20162317袁逸灏 第四周实验报告:实验二 树
实验内容
- 实现二叉树
- 中序先序序列构造二叉树
- 决策树
- 表达式树
- 二叉查找树
- 红黑树分析
实验要求
- 参考教材p375,完成链树LinkedBinaryTree的实现
- 基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能
- 完成PP16.6
- 完成PP16.8
- 完成PP17.1
- 对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果
实验过程
实验二 - 1 - 实现二叉树
- 实现getRight()方法
P375中的代码有一个getLeft()方法,通过画葫芦画瓢(滑稽)将
result.root = root.getLeft();
改为
result.root = root.getRight();
即可。
- 实现contains(T taget)
代码中提供了一个find(T target)的方法,通过find(T target)方法来协助即可。
- 实现preorder()、postorder()方法
preorder的方法是用于提供前序遍历树用的,postorder方法是用于体统后序遍历树用的。这个方法重点在于BTNode中的preorder()和postorder()方法。实现了BTNode方法才能实现在LinkedBinaryTree的preorder()和postorder()方法。
public void inorder (ch16.ArrayIterator<T> iter)
{
//左子树
if (left != null)
left.inorder (iter);
//根
iter.add (element);
//右子树
if (right != null)
right.inorder (iter);
}
BTNode中有个 inorder()中序遍历树的方法,里面有三段函数,分别代表着查看左子树、根和右子树,这正是中序遍历的顺序。因此,只要将该三段函数位置交换即可:
BTNode.java
public void preorder(ch16.ArrayIterator<T> iter) {
iter.add (element);
if (left != null)
left.preorder (iter);
if (right != null)
right.preorder (iter);
}
public void postorder(ArrayIterator<T> iter) {
if (left != null)
left.postorder (iter);
if (right != null)
right.postorder (iter);
iter.add (element);
}
回到LinkedBinaryTree。同样,已经给出了inorder()方法的代码,剩下的只需要模仿即可:
LinkedBinaryTree.java
@Override
public Iterator<T> preorder() {
ArrayIterator<T> iter = new ArrayIterator<>();
if(root!=null){
root.preorder(iter);
}
return iter;
}
