接上篇第一部分
-
GEOMetrics, 网格模型是一种编码三维物体的有效方式,图编码的几何结构可以提供三维物体的重建效果。通过图卷积来保留定点信息,并利用自适应刨分启发式的融合,同时训练了由定点定义的局部表面和由网格定义的全局结构。(from McGill University, Montreal)
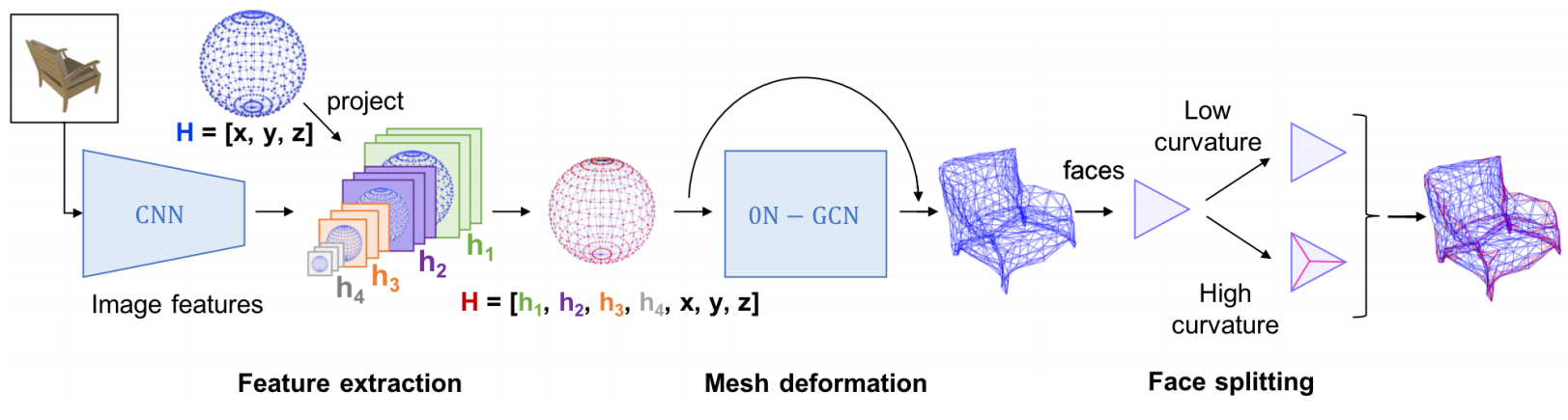
三维图形不同的编码方式及其效率:

网格到定点的映射:
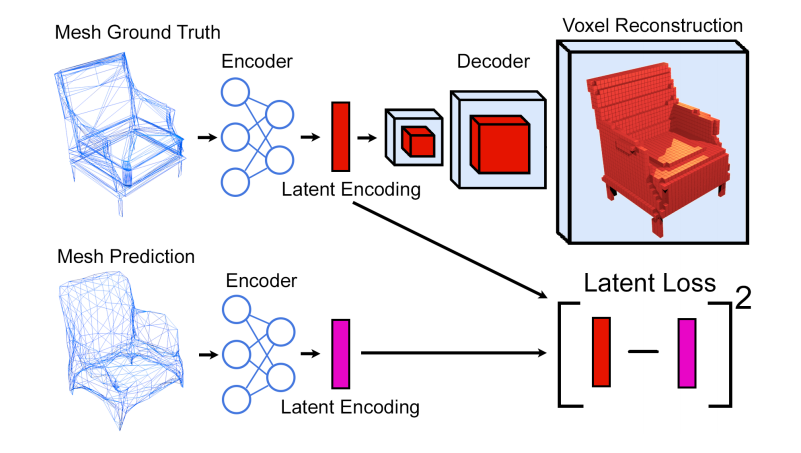
一些结果:

