本文转自 https://mp.weixin.qq.com/s/oj-DzpR-hZRMMziq2_0rYg备忘
MySQL主从复制一致性问题早已解决,然而主从复制延迟的问题依然困扰着开发人员和DBA。开发通常想将从机作为读写分离的一种选择,奈何复制延迟导致实际生产上,依然选择主实例(Master)作为查询源。对于DBA来说,高可用切换时,从发现到切换的整个过程堪称秒级切换,只是在最后开放写入这个过程中,需要大量时间等待从机的回放(Applier),整个过程被迫从秒级切换降级为分钟级切换。曾经DBA面试的一道经典题,其实是没有什么比较好的答案,因为这是MySQL复制机制的硬伤:
请问你是如果解决复制延迟的?
为此,MySQL从5.6版本开始支持并行复制机制,官方称为:MTS(Multi-Thread Slave),经过几个版本的迭代,目前MTS支持以下几种机制:
| 版本 | MTS机制 | 实现原理 |
|---|---|---|
| 5.6 | Database | 基于库级的并行复制 |
| 5.7 | COMMIT_ORDER | 基于组提交的并行复制 |
| 5.7.22 | WRITESET / WRITESET_SESSION |
基于WRITESET的并行复制 |
基于Database级别的并行复制效果并不特别好,因为大多数生产的架构依然习惯于单库多表的架构,这种情况下MTS依然还是单线程的效果。但Database级别并行复制的好处是可以兼容任何二进制日志,从机都可以进行库级别的并行回放。
基于Commit_Order的并行复制是在主数据库实例事务提交时,写入一些额外信息,从而在从机回放时,可以根据这些信息判断是否可以进行并行的回放。这种实现机制的巧妙之处在于:同一组提交的事务之间是不冲突的,因此可以并行回放
在代码实现中,同一组的事务拥有同一个parent_commit(父亲),在二进制日志中可以看到类似如下的内容:
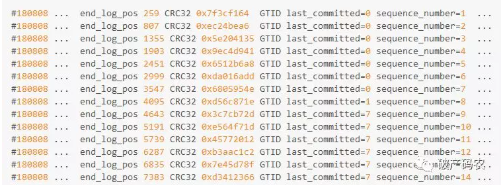
last_commit相同可视为具有相同的parent_commit,事务在同一组内提交,因此在从机回放时,可以并行回放。例如last_committed = 0的有7个事务,sequence_number 1 ~ 7,则这7个可以并行执行。last_committed = 7有6个事务,sequence_number 9 ~ 14,可以并行回放执行。
在上面的并行执行中,last_committed = 1 的事务需要等待last_committed = 0的7个事务完成,同理,last_committed = 7的6个事务需要等待last_committed = 1的事务完成。但是MySQL 5.7还做了额外的优化,可进一步增大回放的并行度。思想是LOCK-BASED,即如果两个事务有重叠,则两个事务的锁依然是没有冲突的,依然可以并行回放。
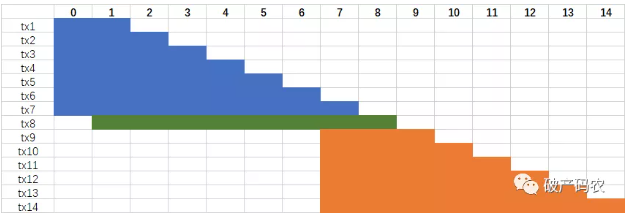
在上面的例子中,last_committed = 1的事务可以和last_committed = 0的事务同时并行执行,因为事务有重叠。具体来说,这表示last_committed = 0的事务进入到COMMIT阶段时,last_committed的事务进入到了PREPARE阶段,即事务间依然没有冲突。具体实现思想可见官方的Worklog: WL#7165: MTS: Optimizing MTS scheduling by increasing the parallelization window on master
基于COMMIT_ORDER的并行复制机制虽好,然而需要有一个条件:每组提交事务要足够多。即,业务量要足够大。但是当你的业务量比较小,并发度不够时,基于COMMIT_ORDER的并行复制依然会退化为单线程复制。虽然有经验的小伙伴知道可以通过调整参数binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count来优化组提交的效率,但最终的效果其实并不理想。只能说某些情况有些用,大部分情况依然然并卵。
