关系型数据库优化&分库分表(Outline)
前面我们聊了NoSql中的Redis,但是实际上,大部分公司存储依然使用的是关系型数据库,因为在很多场景下,关系型数据库依然是一个很好的存储解决方案,而Nosql这些组件实际上做的更多的是一些辅助工作,这一篇想在全局的层间聊聊,会提到一些分库分表的一些东西,后面会介绍一些中间件帮助我们让这些事情更加 方便。
关系型数据库层面的高并发优化
以MySql为例,MySql出现的性能问题都有:
- 表的数据量过大
- sql查询太复杂
- sql查询没有走索引
- 数据库服务区的性能太低
- ......
表数据过大的解决方案: 阿里开发手册中提到:单表行数超过500W或者单表数据容量超过2G就对性能产生影响,其实还是和有多少列有关系,所以还是要根据真实的情况对数据表进行拆分
- 分库分表:减少单个表的数据量
- 历史数据归档:放在磁盘上,等用的使用进行解析。
- 冷热数据分离:实时库中只展示最新的热点数据,其他不经常用的使用放在一个备份库中或者历史库中。如果真的要查询冷数据
- 我们可以发送一个请求,然后发送一个指令进行异步导出,然后发送到相关人的邮箱中。
- 设置查询区间,这个时候通过查询区间进行路由,就可以查询到新老库的数据。
数据库的分库分表:是一个很常见的数据存储问题而导致性能问题的解决方案,不管是对关系型或者非关系形。例如
- kafka->数据分片(partition)
- redis -redis-cluster -> slot
- mysql-分片
- 。。。
【常见的形式】:
- 水平拆分:数据表的字段格式不变,把数据分成多个分
- 水平分表:如果说有用户1-10000 那我们就分成不同的表,给起不同的后缀名 【用户 1-2500】 【用户 2501-5000】【。。。】
- 水平分库:把数据切割出来放在不同的数据库中
- 垂直拆分:
- 垂直分表:原先表冗余在一起,现在拆分成不同的表。比如把订单和订单明细分开。
- 垂直分库:实际上就是按照业务领域的垂直拆分。比如订单库、商品库、用户库
【分库分表策略】:
- 【哈希取模分片】:其实就是通过表中的某一个字段进行hash算法得到一个哈希值,然后通过取模运算确定数据应该放在哪个分片中。
- 【问题】:假设根据当前数据表的量以及增长情况,我们把一个大表拆分成了4个小表,看起来满足目前的需求,但是经过一段时间的运行后,发现四个表不够,需要再增加4个表来存储,这种情况下,就需要对原来的数据进行整体迁移,这个过程非常麻烦
- 【解决方案】:
- 首先备份原先的数据,然后使用一个程序去跑批,把数据同步到新表中,在同步的过程中肯定有新的数据产生,这个时候要对这些新的数据进行处理。
- 修改的时候,同时两个表都要修改。比如说修改历史表,那我们的新表也要同步修改
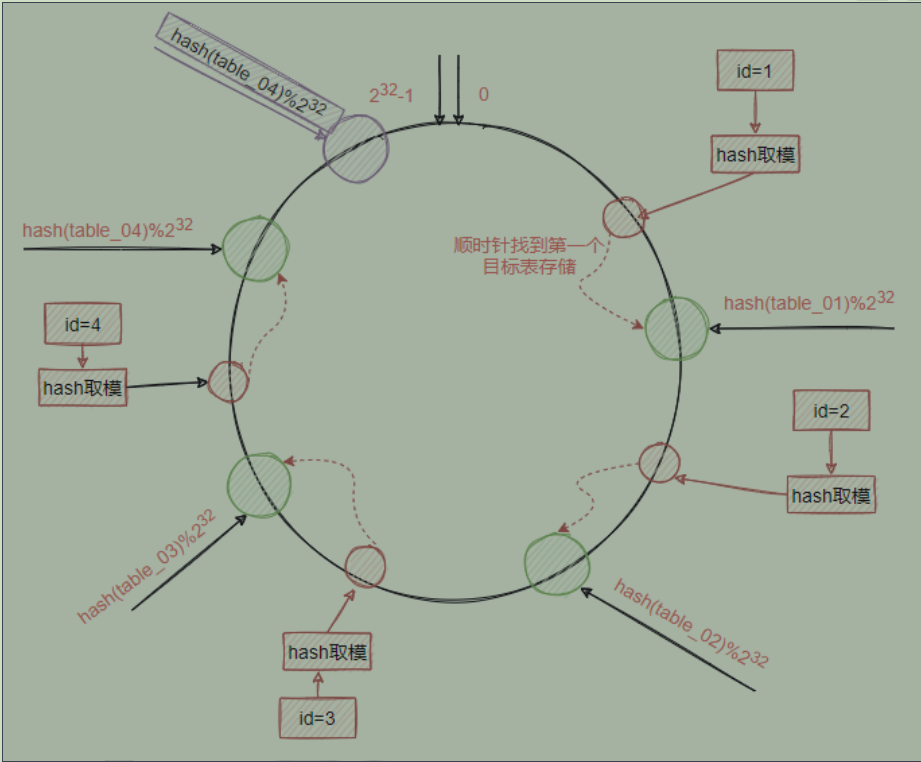
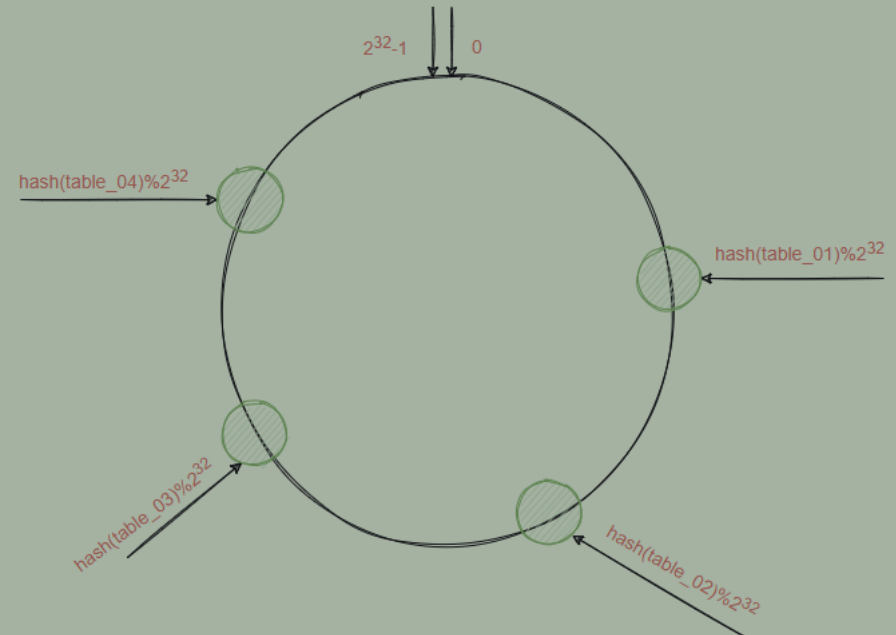
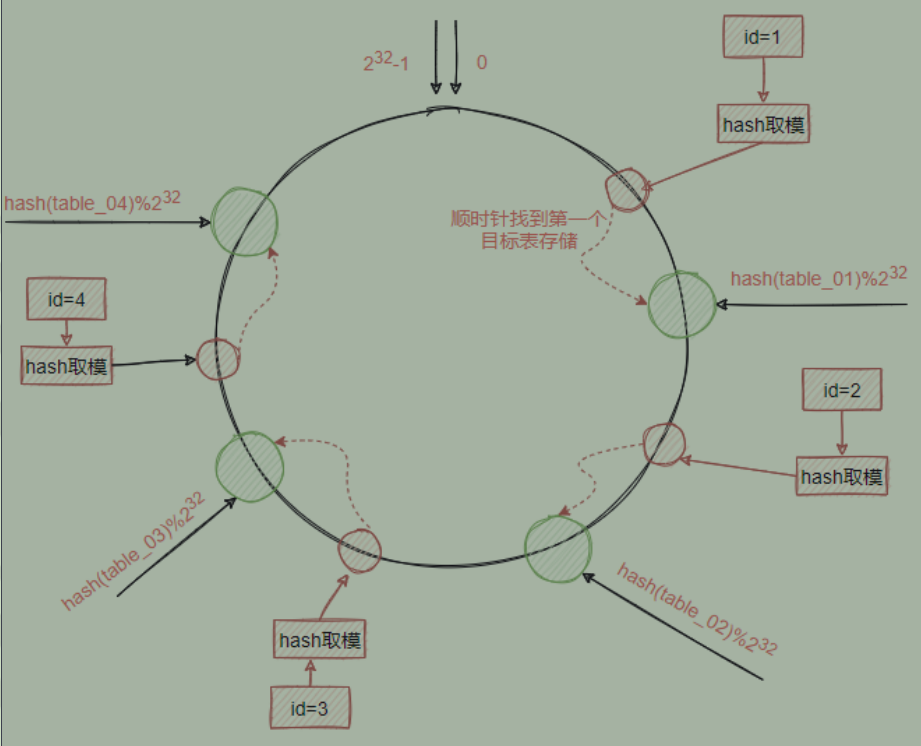
- 【一致性hash算法】:因为表的数量增加从而导致数据迁徙的问题,所以才引入了一致性hash算法。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2的23次方-1。那么这个圆环的最顶端就是0,他的左侧就是2的32次方-1,他的右侧就是1,2,。。。一直到2的32次方减一。简而言之,就是用这些数字围成一个虚拟的hash环。
- 假设 :现在有四个表,table_1、table_2、table_3、table_4,在一致性hash算法中,取模运算不是直接对这四个表来完成,而是对2的32次方来实现。
- 流程如下:
- 通过 hash(table编号)%2的32次方算出一个0-2的32次方减一的数字
- 当添加一条数据时,同样通过hash和hash环取模运算得到一个目标值,然后根据目标值所在的hash环的位置顺时针查找最近的一个目标表,把数据存储到这个目标
表中即可
好处:hash运算不是直接面向目标表,而是面向hash环,当需要删除某张表或者增加表的时候,对于整个数据变化的影响是局部的,而不是全局。
假设我们发现需要增加一张表table_04,增加一个表,并不会对其他四个已经产生了数据的表造成影响,原来已经分片的数据完全不需要做任何改动。
- 坏处【hash环偏斜 】:理论情况下我们目标表是能够均衡的分布在整个hash环中,但是有可能在计算的时候导致了计算出来的数据的区间挨的比较近,这种现象导致的问题就是大量的数据都会保存到同一个表中,导致数据分配极度不均匀。
- 解决方案:把这四个节点分别复制一份出来分散到这个hash环中,这个复制出来的节点叫虚拟节点,根据实际需要可以虚拟出多个节点出来。
- 【范围分片】
