前言:为什么需要第二篇文件操作?因为第一篇的知识根本不足以支撑基本的需求。下面来一一分析。
一、Python文件操作的特点
首先来类比一下,作为高级编程语言的始祖,C语言如何对文件进行操作?
|
字符(串):fputc和fgetc,fputs和fgets,fwrite和fread,fprintf和fscanf都可以 整型:fputc和fgetc(-128~127范围内),rwrite和fread,fprintf和fscanf 数组(基本类型):for循环内的fputc和fgetc,for循环内的rwrite和fread,for循环内的fprintf和fscanf 结构体:fwrite和fread 结构体数组:for循环内的fwrite和fread |
其中,用fputc、fputs方式在文件中写入数据,只能写入字符型,每个字符占1个字节,用fgetc、fgets读取出来也是字符型;
用fwrite和fread写入、读出的类型,和内存中数据保持一致,也就是说,写进入的是int型,读出的就是int型,写入一个结构体,读出的就是结构体,原原本本地复原。
简而言之,C语言可以随意地写入数据,再随意地读取,只需要保证,怎么写进去的就怎么读出来,顺序和方式都保持一致,就不会出错。
而Python呢?
只有一种写入方式:
f.write() #写入的数据必须是字符串
只有四种读取方式:
|
data=f.read() #读取文件全部数据赋给字符变量data data=f.read(5) #读取5个字节的数据赋给字符变量data data=f.readline() #读取一行数据赋给字符变量data data=f.readlines() #读取全部数据,按行转化成列表赋给data,所有数据均为字符串 |
发现特点了吗?Python文件只能以字符型写入,以字符型读出。
问题就来了,如果没有方法使得保存在文件中的数据,读入内存时转化成我们需要的数据类型,那问题就大了。
幸运的是,有。
通过观察读写方式,还可以发现一个特点,即最好一个数据只能占一行,不要随意写入,读取也用readlines(),每个数据为列表中一个元素
如果将若干个数据写入文件,在文件中都存在雨一行,读取的时候将得到一个字符串,包含了原先的若干数据。
而在C语言中不必在意这么多。
二、如何在Python中写入并读取各种类型的数据?
1.如果只是对单个数据操作:
字符:直接写入,直接用f.read()或f.readline()读取
整型:将其转化成字符型写入,f.readline()读出再强转成int(不存在C语言中-128~127的范围限制,原因是Python中将int转化成str后,一位数字占一个字节)
列表:
①用for循环将列表中每个数据强转成字符串分行写入文件,再用f.readlines()读出。(局限性大,如果列表中数据不止有字符型,将会难以恢复原来的样子)
②将整个列表强转为字符型写入,再用readline()读出后,用eval函数转化成列表。关于eval函数,后面详细讲。
字典:将字典强转为字符型写入,再用readline()读出后,eval函数将字符串转化为字典。
集合:将集合强转为字符型写入,再用readlin()读出后,eval函数将字符串转化为集合。
2.如果对同种类型多个数据操作:
多个字符:①分行写入,分行读取或者readlines()
②一个一个写入(都在同一行),每个数据间加上空格或者其他的分割符,readline()读取,用split函数按照指定的分隔符分割成一个一个的字符(串)
多个整型:①分行写入(转化成字符型),分行读取或者readlines(),再转化成int型
②一个一个写入(都在同一行),每个数据间加上空格或者其他的分割符,readline()读取,用split函数按照指定的分隔符分割成一个一个的字符(串)
多个列表:①将每个元素分行写入文件,再用readlines()读取(适用于列表元素类型单一的情况)
②看下文
多个字典:看下文
多个集合:看下文
三、如何将多个不同类型的数据混合写入并读取?
上面说了那么多,终归感觉比较局限,有没有一种通用规范的方式,可以将多个相同和不同的数据写入文件?