为了进一步解决复制延迟问题,MySQL 5.7.22版本推出了基于WriteSet机制的并行复制,从机并行执行无需依赖组复制机制。简单来说,WriteSet并行复制的思想是:不同事务的不同记录不重叠,则都可在从机上并行回放,可以看到并行的力度从组提交细化为记录级。
所谓不同的记录,在MySQL中用WriteSet对象来记录每行记录,从源码来看WriteSet就是每条记录hash后的值(必须开启ROW格式的二进制日志),具体算法如下:
WriteSet=hash(index_name | db_name | db_name_length | table_name | table_name_length | value | value_length)
上述公式中的index_name只记录唯一索引,主键也是唯一索引。如果有多个唯一索引,则每条记录会产生对应多个WriteSet值。另外,Value这里会分别计算原始值和带有Collation值的两种WriteSet。所以一条记录可能有多个WriteSet对象。举例来说,下面的表t1,有2个唯一索引:
CREATE TABLE t1 (
a BIGINT NOT NULL AUTO_INCREMENT,
b VARCHAR(36) NOT NULL,
c INT NOT NULL,
PRIMARY KEY(a),
UNIQUE KEY idx_b(b)
)CHARSET=utf8mb4
当用户执行INSERT INTO test.t1 VALUES (NULL,UUID(),3)时,对产生多个个WriteSet值,分别是:
-
WriteSet1=hash(PRIAMRY|test|4|t1|2|1|8)
-
WriteSet2=hash(PRIAMRY|test|4|t1|2|1(with collation)|8)
-
WriteSet3=hash(idx_b|test|4|t1|2|'2'|1)
-
WriteSet4=hash(idx_b|test|4|t1|2|'2'(with collation)|1)
参数transaction_write_set_extraction用来选择hash函数,推荐设置为XXHASH64,相比MURMUR32有更好的散列性。产生的WriteSet对象会插入到WriteSet哈希表,哈希表的大小由参数binlog_transaction_dependency_history_size设置,默认25000。WriteSet哈希表的类型为std::map<uint64,int64>,保存每条记录的WriteSet值和对应的sequence_number。
当事务每次提交时,会计算修改的每个行记录的WriteSet值,然后查找哈希表中是否已经存在有同样的WriteSet,若无,WriteSet插入到哈希表,写入二进制日志的last_committed值不变。若有,则last_committed值更新为sequnce_number。
对于上面的INSERT语句,在插入后WriteSet哈希表中记录的内容为:
| Key | Value |
|---|---|
| WriteSet1 | 1 |
| WriteSet2 | 1 |
| WriteSet3 | 1 |
| WriteSet4 | 1 |
若这时另一个事务再次执行了INSERT INTO test.t1 VALUES (NULL,UUID(),3),则会产生新的WriteSet对象,但和上述的WriteSet没有冲突,直接插入WriteSet哈希表,表中内容更新为:
| Key | Value |
|---|---|
| WriteSet1 | 1 |
| WriteSet2 | 1 |
| WriteSet3 | 1 |
| WriteSet4 | 1 |
| WriteSet5 | 2 |
| WriteSet6 | 2 |
| WriteSet7 | 2 |
| WriteSet8 | 2 |
接着当用户执行DELETE FROM test.t1 WHERE a = 1,这时事务提交时会发现能在WriteSet哈希表中找到之前a=1对应的WriteSet,因此需要更新对应的sequence_number值,并且这时last_committed值也要更新为对应的sequence_number值:
| Key | Value |
|---|---|
