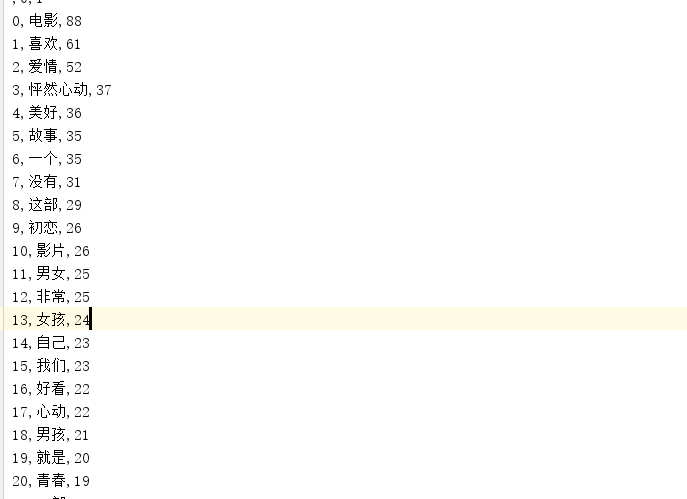
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:duymgzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)


保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
我感兴趣的主题:最近重温怦然心动电影,爬取其评论
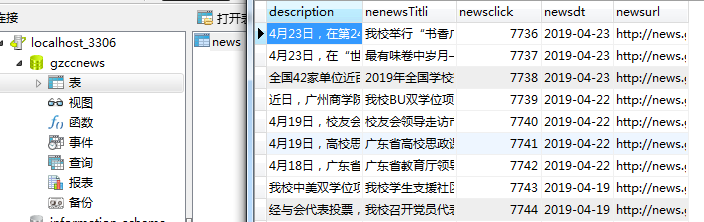
爬取对象:猫眼http://m.maoyan.com/movie/46818?_v_=yes&channelId=4&cityId=20&$from=canary#
获取的是猫眼APP的评论数据,如图所示::
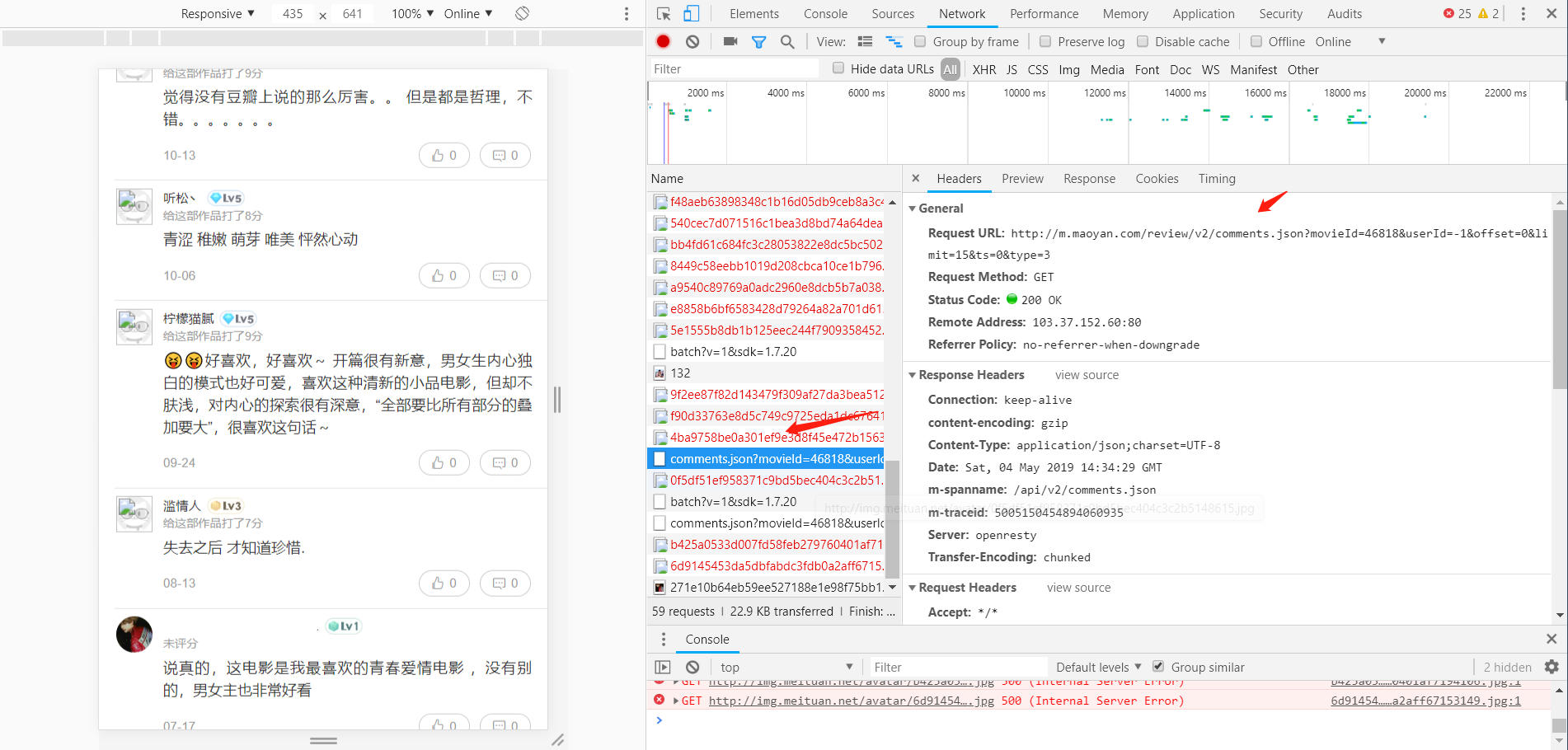
通过分析发现猫眼APP的评论数据接口为:http://m.maoyan.com/review/v2/comments.json?movieId=46818&userId=-1&offset=0&limit=15&ts=0&type=3
多次观察发现:


只需要改变ts的值就能获取到数据,每次返回的数据的后端的ts就是下一页的ts,改变的就是offset和ts的值:
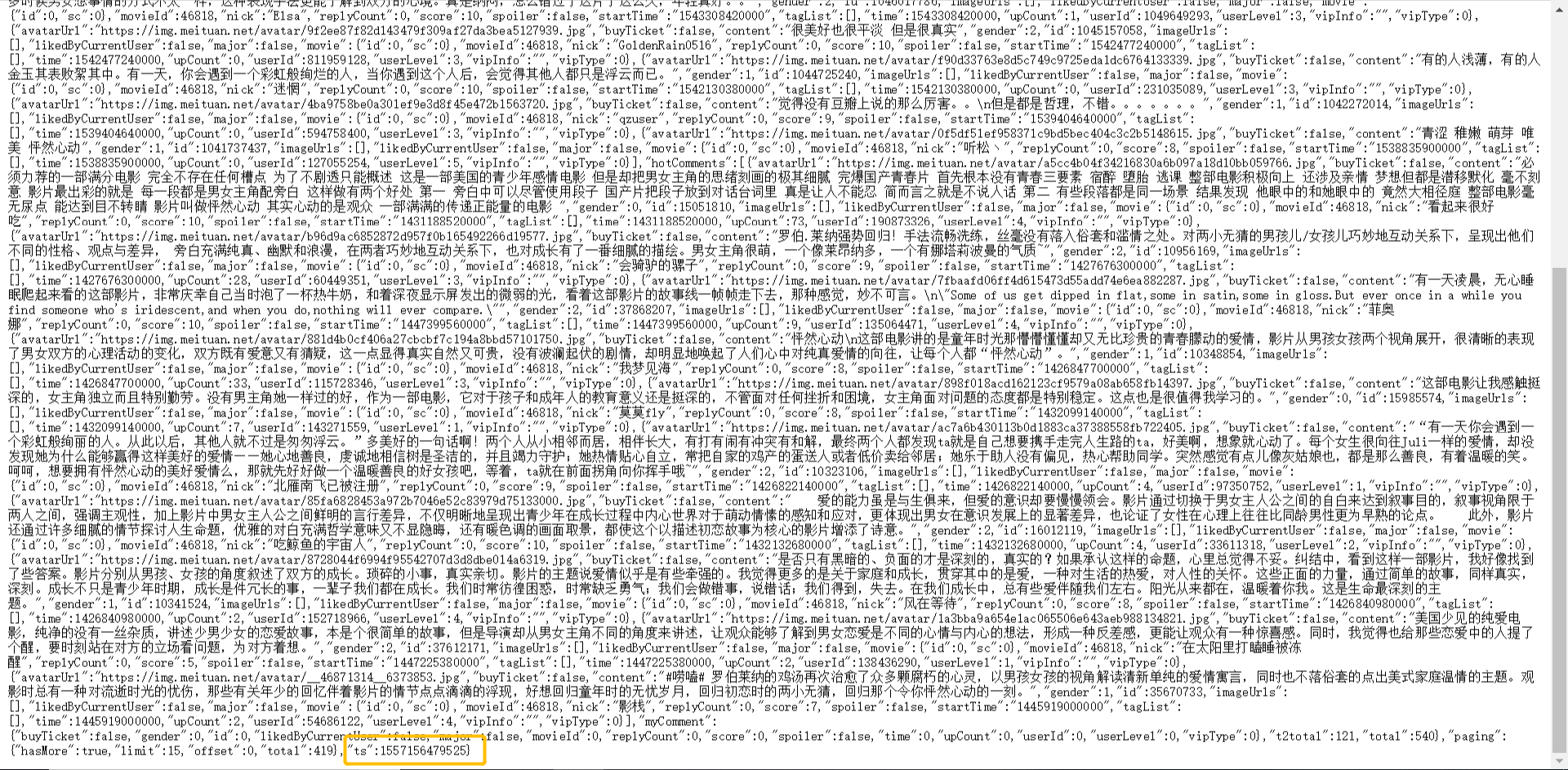
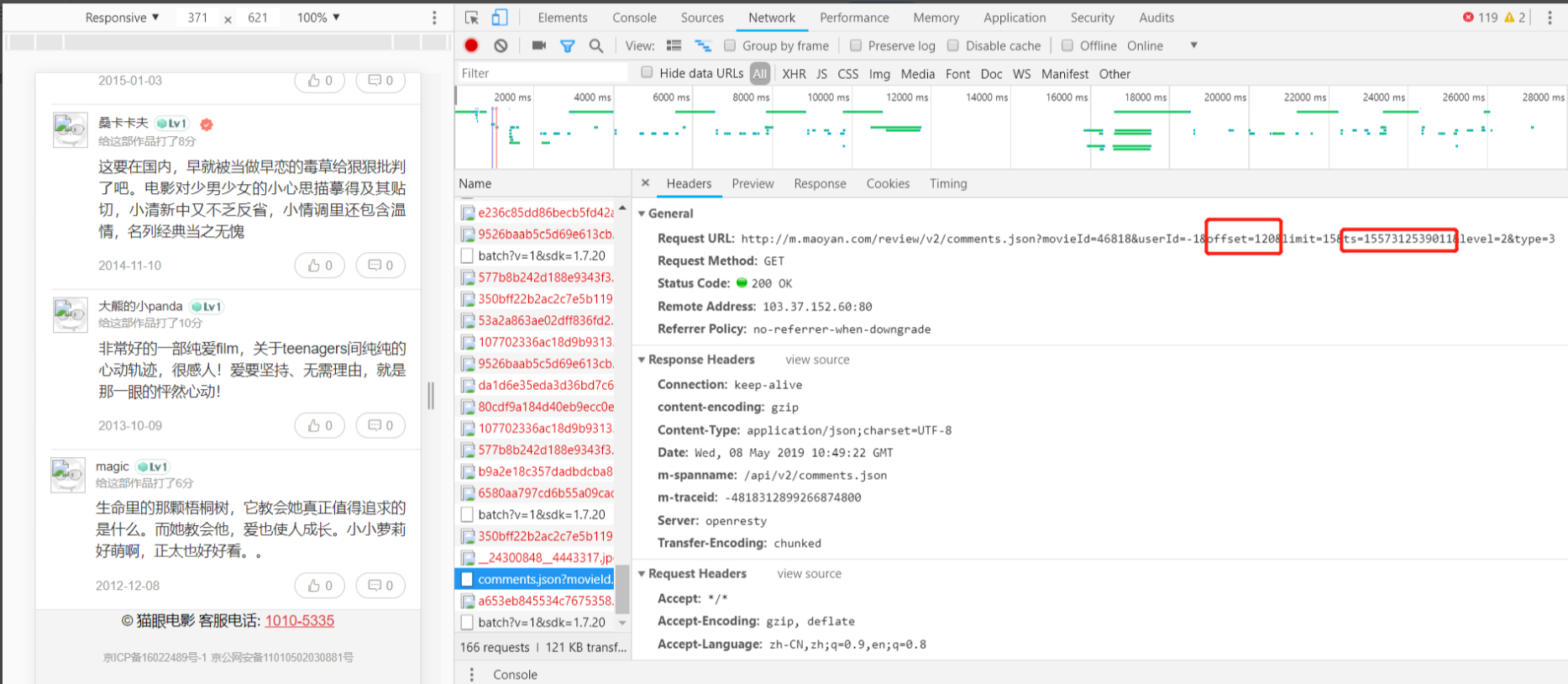
所以只需要更新offset的值就能获取每页的评论数据
代码实现:
2019/5/7
获取数据代码