我总结了一下:
1.适用于小文件,不对内存造成压力的情况:
①每个数据存一行(列表、字典等作为一个数据)
②读取时用readlines()将所有数据构成一个大列表
③再将不同的数据用eval函数转化成想要的数据类型
下面给出实例:
1 goods = [[1, "土豆", "3元/kg", 3], [2, "香蕉", "2元/kg", 2], [3, "可乐", "3.5元/瓶", 3.5],
2 [4, "薯片", "4元/袋", 4], [5, "面包", "6元/个", 6], [6, "手机", "200/部", 200]]
3 recd={
4 'backend': 'www.bokeyuan.org',
5 'record': {
6 'server': '100.1.7.9',
7 'weight': 20,
8 'maxconn': 3000
9 }
10 }
11
12 f=open("yesterday3","w",encoding="utf-8")
13 f.write(str(goods)) #直接将列表转化成字符写入文件
14 f.write("
") #换行符
15 f.write(str(recd)) #将字典转化成字符写入文件
16 f.write("
")
17 f.close()
18
19 f=open("yesterday3","r",encoding="utf-8")
20 data=f.readlines() #读取全部数据
21 f.close()
22
23 gooded=data[0] # 将大列表第一个数据(字符列表)赋给另一个变量
24 dic=data[1] # 将大列表第二个数据(字符字典)赋给另一个变量
25
26 gooded=eval(gooded) # 将字符串列表转化成列表
27 dic=eval(dic) # 将字符串字典转化为字典
28
29 print(gooded) #输出列表和字典
30 print(dic)
输出结果为:
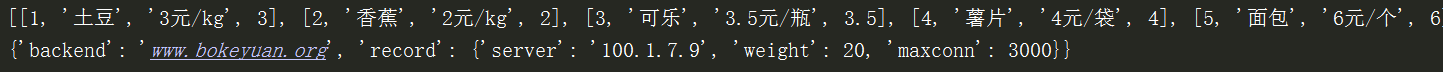
为了验证不是字符串,访问一下
print(gooded[1][1])
print(dic["record"]["server"])
访问结果:

2.如果是大文件,即列表(字典等)本来就含有大量数据:
以列表为例:
①每个列表建议存一个文件,一个元素占一行。小型数据(单个的字符、整型)可以分行存入另一个文件。
②新建一个空列表,用迭代器一行一行读取文件,将每一行字符串赋给新列表作为元素
③用枚举for循环的方式,循环地用eval函数将字符串复原数据类型
实例:
1 goods = [[1, "土豆", "3元/kg", 3], [2, "香蕉", "2元/kg", 2], [3, "可乐", "3.5元/瓶", 3.5],
2 [4, "薯片", "4元/袋", 4], [5, "面包", "6元/个", 6], [6, "手机", "200/部", 200]]
3
4 f=open("yesterday3","w",encoding="utf-8")
5 for i in goods:
6 f.write(str(i)) #循环将列表每一个元素转化成字符串写入文件
7 f.write("
")
8 f.close()
9
10 gooded=[] #新建列表
11 f=open("yesterday3","r",encoding="utf-8")
12 for i in f:
13 gooded.append(i) #将每一行数据循环赋给新列表的元素
14 f.close()
15
16 for i,j in enumerate(gooded): # 将字符串列表转化成二级列表
17 gooded[i]=eval(j)
18
19 print(gooded) #输出列表
20 print(gooded[1][1]) #列表访问
运行结果:

四、文件修改的完善
在上一篇博客中,关于大文件的修改,需要新建一个文件,将修改后的内容写入新文件,同时保留旧文件。
但在实际应用中,如果用户经常修改数据,会产生至少两个副作用:
①旧文件越来越多,而新文件只有一个,占用存储空间
②新文件的文件名需要人为维护
解决他们非常简单,删除旧文件和重命名新文件就可以了
需要引入os模块
import os os.remove("文件名") #删除文件 os.rename("旧文件名","新文件名") #重命名文件
五、二进制文件和文本文件的区别
二者没有本质的区别,确切的说文本文件也属于二进制文件,区别在于应用程序或打开方式对文件的解释不同
1. 能存储的数据类型不同
文本文件只能存储char型字符变量。
二进制文件可以存储char/int/short/long/float/……各种变量值。
2. 每条数据的长度
文本文件每条数据通常是固定长度的。以ASCII为例,每条数据(每个字符)都是1个字节。