public Iterator<T> inorder()
{
ArrayIterator<T> iter = new ArrayIterator<T>();
if (root != null)
root.inorder (iter);
return iter;
}
@Override
public Iterator<T> postorder() {
ArrayIterator<T> iter = new ArrayIterator<T>();
if (root != null)
root.postorder (iter);
return iter;
}
运行效果:
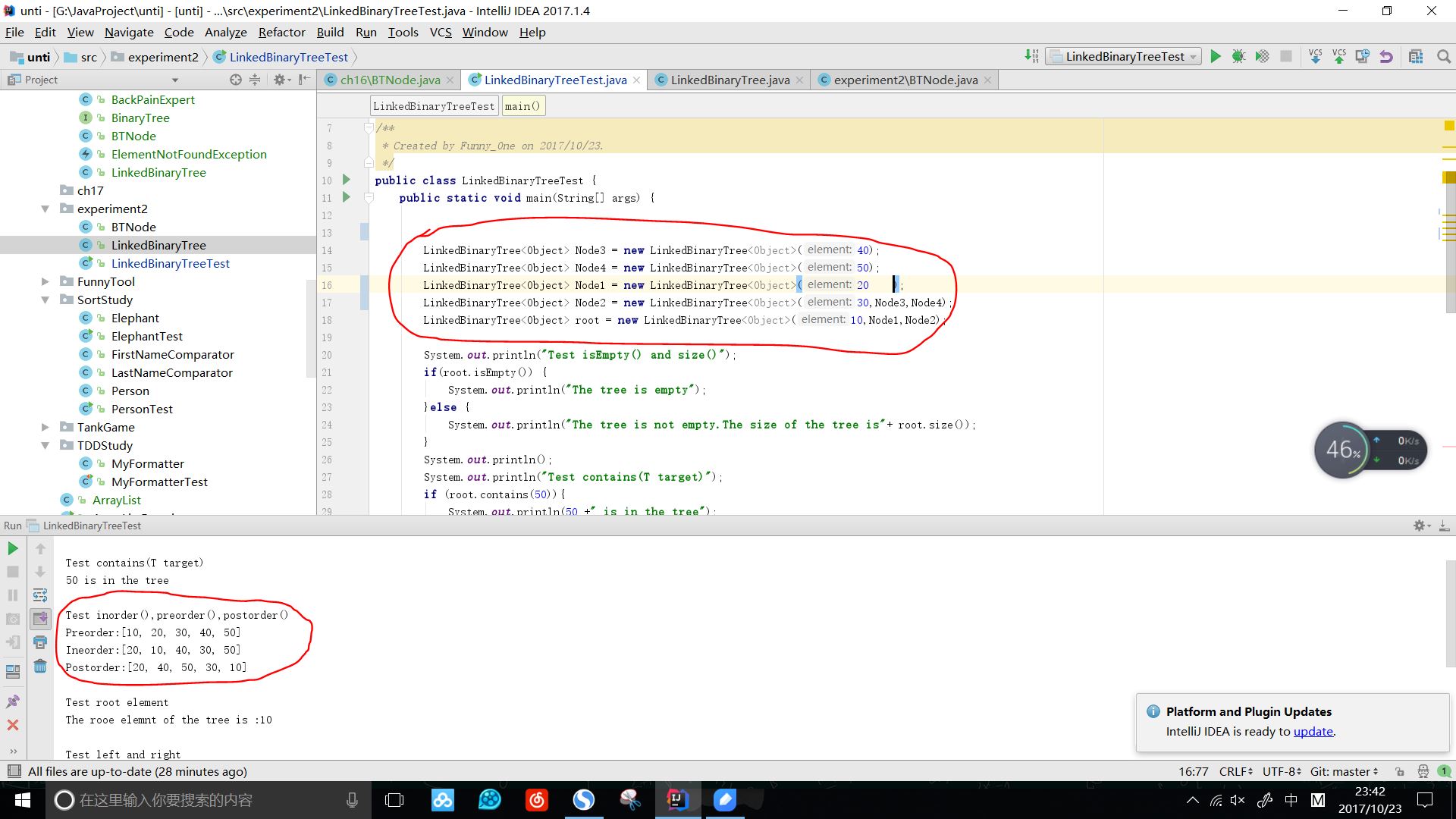
- 实现toString方法
我认为那么多方法中,这个方法是最难的,根据老师要求,要有这种效果:
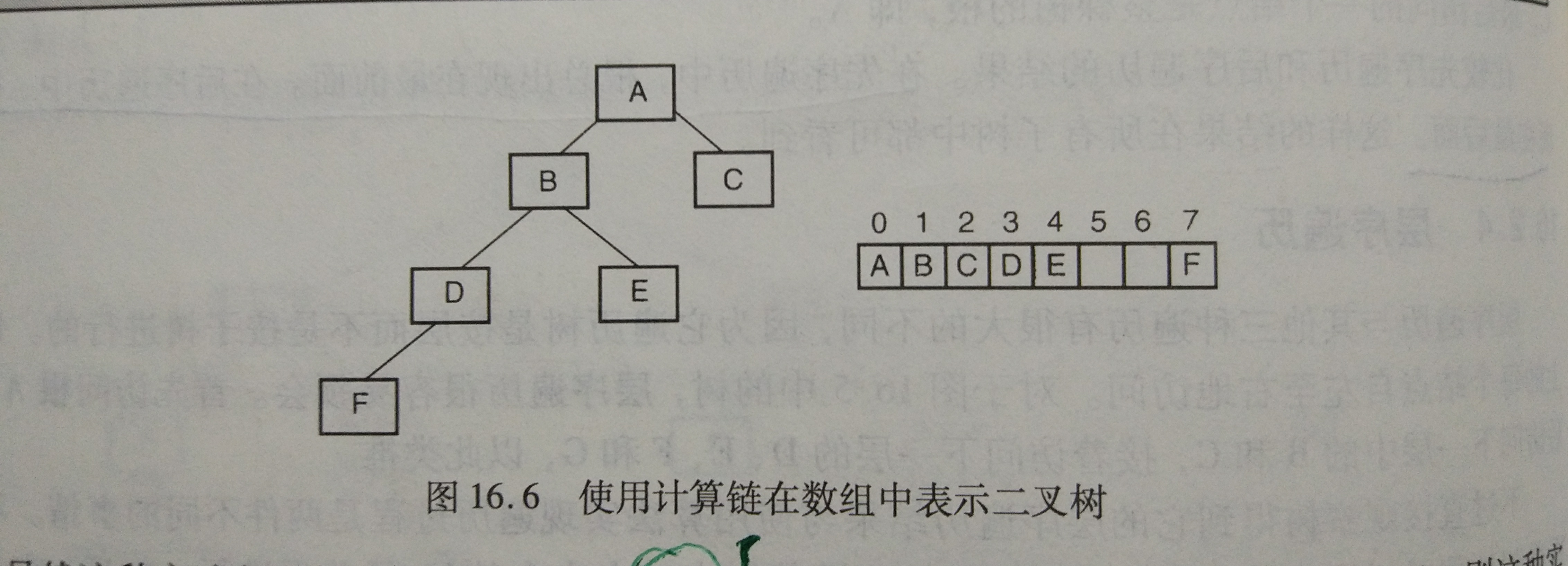
这种表示的方法的要点有:
- 1、元素的左子结点存储在(2n+1)的位置,元素的右子结点存储在(2X(n+1))的位置上
- 2、在最后一层之前,中间结点若只有一个子结点或为叶结点,要将位置空出来,最后一层的时候不需要这样的情况。
关于要点的解决办法:
- 要点1:开始的思路是想弄一个数组,这样容易用下标来进行位置的安放。但随着深入的思考与探索,发现实际上不用这么复杂,实际上的效果就是这样:

由此可见,要用到层序遍历来实现这一效果。
- 要点2:我的想法是首先通过树的性质来获得树的高度,同时可以知道每一层的元素数量是2^(n-1)那么多个。弄个双循环,外循环来负责层数,内循环负责元素个数,并在循环内设定条件语句:若不是最后一层,左/右结点不为空就填入,为空就填个空进去;当是最后一层的时候,就直接填入即可。
