倍大。
void init() {
for(int i=1;i<=n;i++) {
adj[i] = NULL;
f[i] = 0;
}
for(int i=1;i<=2*n;i++)
g[i] = 0;
ecnt = &edges[0]; ans = dcnt = 0;
}
int mxdep[MAXN + 5], hvy[MAXN + 5], fa[MAXN + 5], dep[MAXN + 5];
int dfs1(int rt, int pre) {
hvy[rt] = 0, fa[rt] = pre, dep[rt] = dep[pre] + 1;
for(edge *p=adj[rt];p!=NULL;p=p->nxt)
if( p->to != pre && dfs1(p->to, rt) > mxdep[hvy[rt]] )
hvy[rt] = p->to;
return mxdep[rt] = mxdep[hvy[rt]] + 1;
}
int top[MAXN + 5], tid[MAXN + 5], dfn[MAXN + 5];
void dfs2(int rt, int tp) {
top[rt] = tp; dfn[++dcnt] = rt; tid[rt] = dcnt;
if( !hvy[rt] ) return ;
dfs2(hvy[rt], tp);
for(edge *p=adj[rt];p!=NULL;p=p->nxt)
if( p->to != fa[rt] && p->to != hvy[rt] )
dfs2(p->to, p->to);
}
/*
void dfs(int rt, int pre) {
f[rt][0] = 1;
for(edge *p=adj[rt];p!=NULL;p=p->nxt) {
if( p->to == pre ) continue;
dfs(p->to, rt);
for(int j=0;j<mxdep[p->to];j++)
ans += f[p->to][j]*g[rt][j+1];
for(int j=1;j<mxdep[p->to];j++)
ans += g[p->to][j]*f[rt][j-1];
for(int j=0;j<mxdep[p->to];j++)
g[rt][j+1] += f[p->to][j]*f[rt][j+1];
for(int j=1;j<mxdep[p->to];j++)
g[rt][j-1] += g[p->to][j];
for(int j=0;j<mxdep[p->to];j++)
f[rt][j+1] += f[p->to][j];
}
}
*/
int pos[MAXN + 5];
void dfs3(int rt) {
f[tid[rt]]++;
if( hvy[rt] ) {
dfs3(hvy[rt]);
if( mxdep[hvy[rt]] > 1 ) ans += g[pos[hvy[rt]] + 1];
for(edge *p=adj[rt];p!=NULL;p=p->nxt) {
if( p->to == fa[rt] || p->to == hvy[rt] ) continue;
dfs3(p->to);
for(int i=0;i<mxdep[p->to];i++)
ans += f[tid[p->to] + i] * g[pos[rt] + i + 1];
for(int i=1;i<mxdep[p->to];i++)
ans += g[pos[p->to] + i] * f[tid[rt] + i - 1];
for(int i=0;i<mxdep[p->to];i++)
g[pos[rt] + i + 1] += f[tid[p->to] + i] * f[tid[rt] + i + 1];
for(int i=1;i<mxdep[p->to];i++)
g[pos[rt] + i - 1] += g[pos[p->to] + i];
for(int i=0;i<mxdep[p->to];i++)
f[tid[rt] + i + 1] += f[tid[p->to] + i];
}
}
}
int main() {
scanf("%d", &n);
init();
for(int i=1;i<n;i++) {
int x, y;
scanf("%d%d", &x, &y);
addedge(x, y);
}
dfs1(1, 0); dfs2(1, 1);
int tot = 1;
for(int i=1;i<=n;) {
int p = mxdep[dfn[i]];
for(int j=i+p-1;j>=i;j--)
pos[dfn[j]] = tot, tot++;
tot += p, i += p;
}
dfs3(1);
printf("%lld
", ans);
}
@details@
长链剖分算是一种小 trick 吧,能够将深度有关的东西通过启发式合并的思想(继承信息)降低时间复杂度。
很神奇的是它居然是 O(n) 的。这年头居然还有 O(n) 的优化算法?