- 其实就是基于数据表的业务特性,按照某种范围拆分,一个重要的因素就是分片键,如果说现在是根据ID进行分片的,但是想通过名称去查询,那肯定查询不到。所以在选择分片键的时候一定要慎重,需要去调研。常见的有。
分库分表实战
分析假设存在一个用户表,用户表的字段如下。
首先我们要知道这个表格有什么功能:注册、登录、查询、修改等功能。
然后要知道它的使用范围:【因为我们要知道大部分的情况下是使用那个字段进行查询的,如果大部分是通过id那我使用id进行数据分片就能解决很多问题】
用户端:
- 用户登录,面向C端,对可用性和一致性要求较高,主要通过login_name、email、phone来查询用户信息,1%的请求属于这种类型
- 用户信息查询,登录成功后,通过uid来查询用户信息,99%属于这种类型。
运营端:主要是运营后台的信息访问,需要支持根据性别、手机号、注册时间、用户昵称等进行分页查询,由于是内部系统,访问量较低,对可用性一致性要求不高。这种情况下只能通过映射表,或者es进行处理了。
实践
通过上面的分析我们得知99%的请求是基于uid进行用户信息查询,所以毫无疑问我们选择使用uid进行水平分表。那么这里我们采用uid的hash取模方法来进行分表。
但是这里有一个问题,我们需要提前解决;我们知道当单个表中,我们使用递增主键来保证数据的唯一性,但是如果把数据拆分到了四个表,每个表都采用自己的递增主键规则,就会存在重复id的问题,也就是说递增主键不是全局唯一的。因此我们需要考虑如何生成一个全局唯一ID。有很多方式我们可以进行生成全局ID
- 数据库自增ID(定义全局表)缺点:当DB异常时整个系统不可用,属于致命问题
- UUID:在Java中,提供了基于MD5算法的UUID、以及基于随机数的UUID 优点:简单 缺点:不易于存储:UUID太长、无序查询效率低
- Redis的原子递增
- Twitter-Snowflflake算法:使用一个 64 bit 的 long 型的数字作为全局唯一 id,这64个bit位由四个部分组成。
- 1bit位,用来表示符号位,而ID一般是正数,所以这个符号位一般情况下是0
- 占41 个 bit 表示的是时间戳,是系统时间的毫秒数,但是这个时间戳不是当前系统的时间,而是当前 系统时间-开始时间 ,更大的保证这个ID生成方案的使用的时间
目的是为了保证有序性,可读性。- 美团的leaf
- MongoDB的ObjectId
- 百度的UidGenerator
添加数据的时候:首先通过雪花算法生成一个id,然后通过一致性hash算法得到目标表,然后使用mybatis的拦截器进行拦截,同时路由到算出来的表名中的表中
查询数据的时候: 还是使用一致性算法通过id获得目标表格,然后查询数据即可
一个添加的例子
雪花算法工具类
 View Codepublic class SnowFlakeGenerator { //下面两个每个5位,加起来就是10位的工作机器id private long workerId; //工作id private long datacenterId; //数据id //12位的序列号 private long sequence; public SnowFlakeGenerator(long workerId, long datacenterId, long sequence){ // sanity check for workerId if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId)); } System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d", timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId); this.workerId = workerId; this.datacenterId = datacenterId; this.sequence = sequence; } //初始时间戳 private long twepoch = 1626357044220L; //长度为5位 private long workerIdBits = 5L; private long datacenterIdBits = 5L; //最大值 private long maxWorkerId = -1L ^ (-1L << workerIdBits); private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); //序列号id长度 private long sequenceBits = 12L; //序列号最大值 private long sequenceMask = -1L ^ (-1L << sequenceBits); //工作id需要左移的位数,12位 private long workerIdShift = sequenceBits; //数据id需要左移位数 12+5=17位 private long datacenterIdShift = sequenceBits + workerIdBits; //时间戳需要左移位数 12+5+5=22位 private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; //上次时间戳,初始值为负数 private long lastTimestamp = -1L; public long getWorkerId(){ return workerId; } public long getDatacenterId(){ return datacenterId; } public long getTimestamp(){ return System.currentTimeMillis(); } //下一个ID生成算法 public synchronized long nextId() { long timestamp = timeGen(); //获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常 if (timestamp < lastTimestamp) { System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp); throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } //获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { timestamp = tilNextMillis(lastTimestamp); } } else { sequence = 0; } //将上次时间戳值刷新 lastTimestamp = timestamp; /** * 返回结果: * (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数 * (datacenterId << datacenterIdShift) 表示将数据id左移相应位数 * (workerId << workerIdShift) 表示将工作id左移相应位数 * | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。 * 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id */ return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence; } //获取时间戳,并与上次时间戳比较 private long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } //获取系统时间戳 private long timeGen(){ return System.currentTimeMillis(); } }
View Codepublic class SnowFlakeGenerator { //下面两个每个5位,加起来就是10位的工作机器id private long workerId; //工作id private long datacenterId; //数据id //12位的序列号 private long sequence; public SnowFlakeGenerator(long workerId, long datacenterId, long sequence){ // sanity check for workerId if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId)); } System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d", timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId); this.workerId = workerId; this.datacenterId = datacenterId; this.sequence = sequence; } //初始时间戳 private long twepoch = 1626357044220L; //长度为5位 private long workerIdBits = 5L; private