分布式存储-Redis高性能的原理
前面聊了网络通信,当我们连接Redis的时候,就是一次通信的过程,所以我们讲Redis的高性能的根本之一就是,网络通信。前面有朋友问到我Redis可以同时处理那么多并发的原因是不是和通信中的多路复用有关,我答应他在后续的章节中讲讲,所以本章聊聊
- 他的底层和多路复用机制(Reactor模型)
- 内存回收策略
Redis6.0之前的单线程reactor模型
Reactor其实不是一种新的技术,而是基于NIO多路复用机制,提出来的一种高性能的设计模式,底层还是咱们之前聊得NIO多路复用。他的想法是把相应事件和咱们的业务进行分离,这样就可以通过一个或者多个线程处理IO事件。这里有三个部分:
- Reactor:进行IO事件的分发
- Handler : 处理非阻塞的读和写(这其实就是真正处理IO的处理器)
- Acceptor:处理客户端的连接
整体流程:
Reactor
 View Codepublic class Reactor implements Runnable { private final Selector selector; private final ServerSocketChannel serverSocketChannel; public Reactor(int port) throws IOException { selector=Selector.open(); serverSocketChannel=ServerSocketChannel.open(); serverSocketChannel.socket().bind(new InetSocketAddress(port)); serverSocketChannel.configureBlocking(false); //注册一个连接事件 serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT,new Acceptor(selector,serverSocketChannel)); } @Override public void run() { while (!Thread.interrupted()) { try { selector.select(); Set<SelectionKey> selectionKeys = selector.selectedKeys(); Iterator<SelectionKey> iterator = selectionKeys.iterator(); while (iterator.hasNext()) { dispatch(iterator.next()); iterator.remove(); } } catch (IOException e) { e.printStackTrace(); } } } private void dispatch(SelectionKey next){ //这里到时候就可能拿到handler 或者 acceptor Runnable attachment = (Runnable) next.attachment(); if (attachment!=null){ attachment.run(); } } }
View Codepublic class Reactor implements Runnable { private final Selector selector; private final ServerSocketChannel serverSocketChannel; public Reactor(int port) throws IOException { selector=Selector.open(); serverSocketChannel=ServerSocketChannel.open(); serverSocketChannel.socket().bind(new InetSocketAddress(port)); serverSocketChannel.configureBlocking(false); //注册一个连接事件 serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT,new Acceptor(selector,serverSocketChannel)); } @Override public void run() { while (!Thread.interrupted()) { try { selector.select(); Set<SelectionKey> selectionKeys = selector.selectedKeys(); Iterator<SelectionKey> iterator = selectionKeys.iterator(); while (iterator.hasNext()) { dispatch(iterator.next()); iterator.remove(); } } catch (IOException e) { e.printStackTrace(); } } } private void dispatch(SelectionKey next){ //这里到时候就可能拿到handler 或者 acceptor Runnable attachment = (Runnable) next.attachment(); if (attachment!=null){ attachment.run(); } } }Acceptor
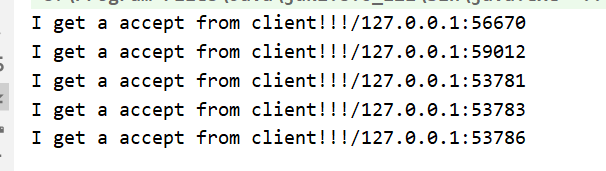
