工作原理:
- 由HTTP客户端发起一个请求,建立一个到服务器指定端口(默认是80端口)的TCP连接。 连接
- HTTP服务器则在那个端口监听客户端发送过来的请求。一旦收到请求, 请求
- 服务器(向客户端)发回一个状态行,比如"HTTP/1.1 200 OK",和(响应的)消息,消息的消息体可能是请求的文件、错误消息、或者其它一些信息。
- 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接
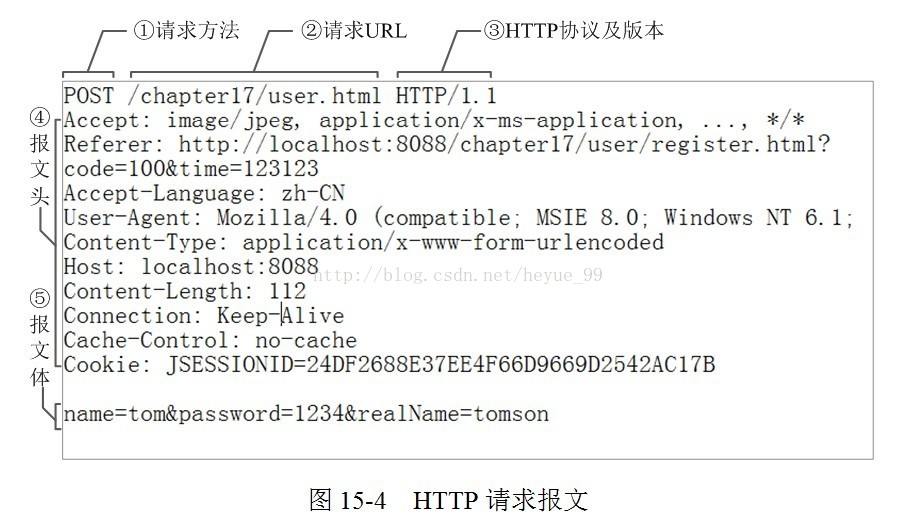
HTTP请求是指 : 客户端通过发送 HTTP 请求向服务器请求对资源的访问。 它向服务器传递了一个数据块,也就是请求信息,HTTP 请求由三部分组成:请求行、请求头和请求正文。
请求行:请求方法 URI 协议/版本
请求头(Request Header)
请求正文
下面是一个HTTP请求的数据:
If-Modified-Since:把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。如果时间一致,那么返回304,客户端就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中。
例如:If-Modified-Since: Thu, 09 Feb 2012 09:07:57 GMT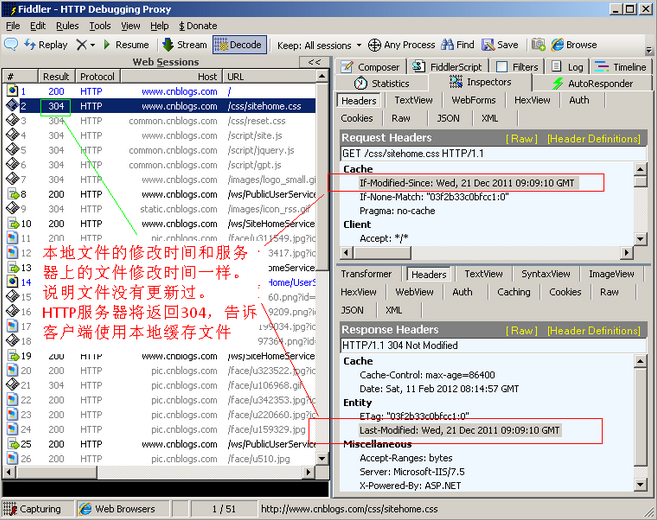
If-None-Match:If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 当用户再次请求该资源时,将在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服务器验证资源的ETag没有改变(该资源没有更新),将返回一个304状态告诉客户端使用本地缓存文件。否则将返回200状态和新的资源和Etag. 使用这样的机制将提高网站的性能。例如: If-None-Match: "03f2b33c0bfcc1:0"。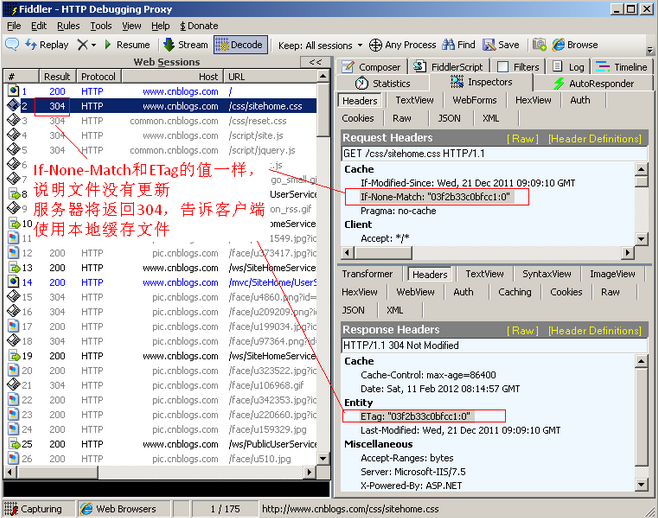
Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝;在HTTP/1.1版本中,它和Cache-Control:no-cache作用一模一样。Pargma只有一个用法, 例如: Pragma: no-cache
注意: 在HTTP/1.0版本中,只实现了Pragema:no-cache, 没有实现Cache-Control
Cache-Control:指定请求和响应遵循的缓存机制。缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是独立的(在请求消息或响应消息中设置Cache-Control并不会修改另一个消息处理过程中的缓存处理过程)。请求时的缓存指令包括no-cache、no-store、max-age、max-stale、min-fresh、only-if-cached,响应消息中的指令包括public、private、no-cache、no-store、no-transform、must-revalidate、proxy-revalidate、max-age、s-maxage。
Cache-Control:Public 可以被任何缓存所缓存
Cache-Control:Private 内容只缓存到私有缓存中
Cache-Control:no-cache 所有内容都不会被缓存
Cache-Control:no-store 用于防止重要的信息被无意的发布。在请求消息中发送将使得请求和响应消息都不使用缓存。
Cache-Control:max-age 指示客户机可以接收生存期不大于指定时间(以秒为单位)的响应。
Cache-Control:min-fresh 指示客户机可以接收响应时间小于当前时间加上指定时间的响应。
Cache-Control:max-stale 指示客户机可以接收超出超时期间的响应消息。如果指定max-stale消息的值,那么客户机可以接收超出超时期指定值之内的响应消息。
Accept:浏览器端可以接受的MIME类型。例如:Accept: text/html 代表浏览器可以接受服务器回发的类型为 text/html 也就是我们常说的html文档,如果服务器无法返回text/html类型的数据,服务器应该返回一个406错误(non acceptable)。通配符 * 代表任意类型,例如 Accept: */* 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)。
Accept-Encoding:浏览器申明自己可接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate);Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间。例如: Accept-Encoding: gzip, deflate。如果请求消息中没有设置这个域,服务器假定客户端对各种内容编码都可以接受。