二进制文件每条数据不固定。如short占两个字节,int占四个字节,float占8个字节……
3. 读取的软件不同
文本文件编辑器就可以读写。比如记事本、NotePad++、Vim等。
二进制文件需要特别的解码器。比如bmp文件需要图像查看器,rmvb需要播放器……
4. 操作系统对换行符('
')的处理不同(不重要)
文本文件,操作系统会对'
'进行一些隐式变换,因此文本文件直接跨平台使用会出问题。
①在Windows下,写入' '时,操作系统会隐式的将' '转换为" ",再写入到文件中;读的时候,会把“ ”隐式转化为' ',再读到变量中。
②在Linux下,写入' '时,操作系统不做隐式变换。
六、特别介绍几个实用的函数
1.eval()
这是一个非常神奇的函数!可以将字符串转化成对应的数据类型。
但是使用时需要注意:被转化的字符串必须和真实类型长得完全一模一样,否则无法转化。
给出实例:
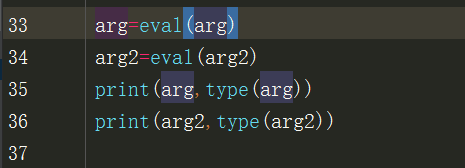
1 arg='''{"a":123,"b":456}'''
2
3 arg2='''{
4 "a":123,
5 "b":456
6 }'''
7
8 arg=eval(arg)
9 arg2=eval(arg2)
10 print(arg,type(arg))
11 print(arg2,type(arg2))
12
13 #输出结果:
14 {'a': 123, 'b': 456} <class 'dict'>
15 {'a': 123, 'b': 456} <class 'dict'>
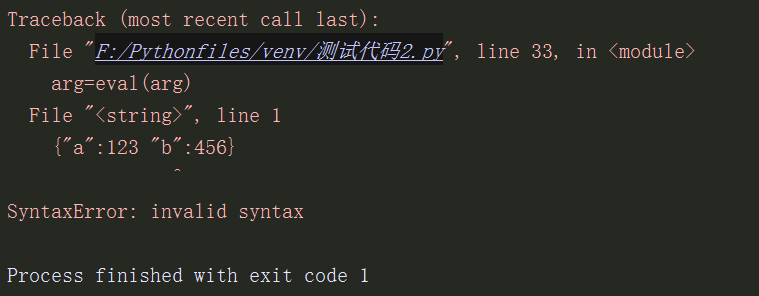
现在如果字符串写的不规范:
arg='''{"a":123 "b":456}'''
arg2='''{
a:123,
b:456
}'''
运行报错:
接下来试一下其他数据类型:
1 a=[1,1,2,3,4]
2 b=("hello","nihao")
3 c=set([10,5,1,1,4])
4 d={1:"wawoo",2:"thank"}
5 e=5
6 f="hello"
7 print("转化前:")
8 print(type(a))
9 print(type(b))
10 print(type(c))
11 print(type(d))
12 print(type(e))
13 print(type(f))
14
15 #转化成字符串
16 a1=str(a)
17 b1=str(b)
18 c1=str(c)
19 d1=str(d)
20 e1=str(e)
21 f1=str(f)
22
23 #转化回原来的类型
24 a1=eval(a1)
25 b1=eval(b1)
26 c1=eval(c1)
27 d1=eval(d1)
28 e1=eval(e1)
29
30 print("转化后:")
31 print(type(a1))
32 print(type(b1))
33 print(type(c1))
34 print(type(d1))
35 print(type(e1))
36 print(type(f1))
运行结果:
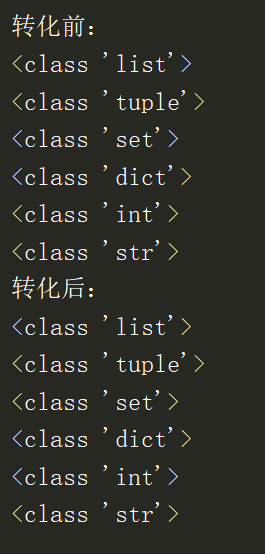
完美转化
2.sort()和sorted()
sort是容器的函数:sort(cmp=None, key=None, reverse=False)
sorted是python的内建函数:sorted(iterable, cmp=None, key=None, reverse=False)
参数解析:
cmp:比较函数,比较什么参数由key决定。例如:cmp(e1, e2) 是具有两个参数的比较函数,返回值:负数(e1 < e2);0(e1 == e2);正数( e1 > e2)。
key:用列表元素的某个属性或函数作为关键字。
reverse:排序规则,可以选择True或者False。
sorted多一个参数iterable:待排序的可迭代类型的容器
示例1:
a=[1,2,5,3,9,4,6,8,7,0,12]
a.sort()
print(a)
#运行结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 12]
a=[1,2,5,3,9,4,6,8,7,0,12]
a2=print(sorted(a))
print(a2)
print(a)
#运行结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 12]
[1, 2, 5, 3, 9, 4, 6, 8, 7, 0, 12]
区别:
对于一个无序的列表a,调用a.sort(),对a进行排序后返回a,sort()函数修改待排序的列表内容。
