事务实现原则
事务:数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。 事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。事务是数据库运行中的逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。
随着计算机应用的告诉发展,伴随着大量业务系统的改造,从简单的单机到分布式应用的部属,事务一致性问题伴随发展,包括:
- 数据并发访问、修改。
- 不同请求之间的数据隔离
- 多个服务共同完成一个业务请求,保证都完成或者都失败
- 发生异常时的数据回滚
举一个例子:张三给李四转账100元

这个操作必须是统一完成的,任何一方修改都不能完成事务的提交,否则造成数据不一致。
在传统的操作中大多数都是JDBC事务的操作:
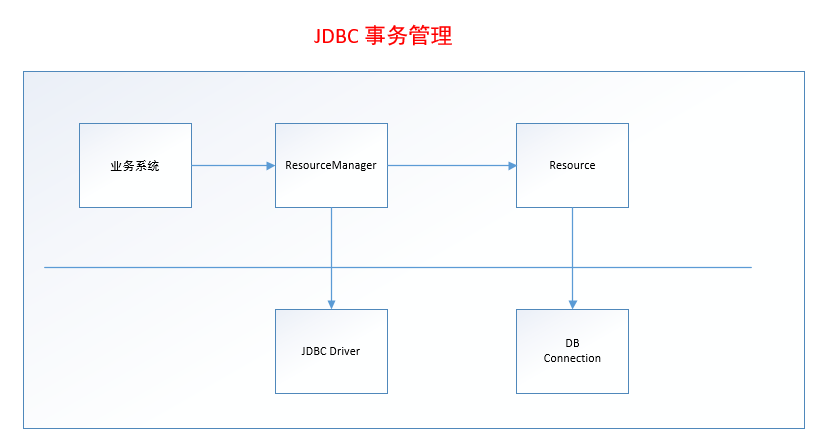
之前在开发中使用的JDBC操作如下代码所示:
import java.sql.*; import java.util.LinkedList; import java.util.List; /** * JDBC辅助组件 * * 在代码中,是不能出现任何hard code(硬编码)的字符 * 比如“张三”、“com.mysql.jdbc.Driver” * 所有这些东西,都需要通过常量来封装和使用 * * * */ public class JDBCHelper { // 第一步:在静态代码块中,直接加载数据库的驱动 // 加载驱动,不是直接简单的,使用com.mysql.jdbc.Driver就可以了 // 之所以说,不要硬编码,他的原因就在于这里 // // com.mysql.jdbc.Driver只代表了MySQL数据库的驱动 // 那么,如果有一天,我们的项目底层的数据库要进行迁移,比如迁移到Oracle // 或者是DB2、SQLServer // 那么,就必须很费劲的在代码中,找,找到硬编码了com.mysql.jdbc.Driver的地方,然后改成 // 其他数据库的驱动类的类名 // 所以正规项目,是不允许硬编码的,那样维护成本很高 // // 通常,我们都是用一个常量接口中的某个常量,来代表一个值 // 然后在这个值改变的时候,只要改变常量接口中的常量对应的值就可以了 // // 项目,要尽量做成可配置的 // 就是说,我们的这个数据库驱动,更进一步,也不只是放在常量接口中就可以了 // 最好的方式,是放在外部的配置文件中,跟代码彻底分离 // 常量接口中,只是包含了这个值对应的key的名字 static { try { String driver = ConfigurationManager.getProperty(Constants.JDBC_DRIVER); Class.forName(driver); } catch (Exception e) { e.printStackTrace(); } } // 第二步,实现JDBCHelper的单例化 // 为什么要实现代理化呢?因为它的内部要封装一个简单的内部的数据库连接池 // 为了保证数据库连接池有且仅有一份,所以就通过单例的方式 // 保证JDBCHelper只有一个实例,实例中只有一份数据库连接池 private static JDBCHelper jdbcHelper = null ; /** * 获取单利 * @return */ public static JDBCHelper getInstance(){ if(jdbcHelper == null){ synchronized (JDBCHelper.class){ if(jdbcHelper == null) jdbcHelper = new JDBCHelper(); } } return jdbcHelper; } // 创建数据库连接池 private LinkedList<Connection> datasource = new LinkedList<Connection>(); /** * 通过构造方法 :实现单例的过程中,创建唯一的数据库连接池 * 创建指定数量的连接池 */ private JDBCHelper(){ int datasourceLength = ConfigurationManager.getInteger("Constants.JDBC_DATASOURCE_SIZE"); for (int i=0;i<datasourceLength;i++){ String url = ConfigurationManager.getProperty(Constants.JDBC_URL); String user = ConfigurationManager.getProperty(Constants.JDBC_USER); String password = ConfigurationManager.getProperty(Constants.JDBC_PASSWORD); try { Connection connection = DriverManager.getConnection(url,user,password); datasource.push(connection); } catch (SQLException e) { e.printStackTrace(); } } } /** * 提供获取数据库连接方法 */ public synchronized Connection getConnection(){ /** * 如果连接用完了,则等待等候 */ while(datasource.size() == 0){ try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } } return datasource.poll(); } /** * CRUD 封装 */ /** * 数据更新 * @param sql * @param params * @return */ public int executeUpdate(String sql, Object[] params) { int rtn = 0; Connection conn = null; PreparedStatement pstmt = null; try { conn = getConnection(); pstmt = conn.prepareStatement(sql); for(int i = 0; i < params.length; i++) { pstmt.setObject(i + 1, params[i]); } rtn = pstmt.executeUpdate(); } catch (Exception e) { e.printStackTrace(); } finally { if(conn != null) { datasource.push(conn); } } return rtn; } /** * 数据查询 * @param sql * @param params * @param callback */ public void executeQuery(String sql, Object[] params, QueryCallback callback) { Connection conn = null; PreparedStatement pstmt = null; ResultSet rs = null; try { conn = getConnection(); pstmt = conn.prepareStatement(sql); for(int i = 0; i < params.length; i++) { pstmt.setObject(i + 1, params[i]); } rs = pstmt.executeQuery(); callback.process(rs); } catch (Exception e) { e.printStackTrace(); } finally { if(conn != null) { datasource.push(conn); } } } /** * 批量执行SQL语句 * * 批量执行SQL语句,是JDBC中的一个高级功能 * 默认情况下,每次执行一条SQL语句,就会通过网络连接,向MySQL发送一次请求 * * 但是,如果在短时间内要执行多条结构完全一模一样的SQL,只是参数不同 * 虽然使用PreparedStatement这种方式,可以只编译一次SQL,提高性能,但是,还是对于每次SQL * 都要向MySQL发送一次网络请求 * * 可以通过批量执行SQL语句的功能优化这个性能 * 一次性通过PreparedStatement发送多条SQL语句,比如100条、1000条,甚至上万条 * 执行的时候,也仅仅编译一次就可以 * 这种批量执行SQL语句的方式,可以大大提升性能 * * @param sql * @param paramsList * @return 每条SQL语句影响的行数 */ public int[] executeBatch(String sql, List<Object[]> paramsList) { int[] rtn = null; Connection conn = null; PreparedStatement pstmt = null; try { conn = getConnection(); // 第一步:使用Connection对象,取消自动提交 conn.setAutoCommit(false); pstmt = conn.prepareStatement(sql); // 第二步:使用PreparedStatement.addBatch()方法加入批量的SQL参数 for(Object[] params : paramsList) { for(int i = 0; i < params.length; i++) { pstmt.setObject(i + 1, params[i]); } pstmt.addBatch(); } // 第三步:使用PreparedStatement.executeBatch()方法,执行批量的SQL语句 rtn = pstmt.executeBatch(); // 最后一步:使用Connection对象,提交批量的SQL语句 conn.commit(); } catch (Exception e) { e.printStackTrace(); } return rtn; } /** * 内部类,需要处理查询结果 */ public static interface QueryCallback{ /** * 处理查询结果 * @param rs * @throws Exception */ void process(ResultSet rs) throws Exception; } }