Accept-Language:浏览器申明自己接收的语言。语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;例如:Accept-Language: en-us。如果请求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受。
Accept-Charset:浏览器可接受的字符集。如果在请求消息中没有设置这个域,缺省表示任何字符集都可以接受。
User-Agent:告诉HTTP服务器,客户端使用的操作系统和浏览器的名称和版本。
例如: User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)。
Content-Type:例如:Content-Type: application/x-www-form-urlencoded。
Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。提供了Request的上下文信息的服务器,告诉服务器我是从哪个链接过来的,比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。
例如: Referer:http://translate.google.cn/?hl=zh-cn&tab=wT
Connection:
例如:Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。HTTP 1.1默认进行持久连接。利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小。
Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭,当客户端再次发送Request,需要重新建立TCP连接。
Host:(发送请求时,该头域是必需的)主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的。HTTP/1.1请求必须包含主机头域,否则系统会以400状态码返回。
例如: 我们在浏览器中输入:http://www.guet.edu.cn/index.html,浏览器发送的请求消息中,就会包含Host请求头域:Host:http://www.guet.edu.cn,此处使用缺省端口号80,若指定了端口号,则变成:Host:指定端口号。
Cookie:最重要的请求头之一, 将cookie的值发送给HTTP服务器。
Content-Length:表示请求消息正文的长度。例如:Content-Length: 38。
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。主要用于证明客户端有权查看某个资源。当浏览器访问一个页面时,如果收到服务器的响应代码为401(未授权),可以发送一个包含Authorization请求报头域的请求,要求服务器对其进行验证。
UA-Pixels,UA-Color,UA-OS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
Range:可以请求实体的一个或者多个子范围。例如,
表示头500个字节:bytes=0-499
表示第二个500字节:bytes=500-999
表示最后500个字节:bytes=-500
表示500字节以后的范围:bytes=500-
第一个和最后一个字节:bytes=0-0,-1
同时指定几个范围:bytes=500-600,601-999
但是服务器可以忽略此请求头,如果无条件GET包含Range请求头,响应会以状态码206(PartialContent)返回而不是以200(OK)。
HTTP常见的响应头
Allow:服务器支持哪些请求方法(如GET、POST等)。
Date:表示消息发送的时间,时间的描述格式由rfc822定义。例如,Date:Mon,31Dec200104:25:57GMT。Date描述的时间表示世界标准时,换算成本地时间,需要知道用户所在的时区。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦
Expires:指明应该在什么时候认为文档已经过期,从而不再缓存它,重新从服务器获取,会更新缓存。过期之前使用本地缓存。HTTP1.1的客户端和缓存会将非法的日期格式(包括0)看作已经过期。eg:为了让浏览器不要缓存页面,我们也可以将Expires实体报头域,设置为0。
例如: Expires: Tue, 08 Feb 2022 11:35:14 GMT
P3P:用于跨域设置Cookie, 这样可以解决iframe跨域访问cookie的问题
例如: P3P: CP=CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR
Set-Cookie:非常重要的header, 用于把cookie发送到客户端浏览器,每一个写入cookie都会生成一个Set-Cookie。
例如: Set-Cookie: sc=4c31523a; path=/; domain=.acookie.taobao.com
ETag:和If-None-Match 配合使用。
Last-Modified:用于指示资源的最后修改日期和时间。Last-Modified也可用setDateHeader方法来设置。
