学习javascript的时候曾经想做一个留言板的应用,但是却由于不知道如何存储失败了,由于做这个留言板的思路类似于C语言的学生管理系统,故此这次经历让我重新审视自己去学懂C语言的文件操作。
我重新用C语言写了一个留言板系统,当时学习C的时候被学生管理的课设折腾的死去活来,但后来才知道,其实不管是飞机订票还是留言还是学生管理,这类课程设计本质上都要求你用语言去实现一个CRUD完备的应用系统,设计这种系统实际上是一种基本功,而这种系统如果再加上网络通信以及存储(文件或者数据库),就可以称为真正的软件。
废话不多说,代码结构如下:
main.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#include "function.h"
#include "LinkList.h"
int main()
{
LNode L;
InitList(&L);
loadFromFile(&L);
while (1)
{
switch (menu())
{
case 1:
add(&L); //1.添加评论功能
break;
case 2:
view(&L); //2.浏览所有评论
break;
case 3:
del(&L); //3.删除评论
break;
case 4:
modify(&L); //4.修改评论
break;
case 5:
exit(0);
default:
fflush(stdin);
printf("请勿暴力测试!
");
break;
}
}
}
function.h 负责应用的功能实现,要用到链表
#ifndef FUNCTION_H_
#define FUNCTION_H_
#include"LinkList.h"
int menu(); //荣单,每次功能使用结束后翻会调用讯视频 图片
void loadFromFile(LNode *L); //从文件加载数据
void saveToFile(LNode *L); //保存数据到文件中
void s_gets(char *srcText); //处理输入的字符串
void printOne(LNode *p) ;//用于单条评论的打印
void add(LNode *L); //添加评论功能
void view(LNode *L); //浏览所有评论
void del(LNode *L) ; //删除评论
void modify(LNode *L); //修改评论
#endif
LinkList.h 链表的设计
#ifndef LINKLIST_H_
#define LINKLIST_H_
#define MAX_SIZE 100
struct comment //学生的数据,目前只有评论,可再扩展出学号,用户名,日期等信息
{
char text[MAX_SIZE];
};
typedef struct LNode //学生的数据用链表存储
{
struct comment comment;
int id; //节点序号
struct LNode *prev;
struct LNode *next;
} LNode;
LNode *head;
LNode *tail;
void InitList(LNode *L); //初始化链表
LNode *InsList_FromTail(LNode *L); //尾插法添加链表
LNode *InsList_FromHead(LNode *L); //头插法添加链表
int ListLength(LNode head); //测量表长度
void DelList(int index, LNode *L); //按序号删除链表
#endif
C语言对文件通信提供了四种函数:fprintf, fscanf, fread,fwrite。
方法一:fprintf和fscanf
起初的思路是使用fprintf和fscanf,每次添加评论时用一个整形变量datalen统计数据长度并将数据写入文件,最后将datalen写入另一个文件中存储起来;
而读取文件时,按照datalen的大小重新构造链表,并将文件的相关数据重新填入链表。
但这样有很多不便性,对于存储了评论的文件, 要十分关注文件指针在文件中的位置,换行符等特殊字符对文件读取的影响( 在文件中被fp视为2个字符),在用链表存取的成员值只有一两个时还好,要是评论还有用户名,发言时间,地点等更多的属性时,不仅每次都要修改代码,由于数据是以文本显示,届时用文件指针读入数据,乃至稳定显示数据将是一个复杂的挑战,
但我还是动手实践了一下,借此经历我复习了这两个函数的用法以及文件指针如何操作:
(此外还把《C Primer Plus》中统计行数,词数的程序重新实践了一遍)
伪代码表示为:
loadFromFile函数:
打开数据文件data.txt和记录数据长度的文件len.txt
如果打不开,程序返回错误,反之程序继续执行
从len.txt获取文件长度datalen
for(i->datalen),
每次用头插法构建一个新节点表,就从data.txt获取一个节点的评论数据
将数据导入到新建的节点中
导入完毕,关闭文件
saveFromFile 函数:
检查是否能打开数据文件data.txt
向里面覆写链表中的所有数据,同时记录数据长度
覆写完毕后关闭文件,数据保存到磁盘文件内
void loadFromFile(LNode *L) //从文件加载数据
{
LNode *p;
FILE *fp,*num;
int i, datalen;
char line[MAX_SIZE];
if ((fp = fopen(filePath, "r")) == NULL)
{
fprintf(stdout, "Can't Open data file,Read failed
");
exit(EXIT_FAILURE);
}
else if ((num = fopen(lenPath, "r")) == NULL)
{
fprintf(stdout, "Can't Open data file,Read failed
");
exit(EXIT_FAILURE);
}
else
{
fprintf(stdout, "数据文件读取成功!