from bs4 import BeautifulSoup import requests import json import random import time import pandas as pd headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Mobile Safari/537.36', } # url设置offset偏移量为0 url = 'http://m.maoyan.com/review/v2/comments.json?movieId=46818&userId=-1&offset=0&limit=15&type=3&ts={}' comment = [] nick = [] score = [] comment_time = [] gender = [] userlevel = [] userid = [] upcount = [] replycount = [] list_=[] ji = 1 ts = 0 # 获取当前时间(单位是毫秒,所以要✖️1000) #offset最大值1005 for t in range(1000): url = 'http://m.maoyan.com/review/v2/comments.json?movieId=46818&offset={}&type=3' url_range = url.format(t) print(url_range) try: res = requests.get(url_range, headers=headers) res.encoding = 'utf-8' print('正在爬取第' + str(ji) + '页') content = json.loads(res.text,encoding='utf-8') print(content) comments = content['data']['comments'] except Exception as e: print("出错") count = 0 for item in comments: comment.append(item['content']) nick.append(item['nick']) score.append(item['score']) count=count+1 ji = ji+1 print('=======================') ts= content['ts'] print(content['ts']) print('=======================') time.sleep(3) print('爬取完成') print(ts) print(comment) print(score) pd.DataFrame(nick).to_csv('bigdata.csv',encoding='utf_8_sig') pd.DataFrame(comment).to_csv('neirong.csv',encoding='utf_8_sig') pd.DataFrame(score).to_csv('pingfen.csv',encoding='utf_8_sig')
爬取到的数据:

整理数据:
# coding=utf-8 # 导入jieba模块,用于中文分词 import jieba # 获取所有评论 import pandas as pd # 读取小说 f = open(r'评论内容.csv', 'r', encoding='utf8') text = f.read() f.close() print(text) ch="《》 :,,。