内联函数
- 定义方式:
在函数原型前使用关键字inline即可,内联函数的声明和实现均要放在
头文件中。 - 使用内联函数目的:
避免比较简短的函数调用时的开销,在C语言中要想避免这一问题只能
通过宏函数来达到这一目的,但带参宏函数有一个缺点,那就是不能对参
数类型作检查,而C++提供的inline关键字,在语法层面上提供了支持。 - 使用内联函数注意事项:
内联对于编译器来说只是一个建议,是否内联最终由编译器决定。
在VC++的Debug版本中,默认是不内联的,即使你使用了inline关键字
在头文件中加入或修改内联函数时,所有使用了该头文件的源文件都必
须重新编译。
函数重载需要满足的条件
- 作用域相同
- 函数名称相同
- 形参列表不同
注意:- "形参列表不同"只要满足如下三个条件之一即可:
参数个数不同,参数类型不同,参数顺序不同 - 如果有两个函数所在同一作用域,函数名称相同,形参列表相同,只有返回值不同,
这种情况不构成函数重载 - 如果有两个函数所在同一作用域,函数名称相同,形参列表相同,只有调用约定不同,
这种情况不构成函数重载
- "形参列表不同"只要满足如下三个条件之一即可:
是否构成函数重载的特殊案例:
- typedef T type 与 type 形参 不构成函数重载
- const type 与 type 形参 不构成函数重载
- type & 与 type 形参 构成函数重载
- type& 与 type*形参 构成函数重载
函数匹配
-
匹配步骤:
a)寻找候选函数:在可见作用域内寻找与被调用函数同名的函数
b)选择满足如下条件的可行函数:
i)从候选函数中选出形参个数与所传递实参个数相同的函数
j)被选出的函数的形参类型必须与对应的实参类型匹配,或者可以被隐式转换为对应的 形参类型。
c)寻找最佳匹配:
匹配成功的函数要满足如下两个条件:
i)其每个实参的匹配都不劣于其它可行函数所需的匹配
j)至少有一个实参的匹配优于其它可行函数提供的匹配 -
匹配失败的条件:
i)没有可行函数
j)可以匹配的函数有多个,但是无法确定哪个是最佳匹配 -
实参类型转换:
为了确定最佳匹配,编译器将实参类型到相应形参类型的转换划分了如下转换等级(降序排列):
1)精确匹配:实参与形参完全相同
2)通过类型提升实现的匹配
3)通过标准转换实现的匹配
4)通过类类型转换实现的匹配例:分析下面各函数(fun1-fun4)分别调用哪个命名空间中的哪个print,并尝试总结规律
namespace test1 { void print(int n) { cout << "print(int)" <<endl; } void print(const char* p) { cout << "print(const char*)" <<endl; } void print(double dbl) { cout << "print(double)" <<endl; } void print(long l) { cout << "print(long)" <<endl; } void print(char c) { cout << "print(char)" <<endl; } } namespace test2 { void print(double dbl) { cout << "print(double)" <<endl; } void print(float f) { cout << "print(float)" <<endl; } void print(int i) { cout << "print(int)" <<endl; } } namespace test3 { void print(double dbl) { cout << "print(double)" <<endl; } void