效果图:
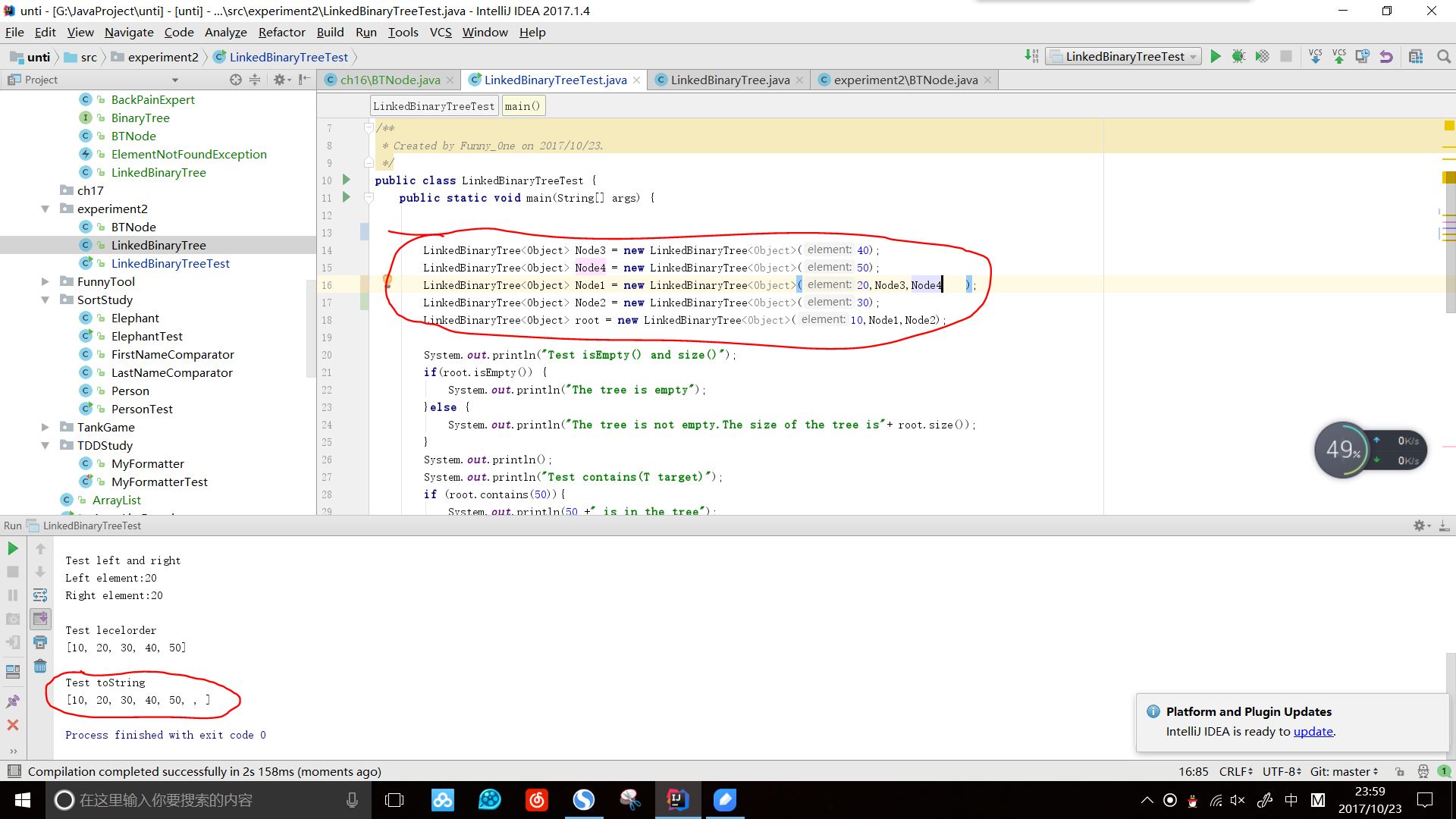
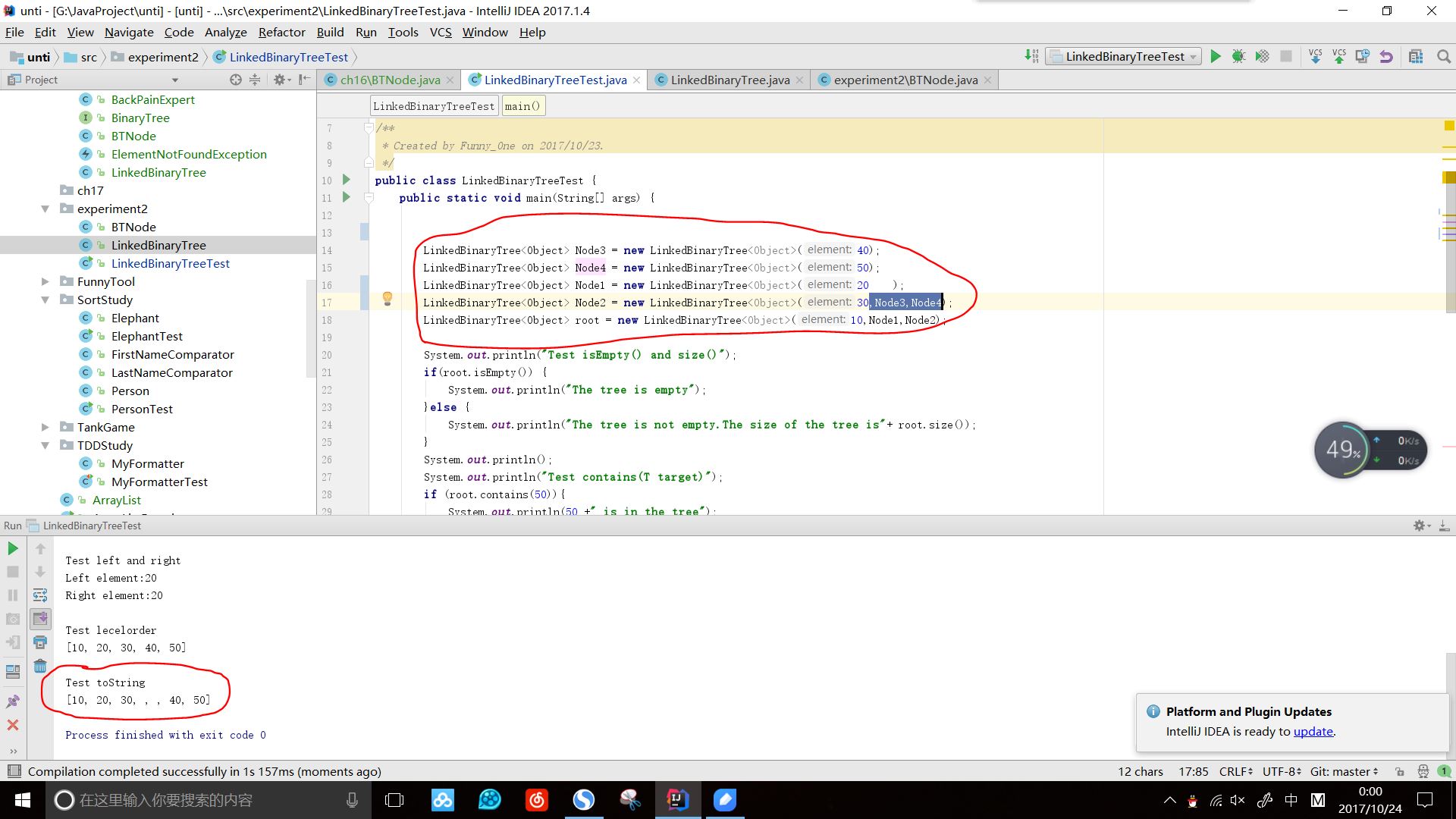
实验二 - 2 - 中序先序序列构造二叉树
(P.S.该代码一定程度上可以上网查找——原码来源:http://blog.csdn.net/huangcan0532/article/details/46776749 )
要想实现构造二叉树,就要知道先序和后序如何构造的唯一的一棵二叉树。

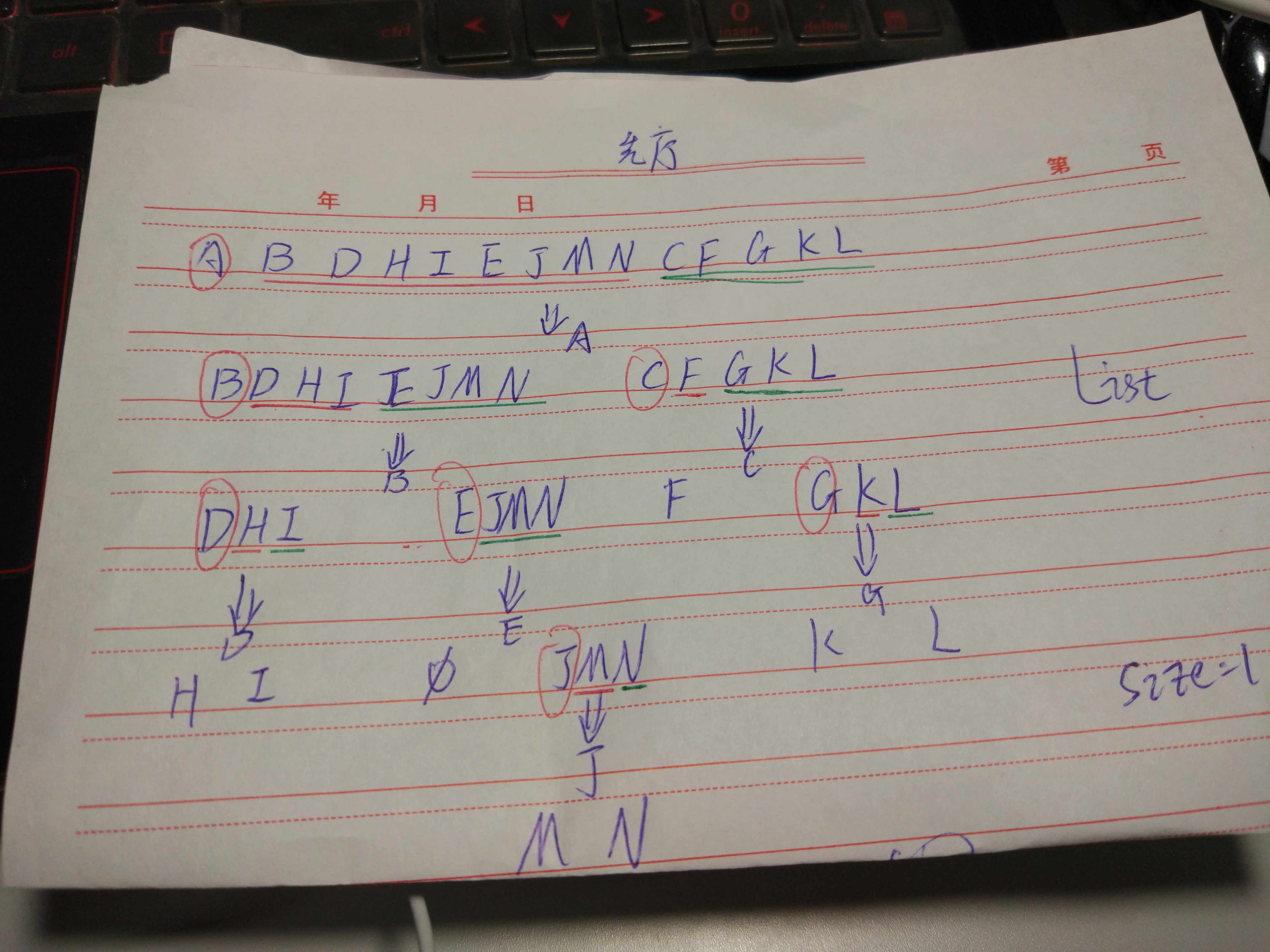
首先看先序的第一个元素作为根,然后在中序中找到该元素的位置,将剩余的元素分位左子树和右子树。再从两棵子树的前序中找第一个元素作为根,然后分别在这两棵子树的中序遍历中找到对应元素,将其再次一分为二,重复这样做,最后通过先序和后序获得一棵树。
这里想要实现以上功能最关键的地方在于递归,递归可以重复调用自己的方法,就可以不断生成左子树和右子树。
效果:
实验二-3-决策树
这个实验没有太重点的地方,主要在于这个任务是个体力活(在于设定问题和答案以及之间的逻辑结构问题)。该试验实际上想表达的是树所能完成的任务。决策树就是其中之一,除了这次完成的实验,日后的决策树还可以作为一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。可以用在开发上来评价项目或步骤的风险。
实验效果:
实验二-4-表达式树