代码:https://github.com/EdwardSmith1884/GEOMetrics
ref:pixels2mesh, code -
MONet, 提出了一种多目标网络用于场景中目标的解构和理解,能够语义地理解出场景中的物体背景,识别出场景中的物体结构并用通用的方式表达出来。(from deepming)
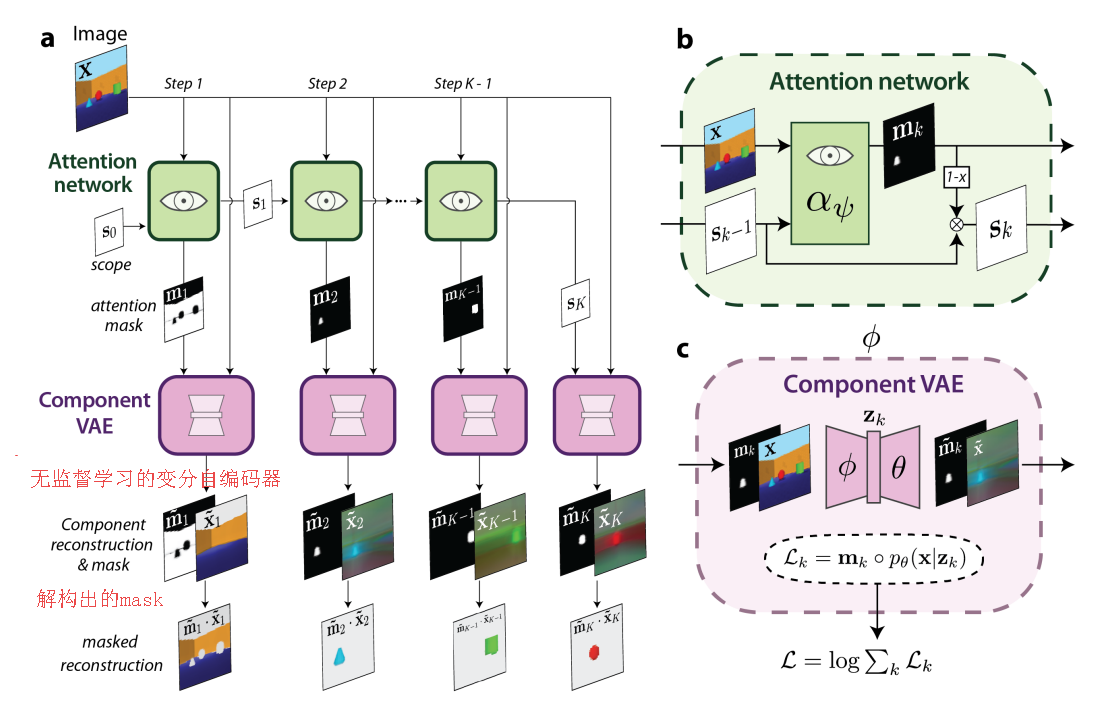
重建和语义mask:
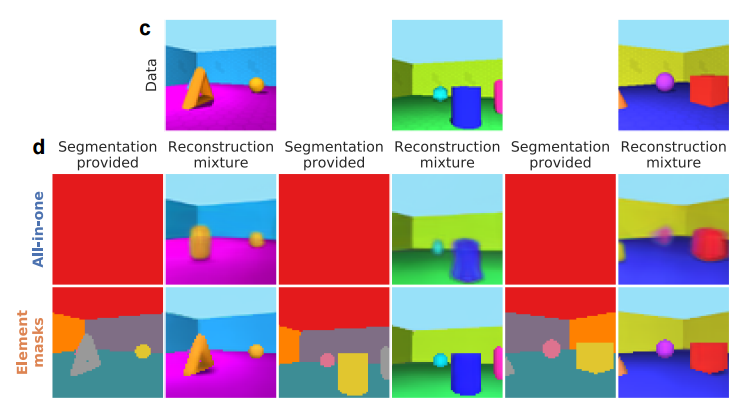
数据集:
Objects Room dataset
Multi-dSprites
CLEVR dataset -
Noise2Self, 自监督的盲去噪方法。在无需信号先验、无需噪声估计和无需干净训练数据的情况下实现高维度去噪声。仅仅假设噪声在测量上具有独立的统计分布,并且具有广泛的适应性。作者在显微镜数据和自然图像上进行了验证。同事在单细胞的基因表达数据上也进行了验证。
(from Chan-Zuckerberg Biohub)