、-!?0123456789" for c in ch: text = text.replace(c,'') print(text) newtext = jieba.lcut(text) te = {} for w in newtext: if len(w) == 1: continue else: te[w] = te.get(w, 0) + 1 tesort = list(te.items()) tesort.sort(key=lambda x: x[1], reverse=True) # 输出次数前TOP20的词语 for i in range(0, 20): print(tesort[i]) pd.DataFrame(tesort).to_csv('xin.csv', encoding='utf-8')
生成词云图:
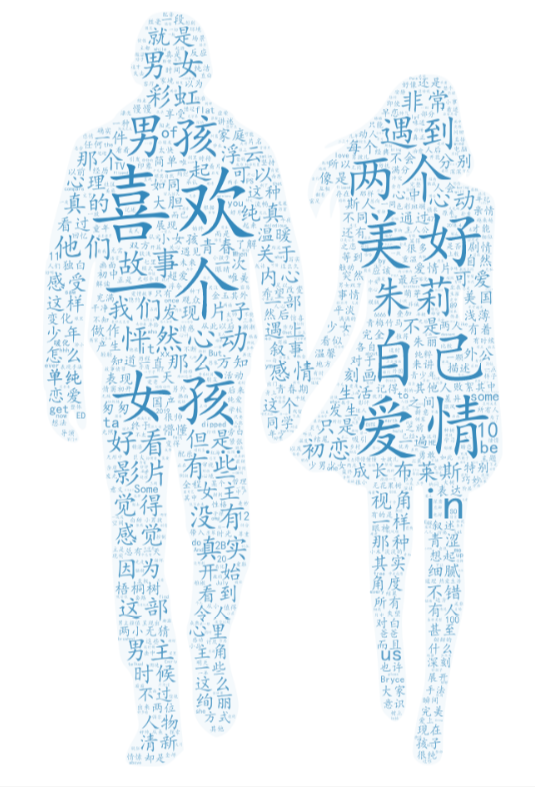
大概从词云图可以推出,讲述一段美好的爱情小故事。
整理评分数据:
# coding=utf-8 fen=[] # 获取评论中所有评分 with open('pingfen.csv', mode='r', encoding='utf-8') as f: row1=f.readlines() for row2 in row1: fen.append(row2.split(',')[1]) print(row2) print(fen) zong=fen.__len__() print(zong) value=[fen.count('7 '),fen.count('8 '),fen.count('9 '),fen.count('10 ')] print(value)

十分好评的人数有477人,八九十分合起来有980人
整体而言,这部电影是非常值得大家观赏的一部好看的电影
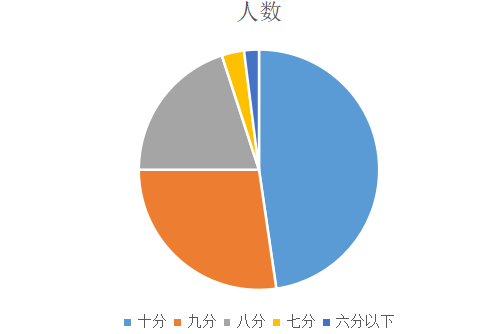
评分人数的图表,从人数来看可以看出这是一部经典好电影。