View Codepublic class Acceptor implements Runnable { private final Selector selector; private final ServerSocketChannel serverSocketChannel; public Acceptor(Selector selector, ServerSocketChannel serverSocketChannel) { this.selector = selector; this.serverSocketChannel = serverSocketChannel; } @Override public void run() { SocketChannel socketChannel; try { socketChannel=serverSocketChannel.accept(); System.out.println("I get a accept from client!!!"+socketChannel.getRemoteAddress()); socketChannel.configureBlocking(false); socketChannel.register(selector, SelectionKey.OP_READ,new Handler(socketChannel)); } catch (IOException e) { e.printStackTrace(); } } }Handler
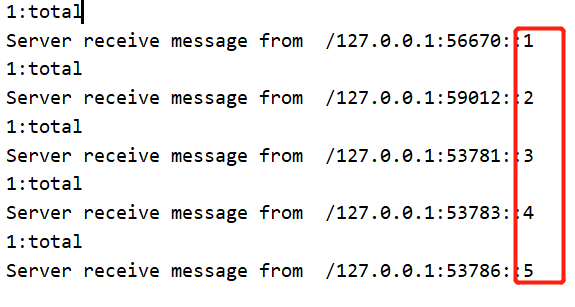
View Codepublic class Handler implements Runnable { SocketChannel socketChannel; public Handler(SocketChannel socketChannel) { this.socketChannel = socketChannel; } @Override public void run() { ByteBuffer byteBuffer = ByteBuffer.allocate(1024); int len = 0, total = 0; StringBuilder message = new StringBuilder(); try { do { len = socketChannel.read(byteBuffer); //这里表示还有消息没有读完 if (len > 0) { total += len; message.append(new String(byteBuffer.array())); } } while (len > byteBuffer.capacity()); System.out.println(total + ":total"); System.out.println("Server receive message from " + socketChannel.getRemoteAddress() + "::" + message); } catch (IOException e) { e.printStackTrace(); } finally { if (socketChannel != null) { try { socketChannel.close(); } catch (IOException e) { e.printStackTrace(); } } } } }Test
View Codepublic class ReactorMain { public static void main(String[] args) throws IOException { new Thread(new Reactor(8080)).start(); } }这个时候我们去链接我们的Reactor
Reactor收到请求,注册accept事件,多路复用器发现,于是调用acceptor
使用客户端给reactor发送消息:客户端发送到reactor上,多路复用发现了事件,然后就去调用handler的run方法,handler就可以读取到发送内容了



Redis6.0之后
redis6.0之后是的流程为:读socket、解析socket、以及写入socket是通过多线程完成的而执行操作是通过单线程完成的,简而言之,它的主线程只需要处理指令,而其他的操作交给其他的线程进行完成,这样性能就大大的提高了,并且他还是线程安全的,因为它还是只是由主线程进行操作IO.而6.0之前都是通过单线程完成的
Redis内存回收策略
为什么聊它的内存回收策略的?这是因为它的内存空间是有限的,如果我们不给缓存设置过期时间,有可能就会有很多无效的缓存,那这些无效的数据就会占用我们的内存,从而导致IO的性能(因为检索或0者操纵数据的时间复杂度就会增加)。
聊到内存淘汰策略,大家一定听过LRU、LFU这样的算法。那么当内存达到他的上限的时候(默认是没有上限,我们可以设置他的内存上限),我们就可以设置LRU算法去释放部分无效的key.redis提供了8种的内存淘汰策略。
- volatile-lru:针对设置了过期时间的key,使用iru算法进行淘汰(移除最少使用的keys)
- allkeys-lru: 针对所有的key使用iru进行淘汰(移除最少使用的)
- volatile-lfu: 针对最不经常(最少)使用的key,使用lfu算法进行淘汰
- allkeys-lfu:针对所有的key使用lfu算法移除最不经常使用的key
- volatile-random:针对设置了过期时间的key中,随机移除某个key 。
- allkeys-random:针对所有的keys,随机移除keys
- volatile-ttl:针对设置了过期时间的keys中,移除存活时间最少的key
- no-eviction:不删除key,直接抛出异常
其实对于上面这些回收策略,我们主要要分析的就是LRU和LFU,因为random以及ttl没有什么逻辑可言。
LRU(least recently used):从它的英文全名就能看出他的意思是【最近很少使用的】。那他是如何实现的呢?