一些效果:

code:https://github.com/czbiohub/noise2self
相关方法:
SmoothnessSelf-SimilarityGenerativeGaussianitySparsityCompressibilityStatistical Independence
0.NLM and BM3D,
1.trained withclean targets (Noise2Truth)
2.with independently noisy targets (Noise2Noise)
3.purely convolutional architecture with clean targets (DnCNN)
盲去噪参考文献
natural dataset: HANZI IMAGENET CELLNET -
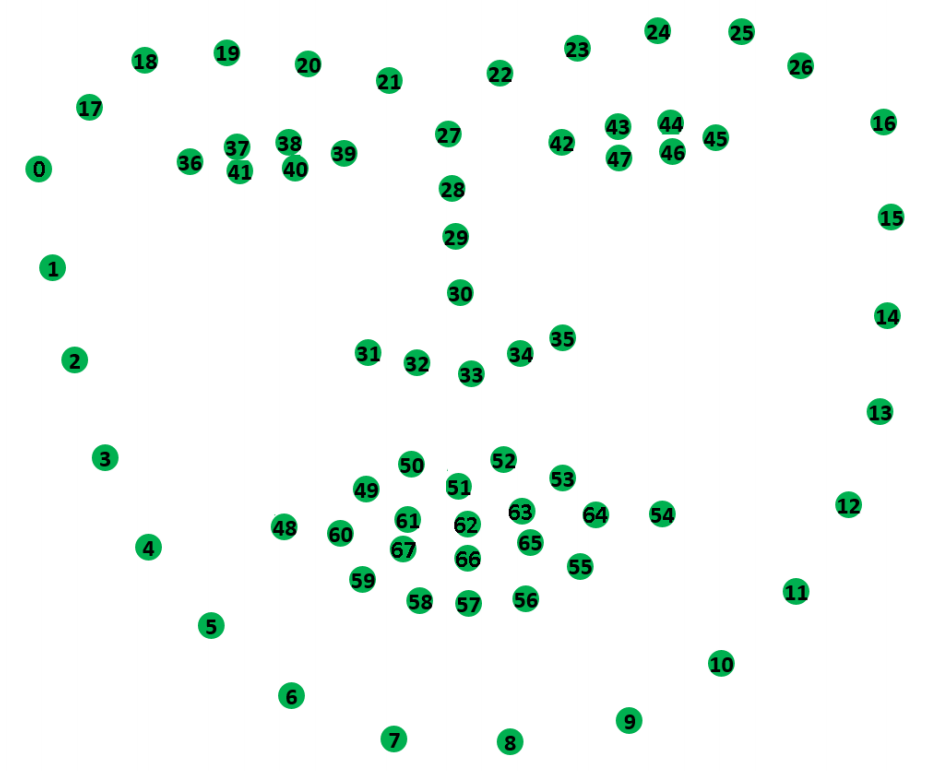
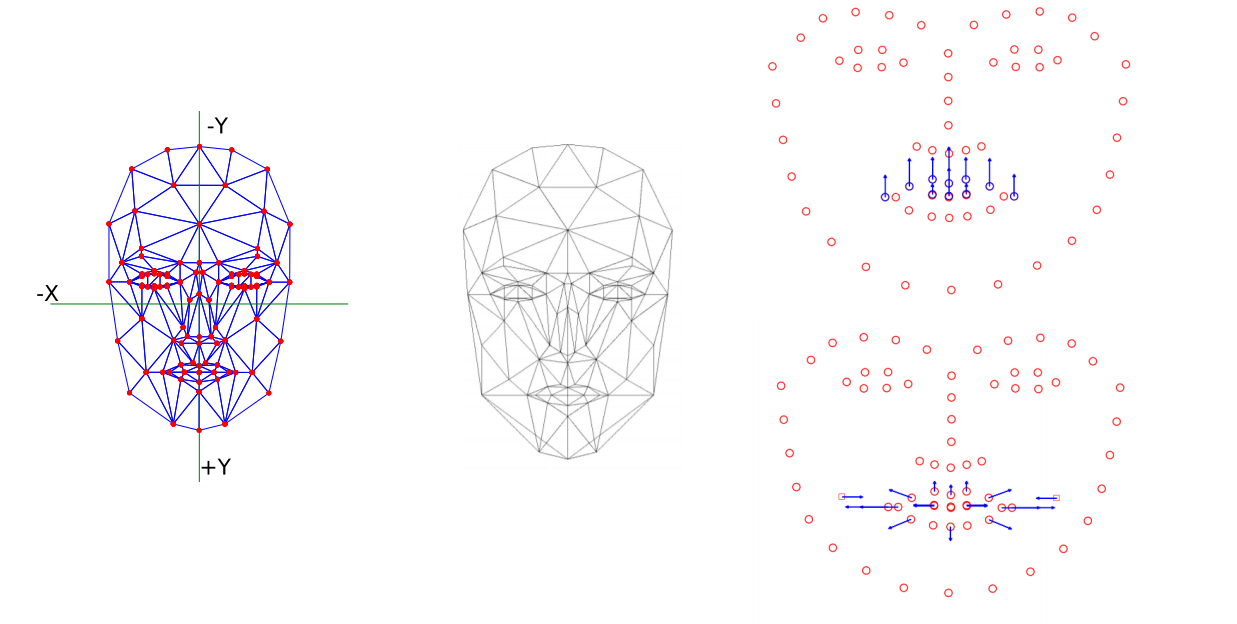
人脸表情识别评测,人脸识别中的四种表情分为微笑、惊奇、生气和自然。在特征抽取阶段,有基于静态二维面部特征的68关键点法、有基于三维动态几何描述的运动参数AU8个性化Candide-3模型、还有基于灰度描述子的描述方法。在分类阶段一般基于cnn和支持向量机两种形式。(from 华沙大学)
68关键点模型:
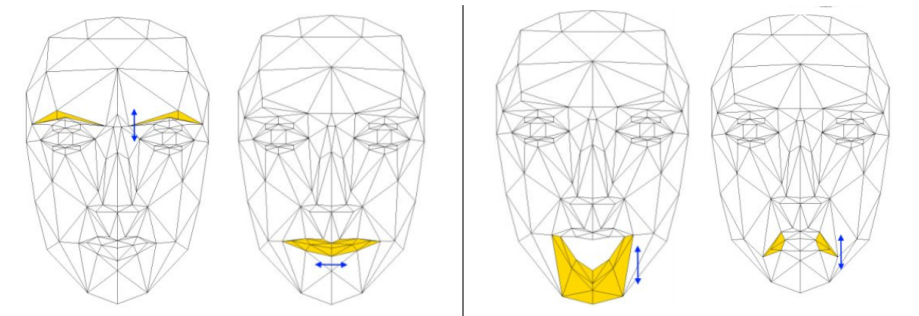
AU10/AU20面目运动模型:
不同表情的运动矢量:

