赛题目标:通过用户历史订单数据,预测用户下一次购买的商品。
赛题数据:数据保存为四个文件中,训练数据(Antai_AE_round1_train_20190626.csv)、测试数据(Antai_AE_round1_test_20190626.csv)、商品信息(Antai_AE_round1_item_attr_20190626.csv)、提交示例(Antai_AE_round1_submit_20190715.csv)
-
训练数据:用户每次购买的商品id,订单日期以及用户国家标识
-
测试数据:较于训练数据,测试数据剔除了用户需要预测最后一次购买记录
-
商品信息:商品id、品类id、店铺id和商品价格
-
提交示例:预测用户购买商品Top30的item_id依概率从高到低排序,buyer_admin_id,predict 1,predict 2,…,predict 30
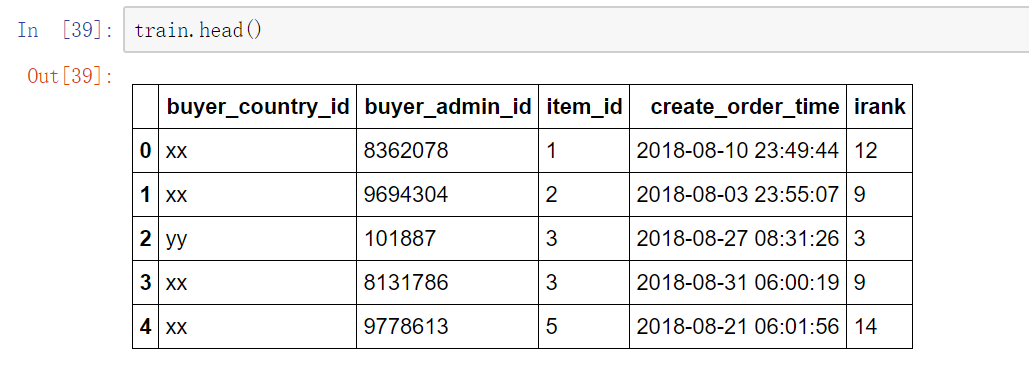
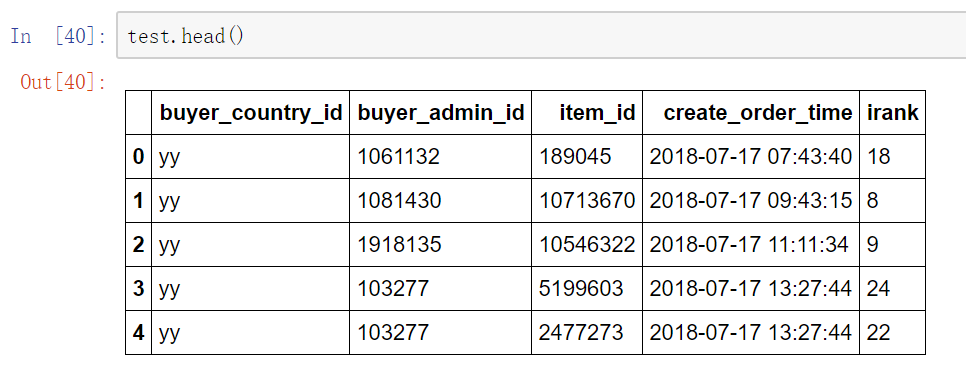
训练集样本量是 12868509
测试集样本量是 166832
样本比例为: 77.13453653975256
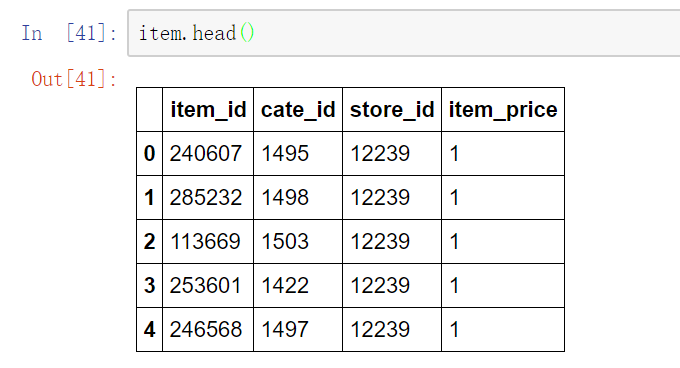
源数据中都木有空值,但是由于某些商品,不在商品表,因此缺少了一些价格、品类信息。
数据探查