该试验的难点就在于如何实现。我们可以使用后缀表达式来建立一棵树,我们先建立一个栈来存放结点,然后我们将输入的中缀表达式转化为后缀表达式,再遍历该后缀表达式表达式。如果遇到是操作数,那么就建立一个单结点树并将它推入栈中。如果符号是操作符,那么就从栈中弹出两棵树T1和T2(T1先弹出)并形成一棵新的树,该树的根就是操作符,它的左、右儿子分别是T2和T1。然后将指向这颗树的指针压入栈中。这棵树使用中序遍历的时候得到的是中缀表达式,后序遍历的时候得到的是后缀表达式,然后进行计算即可。
实验效果:
实验二 树-5-二叉查找树
该实验用到了第17章的二叉查找树
关于本人二叉查找树的可以浏览该博客:20162317 2017-2018-1 《程序设计与数据结构》第8周学习总结
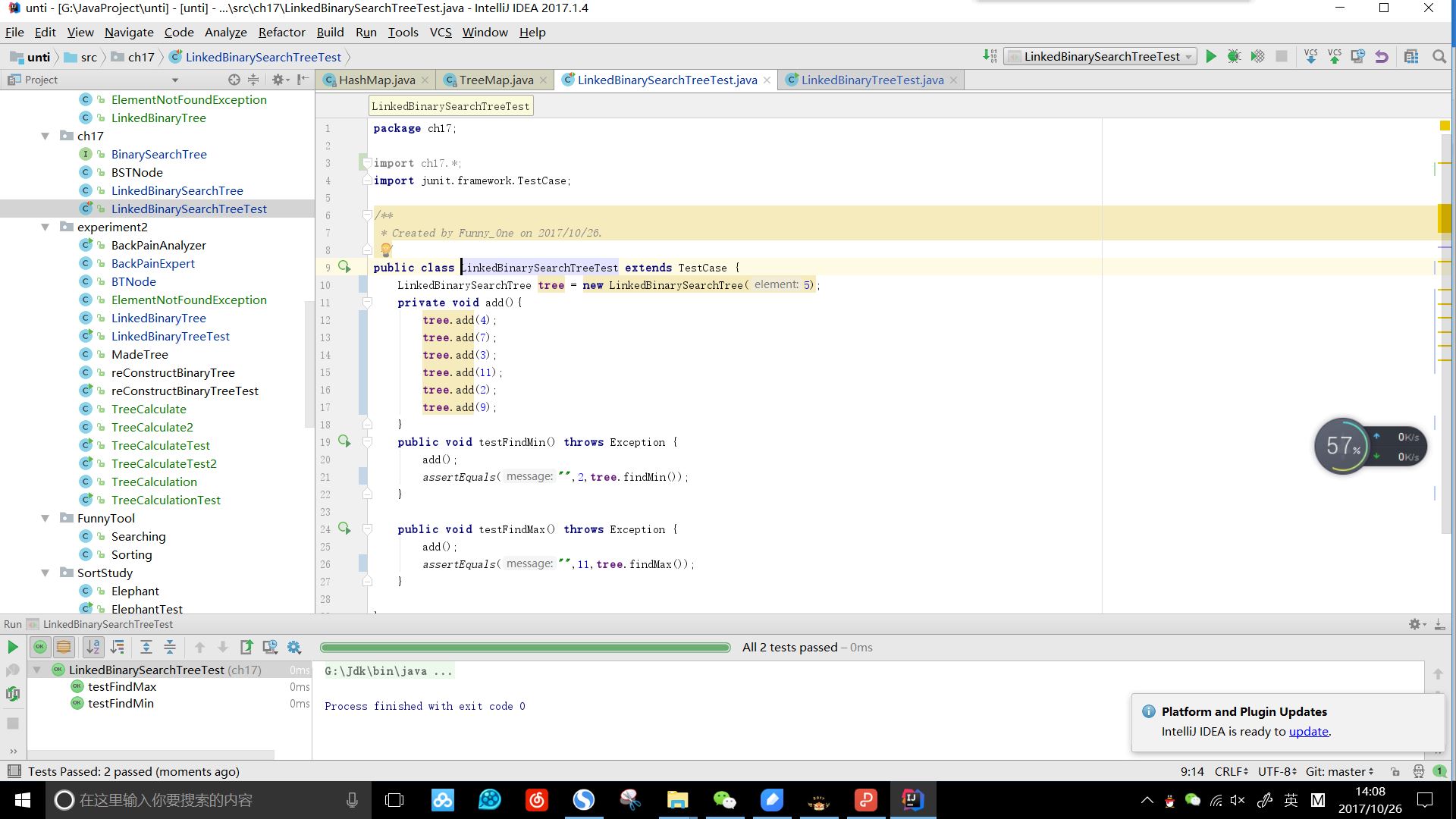
该实验的要求是将findMin()方法和findMax()方法实现。根据二叉查找树的性质:
1、比根节点要小的数会放在当前根节点的左子结点,因此要实现findMin()只要获取该树的最左边的结点即是最小值
@Override
public T findMin() {
if(root==null){
return null;
}
if(root!=null&&root.getLeft()==null){
return root.getElement();
}
BTNode MinNode = root;
while (MinNode.getLeft()!=null){
MinNode = MinNode.getLeft();
}
return (T) MinNode.getElement();
}
2、比根节点要大的数会放在当前根节点的右子结点,因此要实现findMax()只要获取该树的最右边的结点即是最大值