Content-Type:WEB服务器告诉浏览器自己响应的对象的类型和字符集。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。可在web.xml文件中配置扩展名和MIME类型的对应关系。
例如:Content-Type: text/html;charset=utf-8
Content-Type:text/html;charset=GB2312
Content-Type: image/jpeg
媒体类型的格式为:大类/小类,比如text/html。
IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)定义了8个大类的媒体类型,分别是:
application— (比如: application/vnd.ms-excel.)
audio (比如: audio/mpeg.)
image (比如: image/png.)
message (比如,:message/http.)
model(比如:model/vrml.)
multipart (比如:multipart/form-data.)
text(比如:text/html.)
video(比如:video/quicktime.)
Content-Range:用于指定整个实体中的一部分的插入位置,他也指示了整个实体的长度。在服务器向客户返回一个部分响应,它必须描述响应覆盖的范围和整个实体长度。一般格式:Content-Range:bytes-unitSPfirst-byte-pos-last-byte-pos/entity-length。
例如,传送头500个字节次字段的形式:Content-Range:bytes0-499/1234如果一个http消息包含此节(例如,对范围请求的响 应或对一系列范围的重叠请求),Content-Range表示传送的范围。
Content-Length:指明实体正文的长度,以字节方式存储的十进制数字来表示。在数据下行的过程中,Content-Length的方式要预先在服务器中缓存所有数据,然后所有数据再一股脑儿地发给客户端。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入ByteArrayOutputStram,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。
例如: Content-Length: 19847
Content-Encoding:WEB服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应中的对象。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。
例如:Content-Encoding:gzip
Content-Language:WEB服务器告诉浏览器自己响应的对象所用的自然语言。例如: Content-Language:da。没有设置该域则认为实体内容将提供给所有的语言阅读。
Server:指明HTTP服务器用来处理请求的软件信息。例如:Server: Microsoft-IIS/7.5、Server:Apache-Coyote/1.1。此域能包含多个产品标识和注释,产品标识一般按照重要性排序。
X-AspNet-Version:如果网站是用ASP.NET开发的,这个header用来表示ASP.NET的版本。
例如: X-AspNet-Version: 4.0.30319
X-Powered-By:表示网站是用什么技术开发的。
例如: X-Powered-By: ASP.NET
Connection:
例如:Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭,当客户端再次发送Request,需要重新建立TCP连接。
Location:用于重定向一个新的位置,包含新的URL地址。表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。Location响应报头域常用在更换域名的时候。
Refresh:表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。注意Refresh的意义是“N秒之后刷新本页面或访问指定页面”,而不是“每隔N秒刷新本页面或访问指定页面”。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV="Refresh" ...>。注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。
WWW-Authenticate:该响应报头域必须被包含在401(未授权的)响应消息中,客户端收到401响应消息时候,并发送Authorization报头域请求服务器对其进行验证时,服务端响应报头就包含该报头域。
eg:WWW-Authenticate:Basic realm="Basic Auth Test!" //可以看出服务器对请求资源采用的是基本验证机制。
以下是几个常见的状态码:
200 OK
你最希望看到的,即处理成功!
303 See Other
我把你redirect到其它的页面,目标的URL通过响应报文头的Location告诉你。
304 Not Modified
告诉客户端,你请求的这个资源至你上次取得后,并没有更改,你直接用你本地的缓存吧,我很忙哦,你能不能少来烦我啊!