1.buyer_country_id 国家编号

本次比赛给出若干日内来自成熟国家的部分用户的行为数据,以及来自待成熟国家的A部分用户的行为数据,以及待成熟国家的B部分用户的行为数据去除每个用户的最后一条购买数据,让参赛人预测B部分用户的最后一条行为数据。
- 训练集中有2个国家数据,xx国家样本数10635642,占比83%,yy国家样本数2232867条,仅占17%
- 预测集中有yy国家的166832数据, 训练集中yy国样本数量是测试集中的13倍,如赛题目的所言,期望通过大量成熟国家来预测少量带成熟国家的用户购买行为
2.buyer_admin_id 用户编号
训练集中用户数量 809213
测试集中用户数量 11398
同时在训练集测试集出现的有6位用户,id如下: [12647969, 13000419, 3106927, 12858772, 12929117, 12368445]
3.用户记录数分布
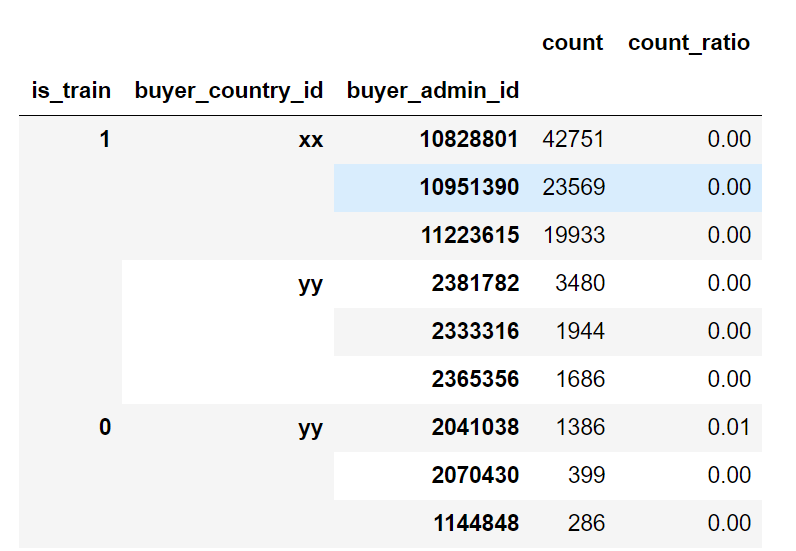
用户记录数进行了一波简单的探查:
- 训练集中记录了809213个用户的数据,其中id为10828801的用户拔得头筹,有42751条购买记录,用户至少都有8条记录
- 测试集中记录了11398个用户的数据,其中id为2041038的用户勇冠三军,有1386条购买记录,用户至少有7条记录