long datacenterIdBits = 5L; //最大值 private long maxWorkerId = -1L ^ (-1L << workerIdBits); private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); //序列号id长度 private long sequenceBits = 12L; //序列号最大值 private long sequenceMask = -1L ^ (-1L << sequenceBits); //工作id需要左移的位数,12位 private long workerIdShift = sequenceBits; //数据id需要左移位数 12+5=17位 private long datacenterIdShift = sequenceBits + workerIdBits; //时间戳需要左移位数 12+5+5=22位 private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; //上次时间戳,初始值为负数 private long lastTimestamp = -1L; public long getWorkerId(){ return workerId; } public long getDatacenterId(){ return datacenterId; } public long getTimestamp(){ return System.currentTimeMillis(); } //下一个ID生成算法 public synchronized long nextId() { long timestamp = timeGen(); //获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常 if (timestamp < lastTimestamp) { System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp); throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } //获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { timestamp = tilNextMillis(lastTimestamp); } } else { sequence = 0; } //将上次时间戳值刷新 lastTimestamp = timestamp; /** * 返回结果: * (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数 * (datacenterId << datacenterIdShift) 表示将数据id左移相应位数 * (workerId << workerIdShift) 表示将工作id左移相应位数 * | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。 * 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id */ return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence; } //获取时间戳,并与上次时间戳比较 private long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } //获取系统时间戳 private long timeGen(){ return System.currentTimeMillis(); } }hash一致性算法工具类
View Codepublic class ConsistentHashing { /** * 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好 */ private static List<String> realNodes = new LinkedList<String>(); /** * 虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称 */ private static SortedMap<Integer, String> virtualNodes = new TreeMap<Integer, String>(); /** * 虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应5个虚拟节点 */ private static final int VIRTUAL_NODES = 5; static{ // 先把原始的服务器添加到真实结点列表中 Collections.addAll(realNodes, Constants.USER_INFO_TABLES); // 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高 for (String str : realNodes){ for (int i = 0; i < VIRTUAL_NODES; i++){ String virtualNodeName = str + "&&VN" + i; int hash = getHash(virtualNodeName); virtualNodes.put(hash, virtualNodeName); } } } /** * 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别 */ private static int getHash(String str){ final int p = 16777619; int hash = (int)2166136261L; for (int i = 0; i < str.length(); i++) { hash = (hash ^ str.charAt(i)) * p; } hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) { hash = Math.abs(hash); } return hash; } /** * 得到应当路由到的结点 */ public static String getServer(String node){ // 得到带路由的结点的Hash值 int hash = getHash(node); // 得到大于该Hash值的所有Map SortedMap<Integer, String> subMap = virtualNodes.tailMap(hash); // 第一个Key就是顺时针过去离node最近的那个结点 Integer i = subMap.firstKey(); // 返回对应的虚拟节点名称,这里字符串稍微截取一下 String virtualNode = subMap.get(i); return virtualNode.substring(0, virtualNode.indexOf("&&")); } }具体实现
View Codepublic void signal(@RequestBody UserInfo userInfo){ //生成id Long bizId=snowFlakeGenerator.nextId(); userInfo.setBizId(bizId); //一致性hash算法得到目标表 String table=ConsistentHashing.getServer(bizId.toString()); log.info("UserInfoController.signal:{}",table); //mybatis修改表名,重定向 MybatisPlusConfig.TABLE_NAME.set(table); userInfoService.save(userInfo); }


分库分表问题
有时候通过非分片键查询如果知道查询那个表?:
- 分片键和分片键建立映射关系,比如查询电话,那就通过id去获取表,然后在查询相关表。
- key-value进行缓存
有时候在运营这边会有多个条件查询,上面的这种方式就不合适了,怎么办?把数据库分离,因为运营这边查询的要求不是那么高,我们可以进行异步同步数据的方式,把客户端的数据库同步到运营端这样就可以了。如果数据需要分页如何处理?这个时候只能在代码这里进行查询,并且组装,或者存储在nosql中在实际应用中,并不是一开始就会想到未来会对这个表做拆分,因此很多时候我们面临的问题是在数据量已经达到一定瓶颈的时候,才开始去考虑这个问题。所以分库分表最大的难点不是在于拆分的方法论,而是在运行了很长时间的数据库中,如何根据实际业务情况选择合适的拆分方式,以及在拆分之前对于数据的迁移方案的思考。而且,在整个数据迁移和拆分过程中,系统仍然需要保持可用。对于运行中的表的分表,一般会分为三个阶段。
- 新老库双写
- 老的数据库表和新的数据库表同步写入数据,事务的成功以老的模型为准,查询也走老的模型
- 以新的模型为准【历史数据已经导完了,并且校验数据没有问题】
- 仍然保持数据双写,但是事务的成功和查询都以新模型为准。
- 结束双写【数据已经完成迁徙】
- 取消双写,所有数据只需要保存到新的模型中,老模型不需要再写入新的数据。