一.分库分表原因
前文介绍MySQL主从模式,将读写分离以提高性能。
主从模式对于写少读多的场景确实非常大的优势,但是总会写操作达到瓶颈的时候,导致性能提不上去。
总的来说就是数据库出现性能瓶颈,对外表现有几个方面:
- 大量请求阻塞:
在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。
- SQL 操作变慢:
如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。
- 存储出现问题:
业务量剧增,单库数据量越来越大,给存储造成巨大压力。
如果系统处于高速发展阶段,拿商城系统来说,一天下单量可能几十万,那数据库中的订单表增长就特别快,增长到一定阶段数据库查询效率就会出现明显下降。
这时候可以在设计上进行解决:
- 采用分库分表的形式,对于业务数据比较大的数据库可以采用分表,使得数据表的存储的数据量达到一个合理的状态。
- 也可以采用分库,按照业务进行划分,这样对于单点的写,就会分成多点的写,性能方面也就会大大提高。
分库分表方案更多的是对关系型数据库数据存储和访问机制的一种补充,而不是颠覆。
二.分库分表拆分思路
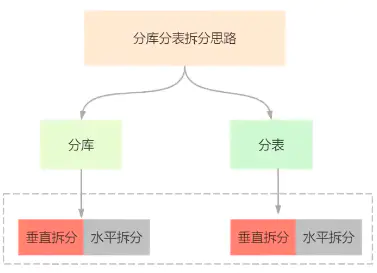
1.什么时候进行分库
MySQL 的高可用架构大多都是一主多从,所有写入操作都发生在 Master 上,随着业务的增长,数据量的增加,很多接口响应时间变得很长,经常出现 Timeout,而且通过升级 MySQL 实例配置已经无法解决问题了,这时候就要分库。
2.什么时候进行分表
分表的应用场景是单表数据量增长速度过快,影响了业务接口的响应时间,但是 MySQL 实例的负载并不高,这时候只需要分表,不需要分库(拆分实例)。
三.垂直拆分
垂直分库
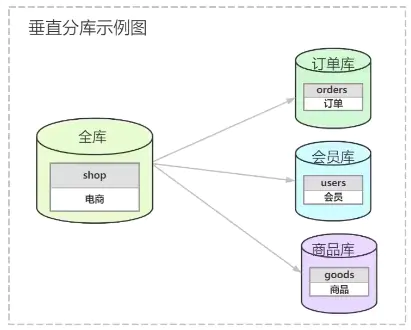
垂直分库是按业务分库,例如一个电商系统shop库按业务分有订单表,会员表,商品表,按业务拆分后,响应的shop库被拆分到三个RDS实例中,数据库写入能力提升,服务的接口响应时间变短,提供稳定性。
垂直分表
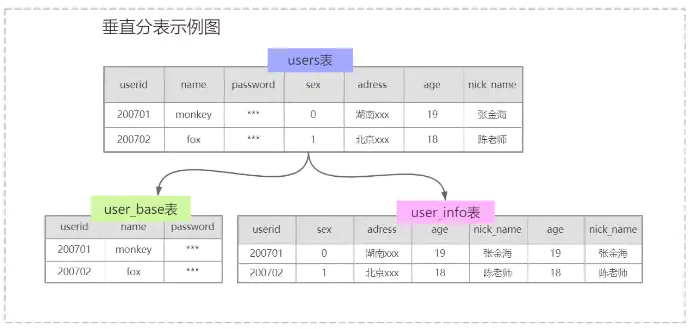
例如登录系统只需要userid,username和password,如果不分表,则每次登录都需要把整张user表加载进内存进行判断,sex,address,age和nick_name这些无用到的字段也会占内存。
垂直拆分特点
基于表或字段划分,表结构不同
垂直拆分优点
- 拆分后业务清晰,方便针对业务进行优化(专库专用按业务拆分);
- 数据维护简单,按业务不同将业务放到不同机器上。
垂直拆分缺点
跨库关联查询
在单库未拆分表之前,我们可以很方便使用 join 操作关联多张表查询数据,但是经过分库分表后两张表可能都不在一个数据库中,如何使用 join 呢?
有几种方案可以解决:
- 字段冗余:把需要关联的字段放入主表中,避免 join 操作;
- 数据抽象:通过ETL等将数据汇合聚集,生成新的表;
- 全局表:比如一些基础表可以在每个数据库中都放一份;
- 应用层组装:将基础数据查出来,通过应用程序计算组装;
四.水平拆分
业务量比较大的时候,即使做了垂直拆分,依然会存在以下问题:
- 如果单表的数据量大,读写压力依然很大;
- 受某种业务来决定,或者被限制。 也就是说一个业务往往会影响到数据库的瓶颈(性能问题)。例如电商系统订单库的读写会远远大于其他功能;
水平分库
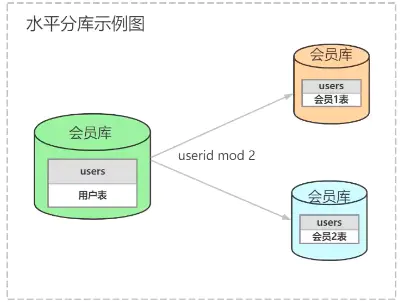
根据一定的逻辑,例如将userid取模,将数据放到不同的库上。
举个例子,交易数据库的订单表 orders 有2亿多数据,RDS 实例遇到了写入瓶颈,普通的 insert 都需要50ms,时常也会收到 CPU 使用率告警,这时就要考虑分库了。
根据业务量增长趋势,计划扩容一台同配置的RDS实例,将订单表 orders 拆分20个子表,每个 RDS 实例10个。
这样解决了订单表 orders 太大的问题,查询的时候要先通过分区键 user_id 定位是哪个 RDS 实例,再定位到具体的子表,然后做 DML操作,
问题是代码改造的工作量大,而且服务调用链路变长了,对系统的稳定性有一定的影响。
其实已经有些数据库中间件实现了分库分表的功能,例如常见的 mycat,阿里云的 DRDS 等。
水平分表
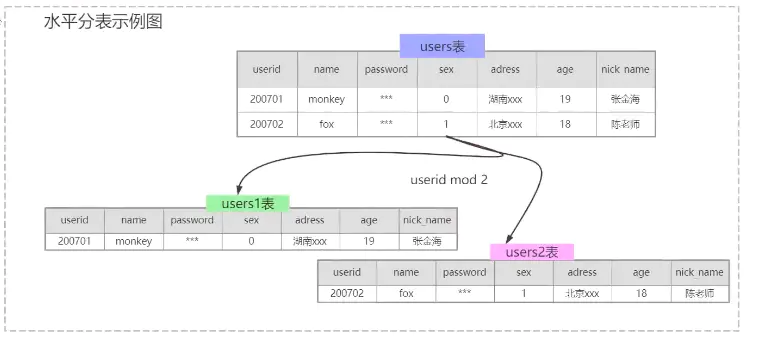
根据一定的逻辑,例如将userid取模,将数据放到不同的表上。
水平拆分的方式也很多,除了上面说的按照 id 拆表,还可以按照时间维度取拆分,比如订单表,可以按每日、每月等进行拆分。
- 每日表:只存储当天的数据。
- 每月表:可以起一个定时任务将前一天的数据全部迁移到当月表。
- 历史表:同样可以用定时任务把时间超过 30 天的数据迁移到 history表。
水平拆分的特点
基于数据划分,表结构相同,数据不同。
水平拆分优点
- 单库(表)的数据保持在一定的量(减少),提高了系统的稳定性和负载能力;
- 切分表的结构相同,程序改造较少。
水平拆分缺点
- 数据扩容有难度,维护量大
例如上面会员库一分为二,根据userid % 2将数据分库或分表存储存储,但随着业务量快速提升,两个库已经不够用,需要分成更多,例如10个,那么分库分表逻辑也会改成 userid % 10,原有的数据在新的逻辑后需要进行数据迁移。 - 拆分规则很难抽象出来
- 分布式事务的一致性问题,部分业务无法关联join,只能通过程序接口调用。
汇总分库分表带来的问题
- 跨库关联查询,上面提到解决办法;
- 分布式事务,单数据库可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。
常用解决方案有:基于可靠消息(MQ)的解决方案、两阶段事务提交、柔性事务等。 - 排序、分页、函数计算问题
在使用 SQL 时 order by, limit 等关键字需要特殊处理,一般来说采用分片的思路:
先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终得到结果。 - 分布式 ID
如果使用 Mysql 数据库在单库单表可以使用 id 自增作为主键,分库分表了之后就不行了,会出现id 重复。
常用的分布式 ID 解决方案有:
UUID
基于数据库自增单独维护一张 ID表
号段模式
Redis 缓存
雪花算法(Snowflake)
百度uid-generator
美团Leaf
滴滴Tinyid - 多数据源
分库分表之后可能会面临从多个数据库或多个子表中获取数据,一般的解决思路有:客户端适配和代理层适配。
业界常用的中间件有:
shardingsphere(前身 sharding-jdbc)
Mycat
分库分表现成方案
- 代码改造,入数据库中间件mycat,sharding-sphere;
- 分布式数据库,实际业务中使用比较多的有 PingCAP TiDB,阿里云 DRDS,可以优先使用分布式数据库方案,虽然成本会有所增加,但对应用程序没有侵入性,同时也可以比较好的支撑业务增长和系统快速迭代。