而对于同样一个无序的列表a,调用sorted(a),对a进行排序后返回一个新的列表,而对a不产生影响。
示例2:
假设用元组保存每一个学生的信息,包括学号,姓名,年龄。用列表保存所有学生的信息。
list1=[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
list1.sort()
print( list1)
#运行结果:
[(2, 'Mike', 22), (5, 'Lucy', 19), (8, 'Logan', 20)]
list1=[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
list2=sorted(list1)
print(list2)
print(list1)
#运行结果:
[(2, 'Mike', 22), (5, 'Lucy', 19), (8, 'Logan', 20)]
[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
小结:由示例可以看出,当列表由list(或者tuple)组成时,默认情况下,sort和sorted都会根据list[0](或者tuple[0])作为排序的key,进行排序。
以上都是默认的排序方式,我们可以编写代码控制两个函数的排序行为。主要有三种方式:基于key函数;基于cmp函数和基于reverse函数
1)基于key函数排序
list1=[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
list1.sort(key=lambda x:x[2])
print( list1)
#运行结果:
[(5, 'Lucy', 19), (8, 'Logan', 20), (2, 'Mike', 22)]
list1=[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
list2=sorted(list1, key=lambda x:x[2])
print(list2)
print( list1)
#运行结果:
[(5, 'Lucy', 19), (8, 'Logan', 20), (2, 'Mike', 22)]
[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
2)基于cmp函数
list1=[(8, 'Zogan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
list1.sort(cmp=lambda x,y:cmp(x[1],y[1]))
print( list1)
#运行结果:
[(5, 'Lucy', 19), (2, 'Mike', 22), (8, 'Zogan', 20)]
list1=[(8, 'Zogan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
list2=sorted(list1, cmp=lambda x,y:cmp(x[1],y[1]))
print(list1)
#运行结果:
[(5, 'Lucy', 19), (2, 'Mike', 22), (8, 'Zogan', 20)]
[(8, 'Zogan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)]
3)基于reverse函数
a=[1,2,5,3,9,4,6,8,7,0,12]
a.sort(reverse=False)
print(a)
#运行结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 12]
a=[1,2,5,3,9,4,6,8,7,0,12]
a2=a.sort(reverse=True)
print(a2)
#运行结果:
[12, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
小结:reverse=False为升序排序;reverse=True为降序排序
3.split()
split() 通过指定分隔符对字符串进行分隔,并返回分割后的字符串列表。如果参数 num 有指定值,则仅分隔 num 个子字符串
split(str,num)
参数:
str:分隔符,默认为所有的空字符,包括空格、换行( )、制表符( )等。
num: 分割次数(可以省略)
str = "Line1-abcdef
Line2-abc
Line4-abcd"
print str.split( )
print str.split(' ', 1 )
#运行结果:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '
Line2-abc
Line4-abcd']