");
}
fscanf(num, "%d", &datalen); //从文件开头获取数据长度
printf("当前评论数: %d条
", datalen);
for (i = 0; i < datalen; i++) //根据数据长度重建链表并赋值
{
p = InsList_FromTail(L); //id,前后指针是链表的固有属性,但comment不是,所以需要赋值
fgets(line,MAX_SIZE,fp);
strcpy(p->comment.text, line);
}
fclose(num);
fclose(fp);
}
void saveToFile(LNode *L) //保存数据到文件中
{
FILE *fp = NULL,*num = NULL;
LNode *p;
int datalen = 0; //统计数据量
if ((fp = fopen(filePath, "w+")) == NULL)
{
fprintf(stdout, "Can't Open data file,Read failed
");
exit(EXIT_FAILURE);
}
else if ((num = fopen(lenPath, "w+")) == NULL)
{
fprintf(stdout, "Can't Open data file,Read failed
");
exit(EXIT_FAILURE);
}
for (p = L->next; p != NULL; p = p->next)
{
fprintf(fp, "%s", p->comment.text); //将每个节点的所有数据依次写入文件
datalen++;
}
fprintf(num, "%d", datalen); //用另一个文件标记数据的长度
fclose(num);
fclose(fp);
}
方法二 :fread和fwrite
基本步骤和思路一类似,只不过操作对象从文本变为了二进制数据,得以直接规定用每个节点大小的数据块去写入文件以及赋值给结构体comment,而且由于可用feof判断临界条件,故也不需要用datalen判断数据量了,且comment的结构体成员变动时也不需改代码,整体上方便了许多;
代码如下:
void loadFromFile(LNode *L) //从文件加载数据
{
LNode *p, *newNode;
FILE *fp;
int order = 1;
char line[MAX_SIZE];
p = L;
if ((fp = fopen(filePath, "rb")) == NULL)
{
fprintf(stdout, "Can't Open data file,Read failed
");
exit(EXIT_FAILURE);
}
else
{
fprintf(stdout, "数据文件读取成功!
");
}
while (1)
{
newNode = (LNode *)malloc(sizeof(LNode));
fread(&newNode->comment, sizeof(comment), 1, fp);
if (feof(fp))
break;
p->next = newNode;
newNode->prev = p;
newNode->id = order++;
newNode->next = NULL;
p = newNode;
}
fclose(fp);
}
void saveToFile(LNode *L) //保存数据到文件中
{
FILE *fp;
LNode *p;
if ((fp = fopen(filePath, "w+b")) == NULL)
{
fprintf(stdout, "Can't Open data file,Read failed
");
exit(EXIT_FAILURE);
}
else
{
fprintf(stdout, "数据文件读取成功!