ref:人脸68关键点数据集:300W, 300VW, IBUG
-
TUNet,利用分割图促进荧光显微镜下的蛋白分类。(from 纽约大学)
荧光显微镜细胞数据集: Cell Atlas, FlowRepository -
荧光显微图像的三维传播和时间反演,基于单张二维的荧光图像可以利用数据驱动的方法生成三维图像,而无需扫描。(from UCLA)
-
结合稀疏编码的可解释性GAN,通过稀疏激活在提出的gan模型上得到了多层级有意义的特征表示。从底到顶的卷积核可以在不同层的作用后学习到边缘、颜色、物体部分和整体。同时提出了稀疏编码和与或语法用于图像处理。(from HIT)
具有稀疏激活的gan:
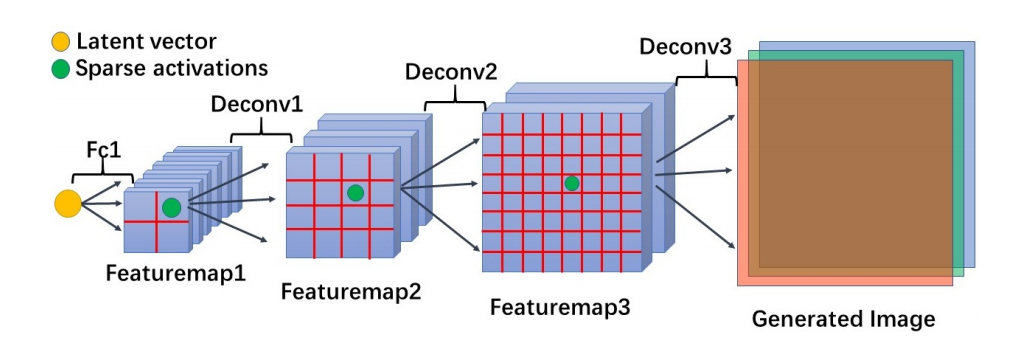
底部特征和顶部特征,具有可解释的不同层级:

and和or为最后生成图的贡献:

one more thing:
土壤(硫酸盐)数据集:https://catalogue.data.wa.gov.au/dataset/activity/acid-sulfate-soil-risk-map-50k
zappos50k鞋类数据集:http://vision.cs.utexas.edu/projects/finegrained/utzap50k/ 适合用于GAN 娱乐~~