- 用户记录数大都都分布在0~50,少量用户记录甚至超过了10000条
Notes: 验证集中用户最少仅有7条,是因为最后一条记录被抹去
用户记录数进一步探查结论:
* 不管是训练集还是验证集,99%的用户购买记录都在50条内,这是比较符合正常逻辑
* TODO:对于发生大量购买行为的用户,后面再单独探查,是否有其他规律或疑似刷单现象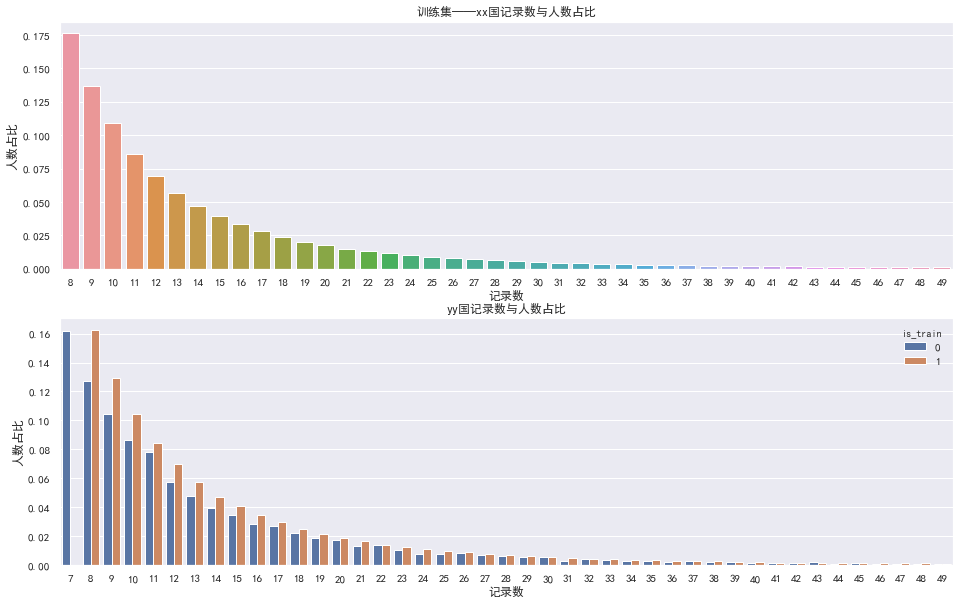
4.item_id 商品编号
商品表中商品数: 2832669
训练集中商品数: 2812048
测试集中商品数: 104735
仅训练集有的商品数: 2735801
仅测试集有的商品数: 28488
训练集测试集共同商品数: 76247
训练集中不在商品表的商品数: 7733
测试集中不在商品表的商品数: 313
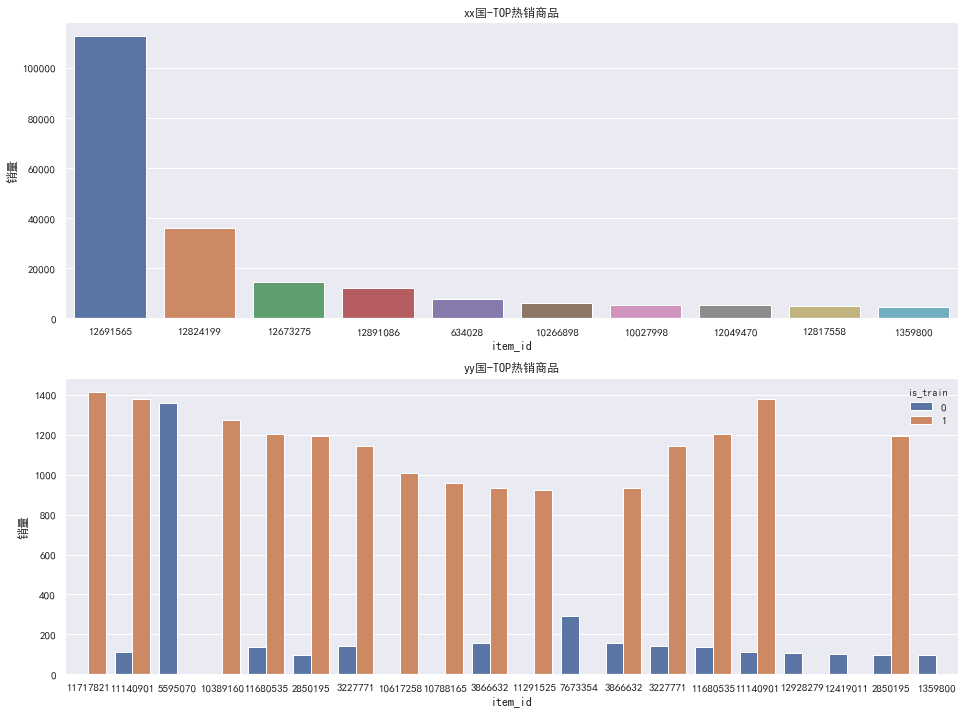
初步数据发现:
- 训练集中出售最多商品是12691565,卖了112659次。
- 测试集中出售最多商品是5595070 ,卖了112659次。
- 大部分商品只有1次出售记录,符合电商长尾属性
- 比较奇怪的yy国中,训练集和测试集中热销商品并不太一样
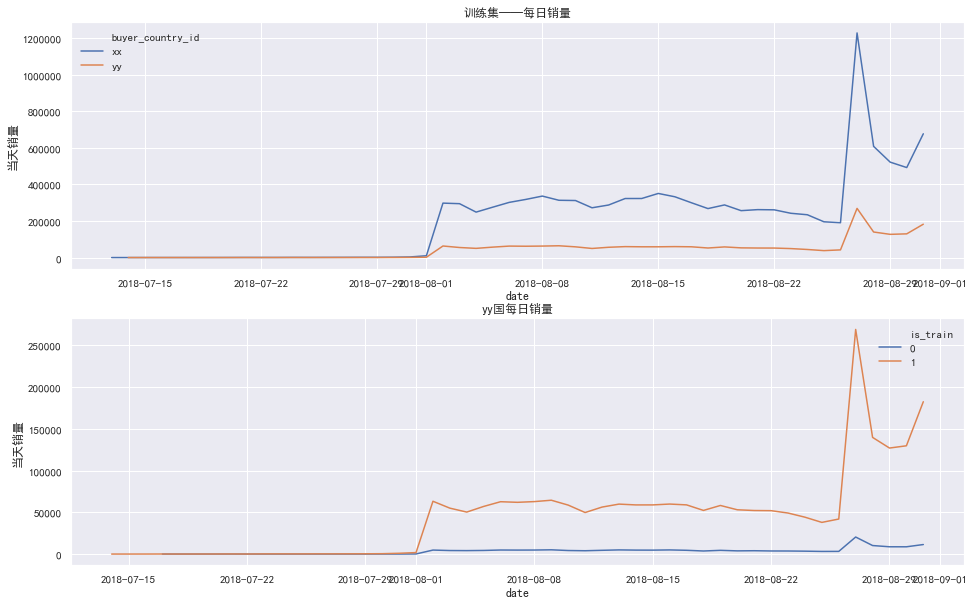
很明显:
- 训练集中7月份数据远小于8月份数据
- 训练集中xx国和yy国每日销量趋势十分相似,且在27日有个波峰