404 Not Found
你最不希望看到的,即找不到页面。如你在google上找到一个页面,点击这个链接返回404,表示这个页面已经被网站删除了,google那边的记录只是美好的回忆。
500 Internal Server Error
看到这个错误,你就应该查查服务端的日志了,肯定抛出了一堆异常,别睡了,起来改BUG去吧!
最后应配置不当,http协议出现的漏洞(不安全http请求方法)
漏洞检测
不安全的HTTP方法漏洞检测,分为两步:查询资源支持的方法、验证方法是否真的支持。
查询
通过命令也可以查看该web提供何种http请求方法
curl -v -X OPTIONS http://www.example.com/test/
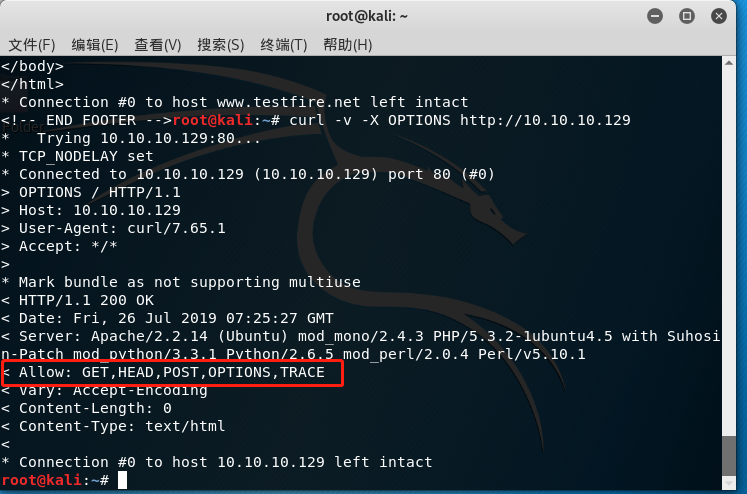
在之前的文章里提到过,OPTIONS请求方法可以查询URL指定的资源支持哪些方法。
首先正常请求,抓包,然后将请求包中的请求方法修改为OPTIONS,提交,如果成功,响应包中就会出现一个Allow首部字段,里面列出了URL指定资源所支持的方法列表。
执行到这一步,就出现这么一种现象,有的校友在执行OPTIONS请求后,发现响应包的Allow字段中包含了PUT、DELETE等不安全方法,就直接认定系统存在漏洞。在我看来,这是不严谨的。有时候Allow字段提示支持,但实际上并不支持,因此需要进一步验证该资源是否真的支持不安全的HTTP方法。
验证
查询阶段显示,支持TRACE方法。那我们将OPTIONS方法修改为TRACE方法试试,如果响应包主体中包含接收到的请求,则证明支持TRACE方法,系统存在漏洞。
发现服务器报错,证明并不支持TRACE方法。(不支持一般会报405)
不安全HTTP方法漏洞的检测大概就是这个流程,其余不安全方法在《HTTP | HTTP报文》中介绍过,检测的时候只是利用方法的特性而已,这里就不再赘述。
不过要注意的是,在验证PUT和DELETE的时候,不要在原有资源上进行操作,一定要指定一个不存在的资源,比如先PUT一个文件上去,然后DELETE刚才创建的文件,只要证明支持不安全的HTTP方法即可,切记不可修改和删除服务器原有文件。
另外,PUT还可以和WebDAV扩展中的COPY/MOVE配合,PUT上传文件,COPY/MOVE修改文件位置和类型。
下面就来详细说一下解决方案:
最简单的方式就是修改WEB应用的web.xml部署文件。在里面插入下面几行代码就搞定了,把需要屏蔽的方法加在里面。如果应用包比较多也没必要一个个改,直接修改Tomcat的web.xml就可以了,这样在Tomcat中运行的实例都会有效。
<security-constraint>
<web-resource-collection>
<web-resource-name>fortune</web-resource-name>
<url-pattern>/*</url-pattern>
<http-method>PUT</http-method>
<http-method>DELETE</http-method>
<http-method>HEAD</http-method>
<http-method>OPTIONS</http-method>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint></auth-constraint>
</security-constraint>
-
<security-constraint>用于限制对资源的访问; -
<auth-constraint>用于限制那些角色可以访问资源,这里设置为空就是禁止所有角色用户访问; -
<url-pattern>指定需要验证的资源 -
<http-method>指定那些方法需要验证
重启服务再验证就不会存在这个问题了。
文中内容引自:
https://blog.csdn.net/zcw4237256/article/details/80501109
https://www.cnblogs.com/EricaMIN1987_IT/p/3837436.html
https://www.cnblogs.com/xlyslr/p/5707995.html
https://www.jianshu.com/p/f1e58395cb44