| WriteSet1 | 3 |
| WriteSet2 | 3 |
| WriteSet3 | 3 |
| WriteSet4 | 3 |
| WriteSet5 | 2 |
| WriteSet6 | 2 |
| WriteSet7 | 2 |
| WriteSet8 | 2 |
回放时和基于COMMIT_ORDER的并行复制一样,具有相同的last_committed值可以并行回放,但是由于是基于WriteSet机制的,因此不同的记录能并行执行。同一条记录回放,last_committed值必然不同,必须等待之前的一条记录回放完成后才能执行。
默认MySQL依然还是基于库级别的并行复制配置,因此开启基于WriteSet并行复制需要进行如下的设置:
# master
loose-binlog_transaction_dependency_tracking = WRITESET
loose-transaction_write_set_extraction = XXHASH64
#slave
slave-parallel-type = LOGICAL_CLOCK
slave-parallel-workers = 32
接着用命令mysqlslap来执行上述SQL语句:INSERT INTO test.t1 VALUES (NULL,UUID(),3),线程设置为1,即单线程执行插入操作:
mysqlslap --query=insert_one.sql --number-of-queries=10 -c 1
虽然是单线程运行,但在二进制日志中可以看到大量相同last_committed值得记录,因此记录在从机都是可以并行执行。其实若继续插入,整个二进制日志中显示的last_committed可能都是1,因为测试的插入操作没有行冲突:
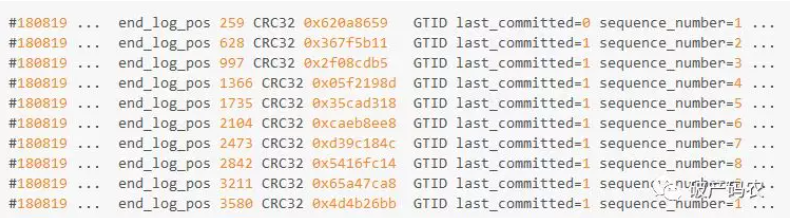
但若是基于Commit_Order的并行复制,由于是单线程中运行,在二进制日志中看到每个事物的last_committed值都不同,回访时依然只能是单线程回放:

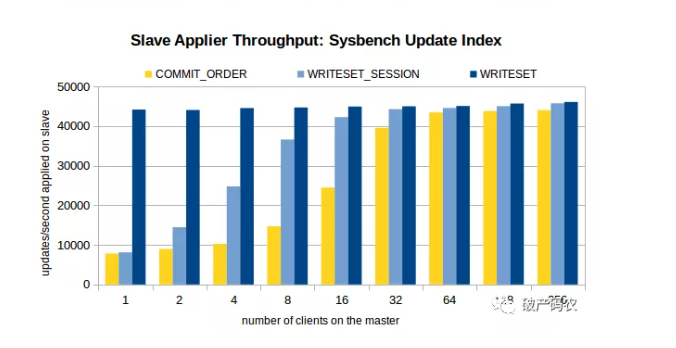
根据上述单线程的测试对比,WriteSet的性能比Commit_Order要快5~6倍,效果非常明显。如果是有延迟要追的,WriteSet毫无疑问是胜者。Commit_Order的瓶颈依然是需要主有足够的并发度,实际生产上确很难达到,除非是业务高峰期。MySQL官方测试(来源:https://mysqlhighavailability.com/improving-the-parallel-applier-with-writeset-based-dependency-tracking/)结果如下,当然看看即可,最主要还是自己生产上的实际效果,不过姜老师坚信这次的效果会远好于Commit_Order。

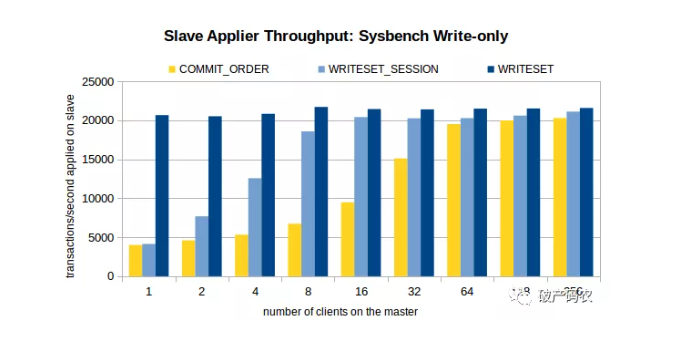
对于源码看兴趣的同学推荐官方的WorkLog,写的超详细。WL#9556: Writeset-based MTS dependency tracking on master
若想快速过下源码,推荐几个关键函数调用:
binlog_log_row
-> add_pke
-> generate_hash_pke
-> Rpl_transaction_write_set_ctx::add_write_set
binlog_cache_data::flush
-> MYSQL_BIN_LOG::write_gtid
-> Writeset_trx_dependency_tracker::get_dependency
最后,留几个思考题给同学们,答出者请务必直接联系姜老师,我们需要有梦想,能背锅的实力派加盟:
-
若WriteSet哈希表满了,MySQL会如何处理?这时last_committed的处理逻辑是怎样?
-
为什么WRITESET中还要记录非主键的唯一索引?举例说明这种场景
-
在哪种场景下,WriteSet复制依然无法很好的解决延迟问题?怎样优化呢?
-
除了WriteSet并行复制,还有一种WriteSet_Session的并行复制机制,请问其和WriteSet的区别,以及具体的实现?