收集12小时的Profiler跟踪文件,用RML分析查看消耗前N的语句:
上图是某生产环境特定LoginName,消耗前N的情况(按总CPU降序)。蓝色底纹的是几个调用频繁的过程,可以看到过程平均CPU在1000毫秒以上,平均执行时间在1.5秒左右,注意它们的平均逻辑读很低!查看存储过程代码,发现有一个共同点,与 链接服务器.数据库.架构.表名 LEFT JOIN关联查询。
查看当前服务器使用链接服务器的例子,存储过程脚本如下:
语句很简单,在同一窗口执行过程语句的主体部分,一个有链接服务器(链接到本地),一个没有链接服务器,查看实际执行计划: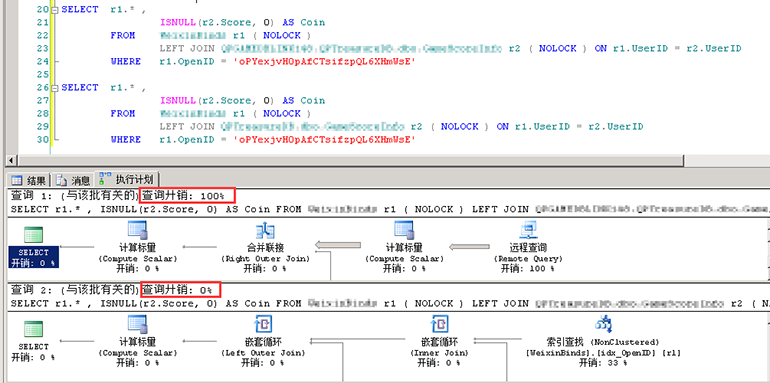
有链接服务器的查询开销为100%,本地直接查询0%,查看消耗大的操作对应的计划信息,远程查询时将整张表的数据返回;本地查询时通过关联字段使用seek谓词将对应Score返回: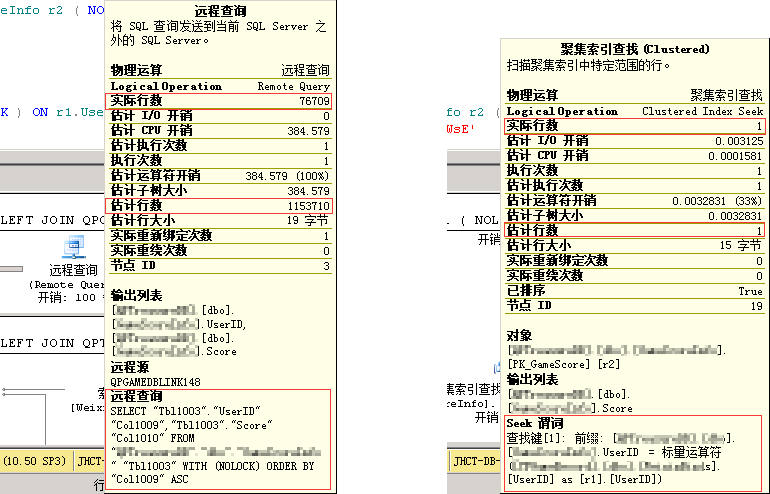
实际上这个过程平均执行时间1.5s,主要消耗在远程查询,远程查询最终体现在第一个图的红框语句,里面有Tbl1003、Col1013、Col1014别名,语句的平均逻辑读比较大,对于执行频繁的语句显然是有问题的。之前使用链接服务器是由于数据库存放在不同的服务器上,目前已迁移到同一台服务器,因此可以考虑将链接服务器去掉,如果以后还需要迁移出去,那就得考虑远程查询返回记录数,以及网络情况。尽量少用例子中所示的链接服务器关联查询,可以将远程的数据同步到本地,然后本地直接查询。
如果我们开启Profiler跟踪,可以看到链接服务器在事件RPC:Completed会将表取别名为Tbl**、列取别名为Col**,我们可以用一个带链接服务器的查询,带上where条件(方便过滤跟踪):
如果跟踪数据中发现很多类似上图中的语句,基本可以知道是由链接服务器产生的。