1.深度学习的seq2seq模型
从rnn结构说起
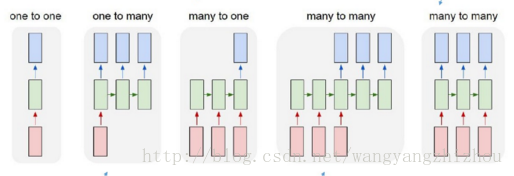
根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。如下图,
one to one 结构,仅仅只是简单的给一个输入得到一个输出,此处并未体现序列的特征,例如图像分类场景。
one to many 结构,给一个输入得到一系列输出,这种结构可用于生产图片描述的场景。
many to one 结构,给一系列输入得到一个输出,这种结构可用于文本情感分析,对一些列的文本输入进行分类,看是消极还是积极情感。
many to many 结构,给一些列输入得到一系列输出,这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。
同步 many to many 结构,它是经典的rnn结构,前一输入的状态会带到下一个状态中,而且每个输入都会对应一个输出,我们最熟悉的就是用于字符预测了,同样也可以用于视频分类,对视频的帧打标签。
seq2seq
在 many to many 的两种模型中,上图可以看到第四和第五种是有差异的,经典的rnn结构的输入和输出序列必须要是等长,它的应用场景也比较有限。而第四种它可以是输入和输出序列不等长,这种模型便是seq2seq模型,即Sequence to Sequence。它实现了从一个序列到另外一个序列的转换,比如google曾用seq2seq模型加attention模型来实现了翻译功能,类似的还可以实现聊天机器人对话模型。经典的rnn模型固定了输入序列和输出序列的大小,而seq2seq模型则突破了该限制。

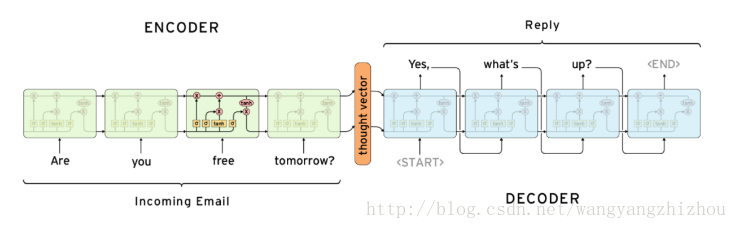
其实对于seq2seq的decoder,它在训练阶段和预测阶段对rnn的输出的处理可能是不一样的,比如在训练阶段可能对rnn的输出不处理,直接用target的序列作为下时刻的输入,如上图一。而预测阶段会将rnn的输出当成是下一时刻的输入,因为此时已经没有target序列可以作为输入了,如上图二。
encoder-decoder结构
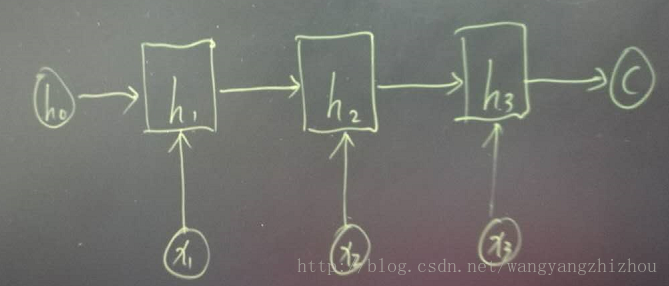
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的rnn中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
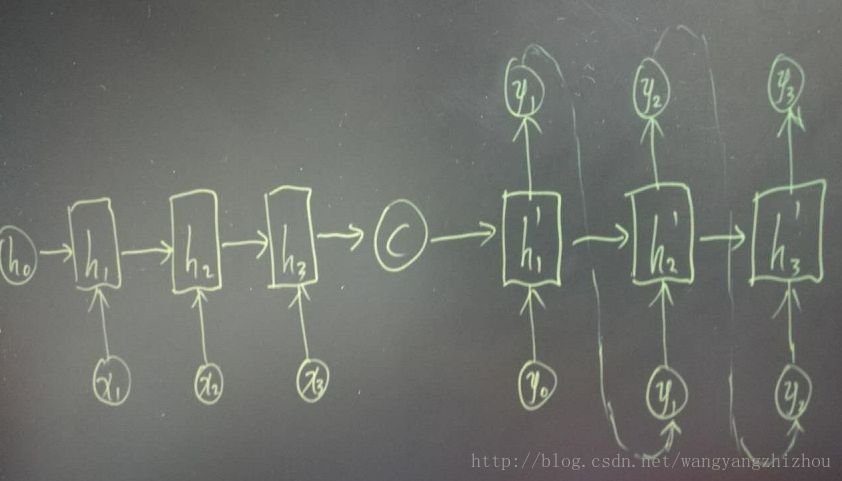
decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。
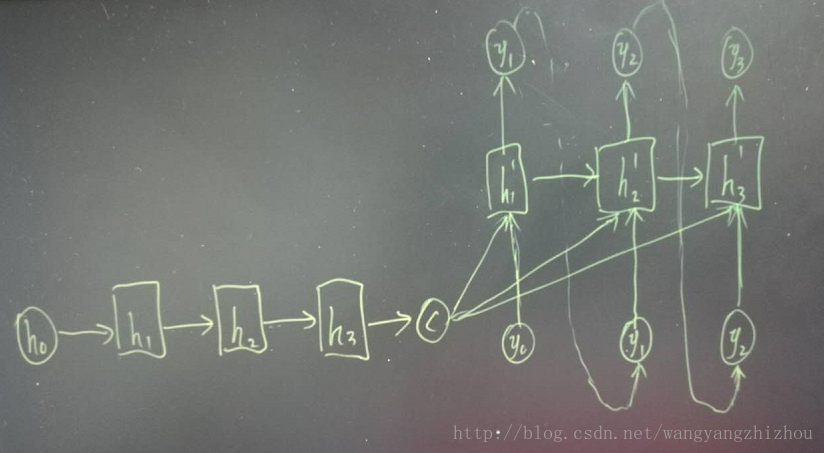
encoder-decoder模型对输入和输出序列的长度没有要求,应用场景也更加广泛。
原文:https://blog.csdn.net/wangyangzhizhou/article/details/77883152
2. 为什么需要Attention
最基本的seq2seq模型包含一个encoder和一个decoder,通常的做法是将一个输入的句子编码成一个固定大小的state,然后作为decoder的初始状态(当然也可以作为每一时刻的输入),但这样的一个状态对于decoder中的所有时刻都是一样的。
