我们在学习大数据时避免不了地是要花大量的时间去搭建大数据环境,配置各种另人眼花缭乱的配置文件
各种大数据组件:hdfs、yarn、hive、zookeeper、flume、azkaban、saprk、Phoenix、hbase、sqoop、MongoDB、elasticsearch.....等等等等
整个搭下来可能十天半个月的时间不见了,真是得不偿失得不偿失。
最后花了大把时间,开发只学了一点点,大部分时间都在搞运维了。
从大数据开发到大数据运维,命运就是如此捉弄人的。
特别是现在的很多大数据课程,100个小时的课程可能60个小时都在教你怎么部署和搭建环境;
虽然吧,学一下怎么搭建大数据集群更有利于我们理解这些大数据组件的原理,
但是,对于很多只想搞个环境学习写个sql写个scala的职场老油条和那些平时不上课期末了得赶个大数据课程作业苦逼学生和那些毕业设计时间不多的苦逼毕业生来说,
搭建起来真的太麻烦了。
我曾经也经历过,所以更懂这种痛苦。
所以我将我自己学习用的HADOOP集群贡献出来给大家伙了。
毕竟:授人以渔不如授人以鱼嘛哈哈哈。
如下图,直接打包三台虚拟机,下载后解压,然后用VMWARE打开即可。
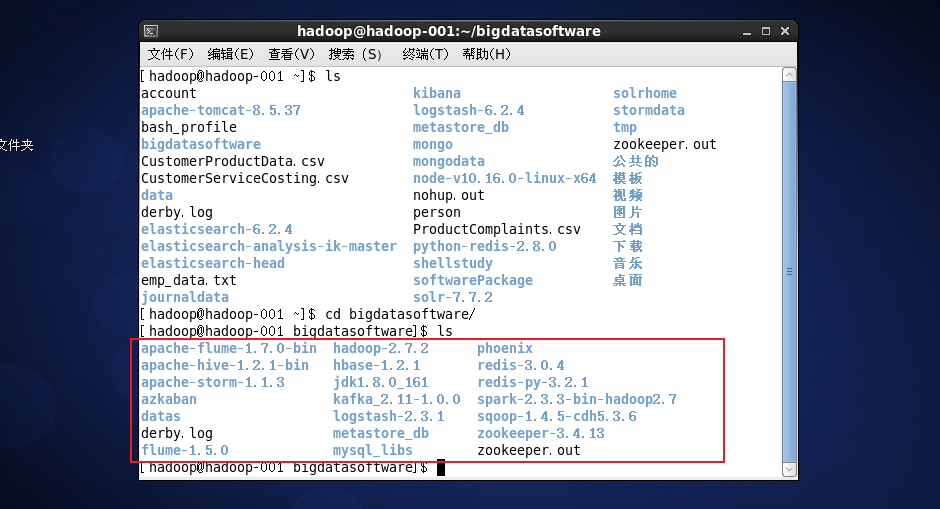
然后有这么多的组件可以用,,,很良心啊是不是。
需要的小伙伴,请关注微信公众号: Transkai, 或者扫描下方公众号二维码,回复关键字:Hadoop, 即可获取开箱即用的Hadoop集群

end