@Override
public T findMax() {
if(root==null){
return null;
}
if(root!=null&&root.getRight()==null){
return root.getElement();
}
BTNode MaxNode = root;
while (MaxNode.getRight()!=null){
MaxNode = MaxNode.getRight();
}
return (T) MaxNode.getElement();
}
测试效果:
实验二 树-6-红黑树分析
TreeMap
先介绍TreeMap中的几个基本变量,中途会用得比较多。
1、
private final Comparator<? super K> comparator;
用于保持顺序的比较器,如果为空的话使用自然顺保持Key的顺序。
2、
private transient Entry<K,V> root = null;
根节点。
3、
private transient int size = 0;
树中的节点数量。
4、
private transient int modCount = 0;
用来记录树结构改变的次数。
remove(Object key)
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
该方法先创建一个结点,通过getEntry(Object key)获取节点,若制定结点不在就返回null。然后获取结点的值(value),获取后将对应其删除,最后再返回结点的内容。
containsKey(Object key)
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
通过获取包含该值的结点,查看是否为空。
HashMap
put(K key V value)
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
若传入的键为空,将这个键值对添加到一个创建好的数组table的第一位tanle[0]。若键不为空,则计算该键的值,然后将其添加到对应的链表中,然后搜索指定hash值在对应table中的索引。循环遍历Entry数组,如果已存在该键,就用新的value取代旧的value,然后退出方法。
putAll(Map<? extends K, ? extends V> m)
public void putAll(Map<? extends K, ? extends V> m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
if (table == EMPTY_TABLE) {
inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold));
}
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
首先获取传入数组table的键值对的数量,如果本地数组table为空,则新建一个数组,如果传入map的键值对数比“下一次扩容后的内部数组大小”还大,则对数组进行扩容。(因为当前数组即使扩容后也装不下它)
实验知识点
- 二叉树
- 结点