attention即为注意力,人脑在对于的不同部分的注意力是不同的。需要attention的原因是非常直观的,比如,我们期末考试的时候,我们需要老师划重点,划重点的目的就是为了尽量将我们的attention放在这部分的内容上,以期用最少的付出获取尽可能高的分数;再比如我们到一个新的班级,吸引我们attention的是不是颜值比较高的人?普通的模型可以看成所有部分的attention都是一样的,而这里的attention-based model对于不同的部分,重要的程度则不同。
2.1 Attention-based Model是什么
Attention-based Model其实就是一个相似性的度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比较合理的叫法,而非Attention Model。
2.3. Attention
对于机器翻译来说,比如我们翻译“机器学习”,在翻译“machine”的时候,我们希望模型更加关注的是“机器”而不是“学习”。那么,就从这个例子开始说吧(以下图片均来自上述课程链接的slides)
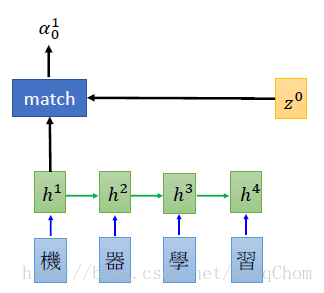
刚才说了,attention其实就是一个当前的输入与输出的匹配度。在上图中,即为h1h1和z0z0的匹配度(h1h1为当前时刻RNN的隐层输出向量,而不是原始输入的词向量,z0z0初始化向量,如rnn中的initial memory),其中的match为计算这两个向量的匹配度的模块,出来的α10α01即为由match算出来的相似度。好了,基本上这个就是attention-based model 的attention部分了。那么,match什么呢?
对于“match”, 理论上任何可以计算两个向量的相似度都可以,比如:
余弦相似度
一个简单的 神经网络,输入为hh和ww,输出为αα
或者矩阵变换α=hTWzα=hTWz (Multiplicative attention,Luong et al., 2015)
现在我们已经由match模块算出了当前输入输出的匹配度,然后我们需要计算当前的输出(实际为decoder端的隐状态)和每一个输入做一次match计算,分别可以得到当前的输出和所有输入的匹配度,由于计算出来并没有归一化,所以我们使用softmax,使其输出时所有权重之和为1。那么和每一个输入的权重都有了(由于下一个输出为“machine”,我们希望第一个权重和第二个权权重越大越好),那么我们可以计算出其加权向量和,作为下一次的输入。
如下图所示:

那么再算出了c0c0之后,我们就把这个向量作为rnn的输入(如果我们decoder用的是RNN的话),然后d第一个时间点的输出的编码z1z1由c0c0和初始状态z0z0共同决定。我们计算得到z1z1之后,替换之前的z0z0再和每一个输入的encoder的vector计算匹配度,然后softmax,计算向量加权,作为第二时刻的输入……如此循环直至结束。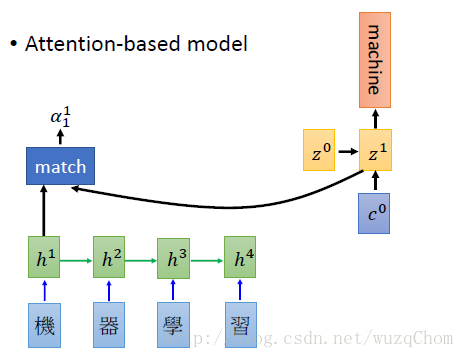
再看看Grammar as a Foreign Language一文当中的公式:
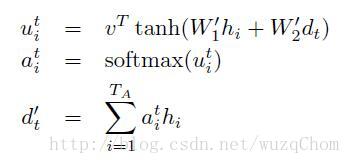
原文:https://blog.csdn.net/wuzqchom/article/details/75792501