print(float f) { cout << "print(float)" <<endl; } } namespace test4 { void print(float f) { cout << "print(float)" <<endl; } void print(const char* p) { cout << "print(const char*)" <<endl; } } void fun1(char c,int i,short s, float f) { using namespace test1; print(c); print(i); print(s); print(f); print('a'); print(49); print(0); print("a"); } void fun2(char c,int i,short s) { using namespace test2; print(c); print(i); print(s); print('a'); print(49); print(0); } void fun3(char c,int i,short s, float f) { using namespace test3; print(c); print(i); print(s); print(f); print('a'); print(49); print(0); } void fun4(char c,int i,short s, float f) { using namespace test4; print(c); print(i); print(s); print(f); print('a'); print(49); print(0); }
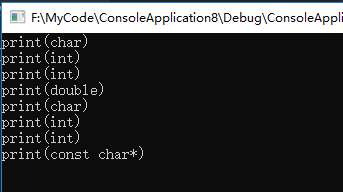
fun1分析如下:
fun1函数内部有using namespace test1,所以fun1调用了test1名称空间中的print,
print(c)实参是char类型,与void print(char c)匹配;
print(i)实参是int类型,与void print(int n)匹配;
print(s)实参是short类型,与void print(int n)匹配;
print(f)实参是float类型,test1没有完全匹配的函数,但是经过提升转换后与void print(double dbl)匹配
print('a')实参是字符常量,与void print(char c)匹配
print(49)实参为整型常量,与void print(int n)匹配;
print(0)实参为整型常量,与void print(int n)匹配;
print("a")实参类型为常量字符串,与void print(const char* p)匹配运行结果:
fun2分析如下:
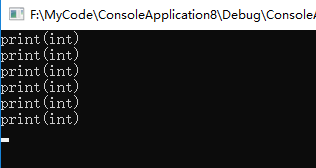
fun2函数内部有using namespace test2,所以fun2调用了test2名称空间中的print,
print(c)实参为char类型,没有完全匹配的函数,提升转换后与void print(int i)匹配
print(i)实参为int类型,与void print(int i)匹配
print(s)实参为short类型,没有完全匹配的函数,提升转换后与void print(int i)匹配
print('a')实参为字符常量,没有完全匹配的函数,提升转换后与void print(int i)匹配
print(49)实参为整型常量,与void print(int i)匹配
print(0)实参为整型常量,与void print(int i)匹配
运行结果:
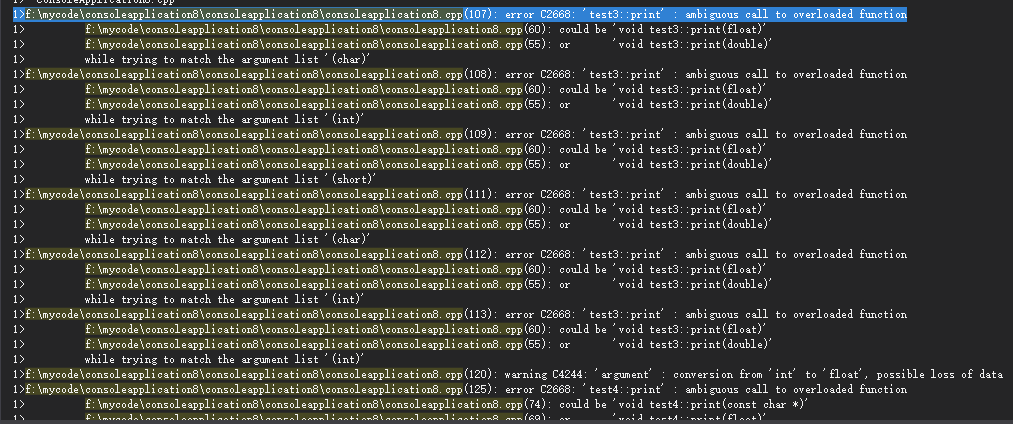
fun3分析如下:
fun3函数内部有using namespace test3,所以fun3调用了test3名称空间中的printprint(c)实参为char类型,没有全匹配的函数,提升转换后与既和void print(double dbl)匹配,也和
void print(float f)匹配,产生二义性,编译时会报错print(i)实参为int类型,没有全匹配的函数提升转换后与既和void print(double dbl)匹配,也和
void print(float f)匹配,产生二义性,编译时会报错print(s)实参为short类型,没有全匹配的函数,提升转换后与既和void print(double dbl)匹配,也和
void print(float f)匹配,产生二义性,编译时会报错print(f)实参为float类型,与void print(float f)匹配
print('a')实参为字符常量,没有完全匹配的函数,提升转换后与既和void print(double dbl)匹配,也和
void print(float f)匹配,产生二义性,编译时会报错print(49)实参为整型常量,没有完全匹配的函数,提升转换后与既和void print(double dbl)匹配,也和
void print(float f)匹配,产生二义性,编译时会报错print(0)实参为整型常量,没有完全匹配的函数,提升转换后与既和void print(double dbl)匹配,也和
void print(float f)匹配,产生二义性,编译时会报错编译结果:
fun4分析如下:
fun4函数内部有using namespace test4,所以fun4调用了test4名称空间中的print
print(c)实参为char类型,没有完全匹配的函数,提升转换后与void print(float f)匹配
print(i)实参为int类型,没有完全匹配的函数,提升转换后与void print(float f)匹配
print(s)实参为short类型,没有全匹配的函数,提升转换后与void print(float f)匹配
print(f)实参为float类型,和void print(float f)匹配
print('a')实参为字符常量,没有全匹配的函数,提升转换后与void print(float f)匹配
print(49)实参为整型常量,没有全匹配的函数,提升转换后与void print(float f)匹配
print(0);实参为整型常量,没有全匹配的函数,提升转换后既与void print(float f)匹配,
也和void print(const char* p)匹配,产生二义性,编译时报错
名称粉碎
为什么C++编译器需要名称粉碎?这得从一个可执行文件的生成过程来谈起:
首先由预处理器先对源码文件进行头文件的复制和宏展开,然后在由编译器进行编译,产生中间文件,也就是
后缀为.obj的文件,然后在由链接器从这些obj文件中抽取被调用函数的二进制代码,然后生成操作系统可以
运行的可执行文件,在C语言中如果两个函数同名,那么在链接的时候就会报链接错误,以VC++的链接器为例:
fatal error LNK1169: one or more multiply defined symbols found
意思就是链接的时候找到了两个同名函数,它不知道该链接哪个函数,所以只能报错,但是C++要支持函数重载,
这就使得同一个作用于内会出现同名函数,在生成obj文件时必定不能在使用C语言的名称粉碎规则,以VC++编
译器为例,它将函数的参数类型参与名称粉碎,依次来区分重载的函数,例如:
