Few-shot Learning for Named Entity Recognition in Medical Text
小样本学习第一篇
文献地址:https://arxiv.org/abs/1811.05468
电子健康记录很重要,但是都是自然语言形式,解锁这些信息有重大意义。长短期记忆(LSTM)类型的递归神经网络(RNN)和卷积神经网络(CNN)的组合已成功应用于为基于CoNLL的NER任务,并达到当前的最佳性能,神经网络的主要局限在于需要大量带注释文本,对于电子健康记录很麻烦。因此,在几乎没有注释的示例可用时,改善神经网络的性能仍然是生物医学研究中的高度优先事项。
我们首先设定目标,以在i2b2 2009的NER任务上优化性能,同时仅使用10个随机选择的带注释的释出的摘要。从69.3%优化到78.87%
CoNLL2003包含英语新闻专栏文章,并注明不属于前三类中任何一组的人员,位置,组织和杂项名称
数据
- i2b2 2009 用于监督训练测试
- i2b2 2010&2012 CoNLL-2003用于预训练权重
- 其他三个用于词嵌入
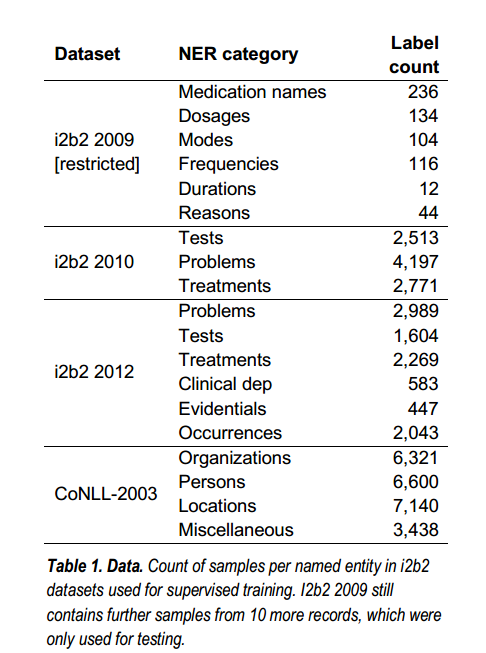
而在以无监督方式使用的数据集中,原始注释被忽略(请参见表2)。 我们已将i2b2b 2009数据限制为仅从完整训练数据集中抽取的10个随机样本。
基线模型
(1)Single pre-training:使用其它单个数据集分别预训练,并设置了对比实验:所有层使用预训练权重、仅BLSTM使用、所有层除BLSTM、不使用预训练权重。
(2)Hyperparameter tuning:包括optimizers、pre-training dataset、SGD learning rate、batch normalization(是否使用)、word embedding(是否trainable)以及learning rate decay (constant or time scheduled)。
(3)Combined pre-training:利用多个数据集串联预训练模型,并在目标数据集训练时加载权重。
(4)Customized word embeddings:word embedding是否使用GloVE或者在医药数据集上重新用FastText训练。
(5)Optimizing OOV words:Remove trailing “:”, “;”, “.” and “-”、Remove quotations、Remove leading “+”
2.3单一预训练
网络参数分别针对三个不同的NER任务中的每一个进行了预训练,其中两个与目标任务属于同一个域(i2b2 2010和i2b2 2012,医学文本),而一个属于不同的域(CoNLL-2003, 非医学文字)。
比较了三种不同的初始化策略:用预训练的权重初始化所有层; 仅初始化图层merge_BLSTM(其他图层随机初始化); 并初始化除merge_BLSTM以外的所有内容(merge_BLSTM随机初始化)。 在所有情况下,words_input的嵌入都不会经过训练,而是冻结为GloVE的值。
2.4超参数调整
- 优化器SGD or Nadam
- 训练数据集i2b2 2010 or 2012
- SGD学习率0.04 or 0.08
- batch normalization (with or without)
- weights of layer ‘words_input’
trained on the objective task or frozen to GloVE values
2.5合并预训练
为了测试我们的目标任务是否受益于联合预训练,现在我们结合了从i2b2 2010和2012进行学习。这是通过在两个可能的方向上依次从每个数据集学习来实现的:首先在i2b2 2010上训练随机初始化的模型, 然后继续在i2b2 2012上进行训练; 或先在2010年再在2012年进行训练。 无论哪种情况,在进行客观任务训练时,将从第二轮训练中获得的最终权重用作初始值。
2.6
大概说GloVE可能不准,要自己训练。我们的第四项改进包括开发在CRIS,MIMIC III或BioNLP-2016上训练过的自己的词嵌入。
2.7优化OOV words
我们的最后一项改进是在文本预处理中添加了以下两个步骤:
删除尾随的“:”,“;”,“。” 和“-”。
删除引号
删除开头的“ +”
3.1
words_input 用GloVE初始化,char和case的input随机初始化U(-0.5,0.5)。所有其他参数都是根据Keras(版本2.2.0)默认值随机初始化的。分成64批次。 Nadam 69.3%
3.2
通过在i2b2 2010上进行预训练(平均F1比基线增加+ 3.06%)或在i2b2 2012上进行的图层初始化(+ 1.58%)表现要好于在CoNLL-2003上进行预训练的权重(+ 0.52%),并且比随机初始化的权重还好 (69.3%)。 此外,初始化所有层都比仅初始化BLSTM(71.21%)或除BLSTM层之外的所有其他初始化项(70.65%)更好。
3.3
调整超参数是第二项经过测试的改进,它是通过单次预训练在性能最佳的模型上实施的。
在所有评估的超参数中,影响最大的是优化器,Nadam平均达到70.41%,SGD 50.56%。 第二个最重要的超参数是用于神经网络预训练的数据,其中i2b2 2010达到+ 2.34%,i2b2 2012达到+ 1.58%。 如图3所示,其他超参数(批处理规范化,可训练的嵌入,学习率和学习率衰减)的影响尚无定论。因此,我们将优化器固定为Nadam并继续使用i2b2 2010进行预训练,而拒绝使用其他参数。 超参数更改。