他的底层用了两个数据结构【hashmap和双向链表】。它的链表中存储的是很久没有使用的keys,而hashmap的作用的定位到某个链表中的节点。因为链表的时间复杂度是o(n)(要从头/尾遍历),如果我们有了hashmap那通过key来寻找value就是一个O(1)的操作。
流程为:
- 把没有使用的key放在双向链表中,并且在hashmap中针对这个key做一个索引
- 当链表满了的情况下,它会把尾部的数据丢掉(取决于是头插法还是尾插法)
- 如果一个key被命中了,那他就会移动位置,如果使用的是头插法则把他的位置移到头部反之亦然-》这是因为要把他放在一个不容易被lru算法淘汰的位置
缺点:
前面的流程说,当一个key被命中他在链表中的位置就会移动到不容易被LRU算法淘汰的位置,那么很可能一个不是热点数据被命中,他只是使用了一次,然而它也被放在了不容易淘汰的位置。
redis中使用LRU:
他维护了一个大小为16的一个候选池,按照空闲时间进行排序,具体逻辑如下:
- 当回收池满了的情况下,如果我们要添加一个key,这个key的空闲时间如果是最小的,则不进行任何操作
- 如果回收池没有满的情况下,redis会比较当前传递的key在所有key中的位置(通过空闲时间去进行对比)他会把插入的位置的元素后移一位再进行插入
- 回收池没有满的情况下,当前传递的key是小的,则直接插入到最后
- 回收池满的情况下, 当前的key要比部分的元素的空闲时间更大,那他就需要插入到中间位置,那就需要把头部的数据移除
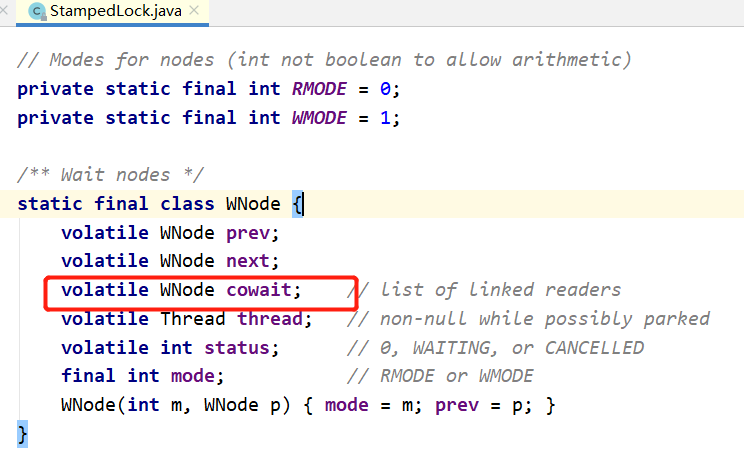
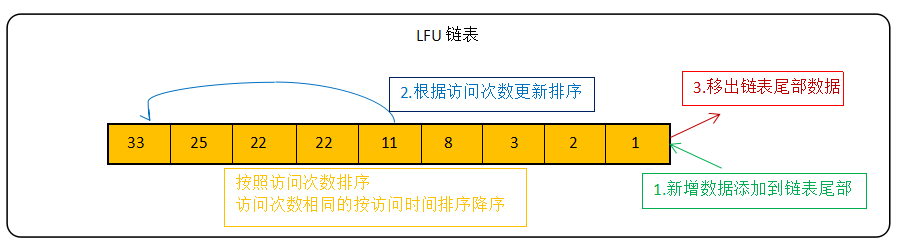
LFU(least frequently used)【最少频率使用】:他和LRU的不同点就是在使用次数上,他会根据key最近被访问的频率进行淘汰,比较少的就有效淘汰。他的不同点就是他维护了一个横向和纵向的双向链表,类似于StampedLock一样。他是按照计数器对key进行排序。他横向node表示的访问的频次,纵向表示的是具有相同频次的数据,每次获取或者修改元素的时候都会根据key的访问频率去修改key的位置,这样就解决了可能对比非热点数据而占据不可删除的节点的位置的尴尬情况