void Function1 (int a, int * b);函数被编译器名称粉碎后的名称为:mangled as ?Function1@@YAXHPAH@Z
其中 Y: 全局函数
A: cdecl调用协议
X: 返回类型为void
H: 第一个形参类型为int
PAH:第二个形参类型为整形指针
@: 形参表结束标志
Z: 缺省的异常规范 */
其中 Q: 类的public function
通过这种方式即可为区分不同的重载函数
extern "C"链接指示
我以一个简单的函数为例:
int Test(char a) { return a; }
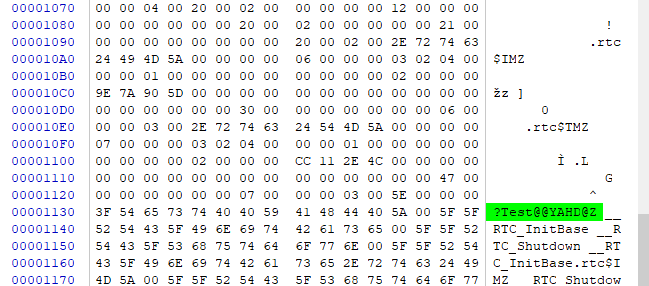
将其源码文件后缀名称改成.c,使得VC++编译器按照C标准编译该源文件,然后打开对应的obj文件:
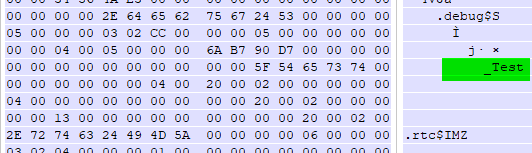
将其源码文件后缀名称改成.cpp,使得VC++编译器按照C++标准编译该源文件,然后打开对应的obj文件:
-
C++调用C
可以看出C和C++名称粉碎规则并不相同,现在将这个使用C标准编译的obj给一个C++工程使用,将obj文件复制到C++工程文件夹下,并直接添加到工程中:
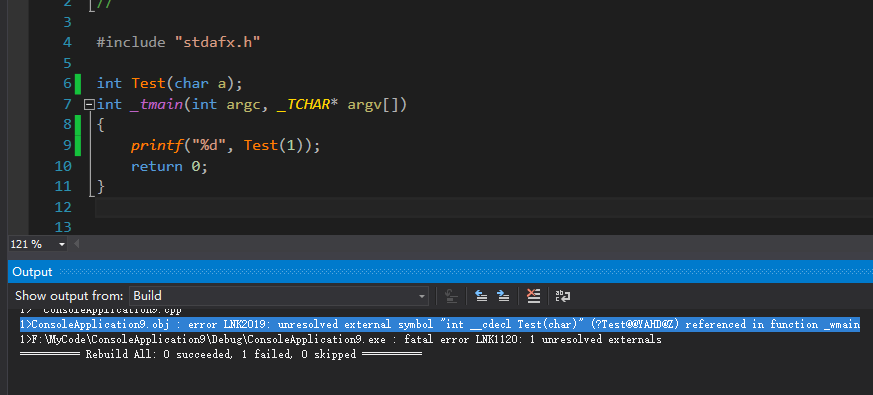
然后进行编译链接:
打开调用Test函数的C++源码编译后的obj:
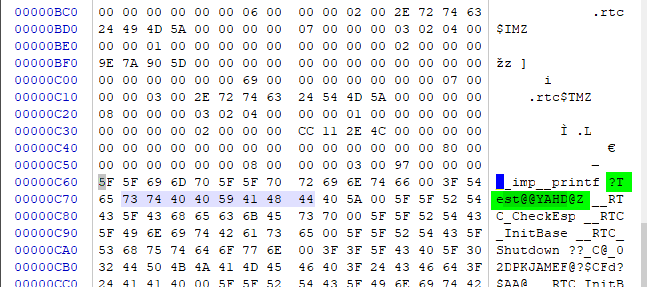
可以看出C++编译器在编译时使用的是C++的名称粉碎规则,被调用的Test函数经过C++的名称粉碎后为?Test@@YAHD@Z
但是Test函数的二进制代码存放在SourceCode.obj中,并且其按照C的名称粉碎后的名称为_Test,所以链接器无法
根据?Test@@YAHD@Z来找到Test函数的二进制代码,所以链接时报错在这种情况下,只要在所调用的函数声明前加extern "C",那么VC++编译器在生成obj文件时,就会按照C的名称粉碎
规则对Test函数进行名称粉碎,使得链接器链接时能找到该函数的二进制代码:
编译链接无错误,再来观察下调用Test函数的源文件被编译后生成的obj文件:
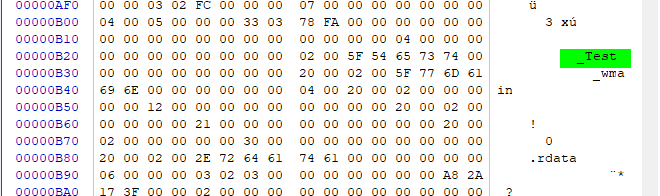
的确是使用C的名称粉碎规则 -
C调C++
那么C调用C++编译器生成的代码,是不是在C代码中使用extern "C++"就行了呢?这是不行的,C编译器
不支持extern "C++"这种语法,也不支持extern "C"这种语法,所以编译C++代码时在对应的函数定义
前加上extern "C",让C++编译器按照C的名称粉碎规则进行名称粉碎,但这也是有很大限制的,例如:
多个重载函数只能在一个函数前加extern "C":
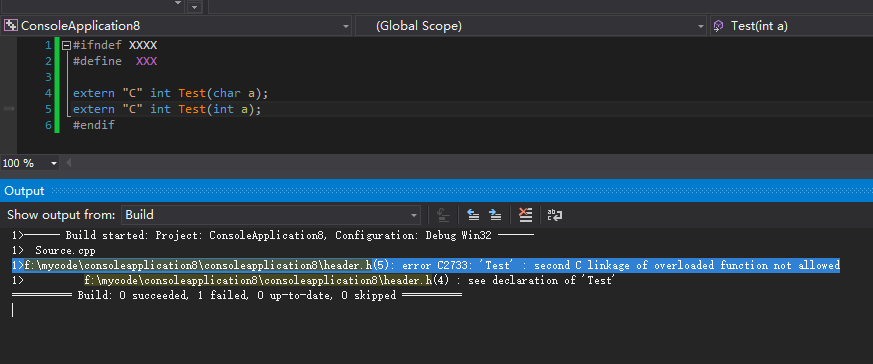
有些时候我们写了一些C函数,想让这些函数被C语言编译器编译后,同时能被C和C++调用,当我们提供给C++代码调用时,需要在头文件里加extern "C",否则C++编译的时候会找不到符号,而给C代码调用时又不能加extern "C",
这是可以使用条件宏:#ifdef __cplusplus extern "C" { #endif //所有的函数原型声明放在这里 #ifdef __cplusplus } #endif
调用时需要包含上述头文件,并将上述代码编译后的产物(obj,lib,dll)添加到工程中,当在C中调用时条件宏使得
extern "C"不生效,而__cplusplus是C++标准定义的宏,只要是C++编译器就必定有这个宏,当C++源码中调用上述代码编译后的产物时,extern "C"生效