");
}
if (L->next != NULL)
{
for (p = L->next; p != NULL; p = p->next)
{
fwrite(&p->comment, sizeof(comment), 1, fp); //依次把各结点数据"倒入"文件
}
}
else //如果链表都被删光了
{
fclose(fp);
return 0;
}
fclose(fp);
}
到此讲述了文件存储的两个方法,其实都算是同一种思路,就是如果链表中内容出现了变动,就打开文件将变动的链表内容覆写进去;
而加载文件时,根据链表的长度(或者文件是否eof)来判断为存储数据新建多少个链表节点。
但是这种存储方式还是有一些不足,不如说是C文件存储本身的设计缺陷,
如果要添加新的内容其实不需要覆写文件,直接将文件指针fseek到最后把新增的内容写入就行,
但如果要指定删除某一节点的内容的话,要么将修改后的内容覆写到文件,要么就将要删除内容前后的部分分别写到两个额外文件中重拼起来,然后将原文件删掉,将重拼的文件命名为原文件名,
但是两种方法都必须破坏原文件(一个内容上,一个直接删除)。
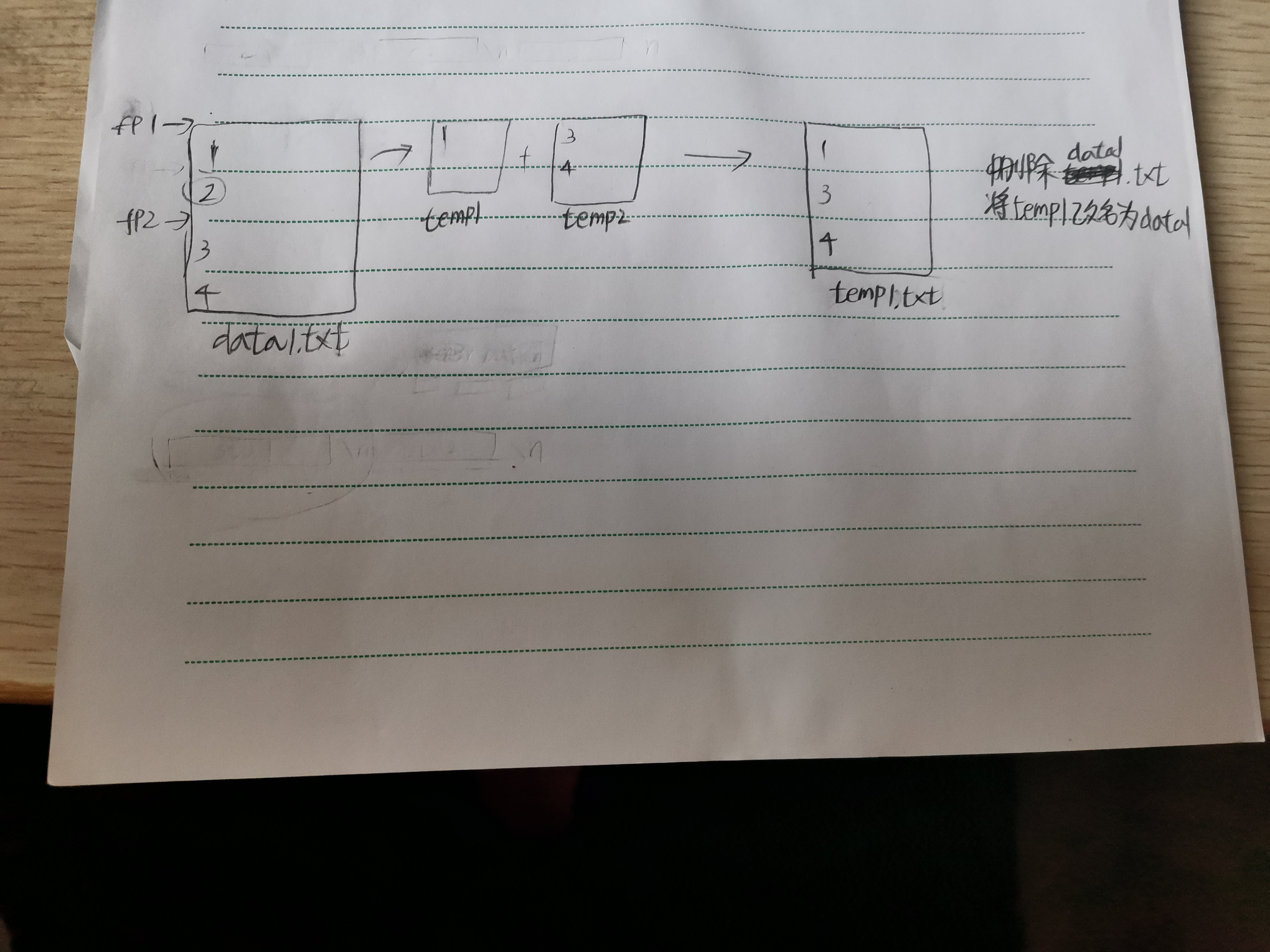
我设想直接把文件的指定内容删除就行,被删除内容后端的内容会自动上升与前端的内容结合,上面操作全都只在数据文件中执行,不需要额外的文件,但似乎没有如此的方法。

如果这不是一个1kb文件,而是几十GB乃至更大的大小,执行上述操作(覆写,复制)所浪费的程序性能可想而知,兴许随着的之后的学习我会为此采用数据库来改进存储。
我的留言板系统源码已发到gitee上,欢迎大家学习: