NodeJS -- 文件操作
Buffer(数据块)
JS语言自身只有字符串数据类型,没有二进制数据类型,因此NodeJS提供了一个与String对等的全局构造函数Buffer来提供对二进制数据的操作。除了可以读取文件得到Buffer的实例外,还能够直接构造,例如:
var bin = new Buffer([0x68, 0x65, 0x6c, 0x6c, 0x6f]);
Buffer与字符串类似,除了可以用.length属性得到字节长度外,还可以使用[index]方式读取指定位置的字节,例:
bin[0]; // => 0x68;
Buffer与字符串能够互相转化,例:
var str = bin.toString('utf-8'); // => 'hello' var bin = new Buffer('hello','utf-8'); // =><Buffer 68 65 6c 6c 6f>
Buffer与字符串一个重要区别:字符串是只读的,并且对字符串的任何修改得到的都是一个新字符串,原字符串保持不变。至于Buffer,更像是可以做指针操作的C语言数组。例可以使用[index]方式直接修改某个位置的字节:
bin[0] = 0x48;
而.slice方法也不是返回一个新的Buffer,而更像是反回了指向原Buffer中间某个位置的指针:
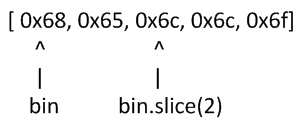
因此对.slice方法返回的Buffer的修改会作用于原Buffer。
Stream(数据流)
var rs = fs.createReadStream(pathName); rs.on('data', function(chunk) { doSomething(chunk); }); rs.on('end', function() { cleanUp(); });
注:Stream基于事件机制工作,所有Stream实例都继承于NodeJS提供的EventEmitter
上边的代码中data事件会源源不断地被触发,不管doSomething()函数是否处理得过来。代码可以继续作如下改造,以解决这个问题:
var rs = fs.createReadStream(src); rs.on('data', function(chunk) { rs.pause(); doSomething(chunk, function() { rs.resume(); }); }); rs.on('end', function() { cleanUp(); });
var rs = fs.createReadStream(src); var ws = fs.createWriteStream(dst); rs.on('data', function(chunk) { ws.write(chunk); }); rs.on('end', function(chunk) { ws.end(): });
以上代码看起来就像是一个文件拷贝程序了,不过,依然存在写入速度跟不上读取速度,会导致缓存爆仓的问题,我们可以根据.write方法的返回值来判断传入的数据是写入目标了,还是临时放在了缓存了,并根据drain事件来判断什么时候只写数据流已经将缓存中的数据写入目标,可以传入下一个待写数据了:
var rs = fs.createReadStream(src); var ws = fs.createWriteStream(dst); rs.on('data', function(chunk) { if(ws.write(chunk) === false) { rs.pause(); } }); rs.on('end', function() { ws.end(); }); rs.on('drain', function() { rs.resume(); });
实现了数据从只读数据流到只写数据流的搬运,并包括了放爆仓控制,NodeJS直接提供了.pipe方法来做这件事,内部实现方式与上述代码类似
File System(文件系统)
fs.readFile(pathName, function(err, data) { if(err) { // Deal with error. } else { // Deal with data } });
Path(路径)
操作文件时难免与文件路径打交道,NodeJS提供了path内置模块来简化路径相关操作,并提升代码可读性。
path.normalize
将传入的路径转换为标准路径,具体讲的话,除了解析路径中的.与..之外,还能去掉多余的斜杠,如果程序需要使用路径作为某些数据的索引,但有允许用户随意输入路径时,就需要使用该方法保证路径的唯一性,例:
var cache = {}; function store(key, value) { cache[path.normalize(key)] = value; } store('foo/bar', 1); store('foo//baz//../bar', 2); console.log(cache); // {'foo/bar': 2}
注意:标准化之后的路径里的斜杠在Window系统下是,而在linux系统下是/,若想保证任何系统都使用/作为路径分隔符的话,需要.replace(/\/g, '/')再替换下标准路径
path.join
将传入的多个路径拼接为标准路径,该方法可避免手工拼接字符串的繁琐,并且能在不同系统下正确使用相应路径分隔符。例:
path.join('foo/', 'baz/', '../bar'); // => "foo/bar"
path.extname
可获取文件的扩展名,当我们需要根据不同文件扩展名做不同操作时,该方法就显得很好用,例:
path.extname('foo/bar.js'); // => ".js"
遍历目录
文本编码
常用的文本编码有UTF8和GBK两种,并且UTF8还可能带有BOM,在读取不同编码的文本文件时,需要将文件内容转换为JS使用的UTF8编码字符串后才能正常处理
BOM的移除
BOM用于标记一个文件使用Unicode编码,其本身是一个Unicode字符(“uFEFF”),位于文本文件头部,在不同Unicode编码下,BOM字符对应的二进制字节如下:

因此我们可以根据文本文件头几个字节等于啥来判断文件是否包含BOM,以及使用哪种Unicode编码,但BOM并不属于文件的一部分,需要去掉,否则在某些应用场景下会有问题。以下代码实现了识别和去除UTF8 BOM的功能
function readText(pathName) { var bin = fs.readFileSync(pathName); if(bin[0] === 0xEF && bin[1] === 0xBB && bin[2] === 0xBF) { bin = bin.slice(3); } return bin.toString('utf-8'); }