逻辑回归(Logistic Regression)
什么是逻辑回归:
逻辑回归(Logistic Regression)是一种基于概率的模式识别算法,虽然名字中带"回归",但实际上是一种分类方法,在实际应用中,逻辑回归可以说是应用最广泛的机器学习算法之一
回归问题怎么解决分类问题?
将样本的特征和样本发生的概率联系起来,而概率是一个数.换句话说,我预测的是这个样本发生的概率是多少,所以可以管它叫做回归问题
在许多机器学习算法中,我们都是在追求这样的一个函数
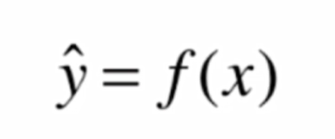
例如我们希望预测一个学生的成绩y,将现有数据x输入模型 f(x) 中,便可以得到一个预测成绩y
但是在逻辑回归中,我们得到的y的值本质是一个概率值p
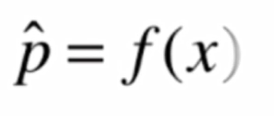
在得到概率值p之后根据概率值来进行分类
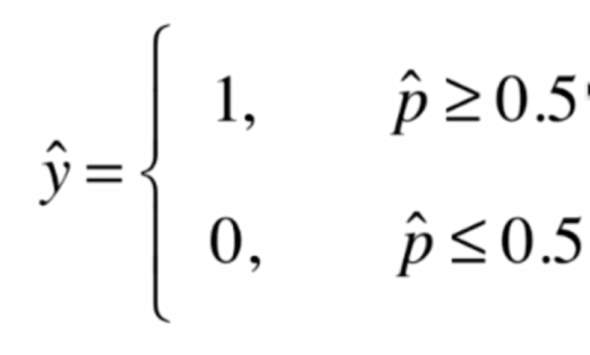
当然了这个1和0在不同情况下可能有不同的含义,比如0可能代表恶性肿瘤患者,1代表良性肿瘤患者
逻辑回归既可以看做是回归算法,也可以看做是分类算法,通常作为分类算法用,只可以解决二分类问题,不过我们可以使用一些其他的技巧(OvO,OvR),使其支持解决多分类问题
下面我们来看一下逻辑回归使用什么样的方法来得到一个事件发生的概率的值
在线性回归中,我们使用
![]()
来计算,要注意,因为Θ0的存在,所以x用小的Xb来表示,就是每来一个样本,前面还还要再加一个1,这个1和Θ0相乘得到的是截距,但是不管怎样,这种情况下,y的值域是(-infinity, +infinity)
而对于概率来讲,它有一个限定,其值域为[0,1]
所以我们如果直接使用线性回归的方式,去看能不能找到一组Θ来与特征x相乘之后得到的y值就来表达这个事件发生的概率呢?
其实单单从应用的角度来说,可以这么做,但是这么做不够好,就是因为概率有值域的限制,而使用线性回归得到的结果则没有这个限制
为此,我们有一个很简单的解决方案:
我们将线性回归得到的结果再作为一个特征值传入一个新的函数,经过转换,将其转换成一个值域在[0,1]之间的值
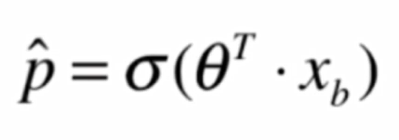
Sigmoid函数:

将函数绘制出来:
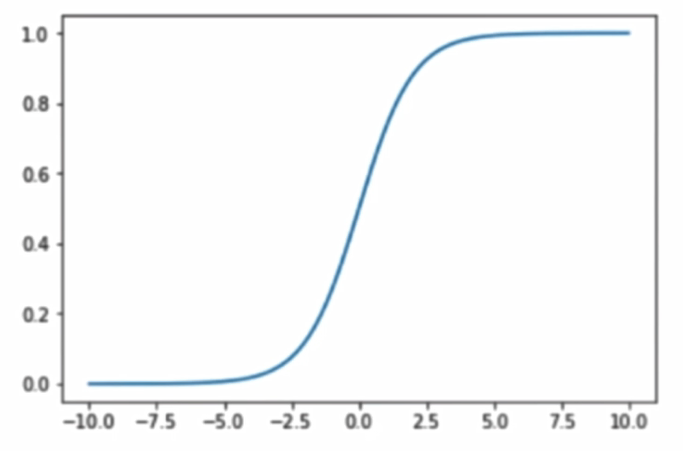
其最左端趋近于0,最右端趋近于1,其值域在(0,1),这正是我们所需要的性质
当传入的参数 t > 0 时, p > 0.5, t < 0 时, p < 0.5,分界点是 t = 0
使用Sigmoid函数后:


现在的问题就是,给定了一组样本数据集X和它对应的分类结果y,我们如何找到参数Θ,使得用这样的方式可以最大程度的获得这个样本数据集X对应的分类输出y
这就是我们在训练的过程中要做的主要任务,也就是拟合我们的训练样本,而拟合过程,就会涉及到逻辑回归的损失函数
逻辑回归的损失函数:

我们定义了一个这样的损失函数:
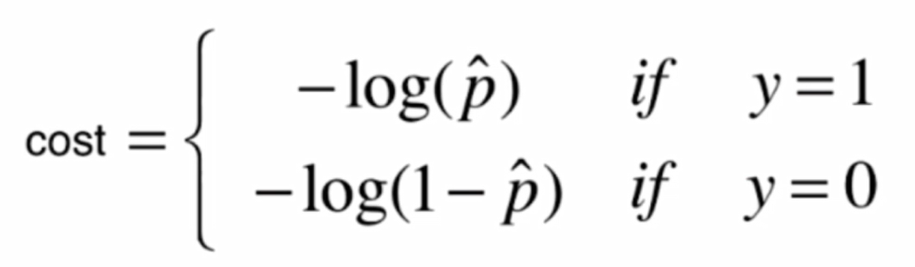
画出图像:
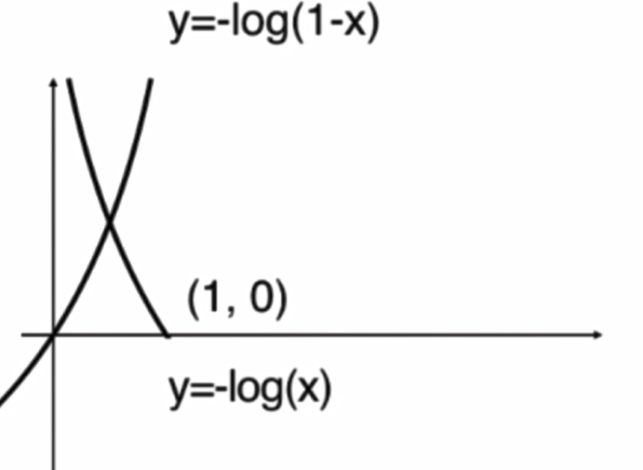
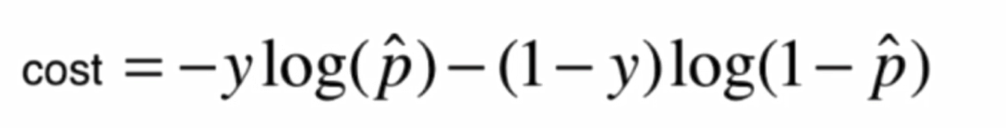
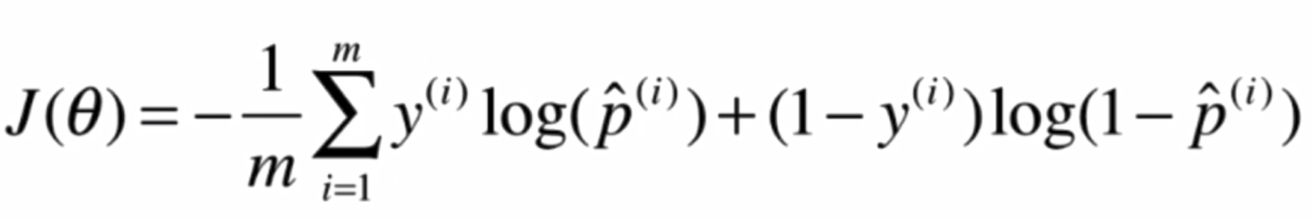
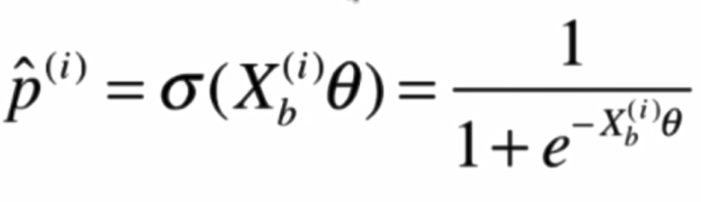
将两个式子整合:
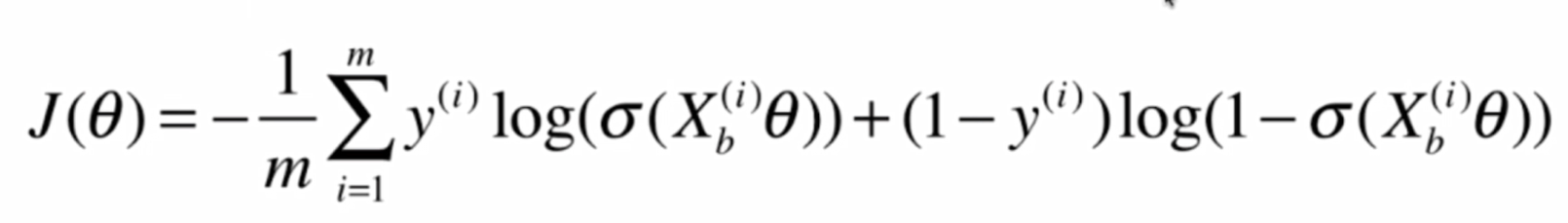
下面我们要做的事情,就是找到一组Θ,使得J(Θ)最小
对于这个式子,我们很难像线性回归那样推得一个正规方程解,实际上这个式子是没有数学解的,也就是无法把X和直接套进公式获得Θ
不过,我们可以使用梯度下降法求得它的解,而且,这个损失函数是一个凸函数,不用担心局部最优解的,只存在全局最优解
现在,我们的任务就是求出J(Θ)的梯度,使用梯度下降法来进行计算
首先,求J(Θ)的梯度的公式:

首先,我们对Sigmoid函数求导:
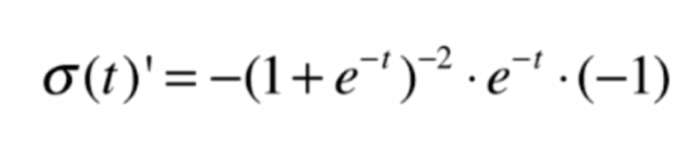
![]()
得到其导数,再对logσ(t)求导,求导步骤:
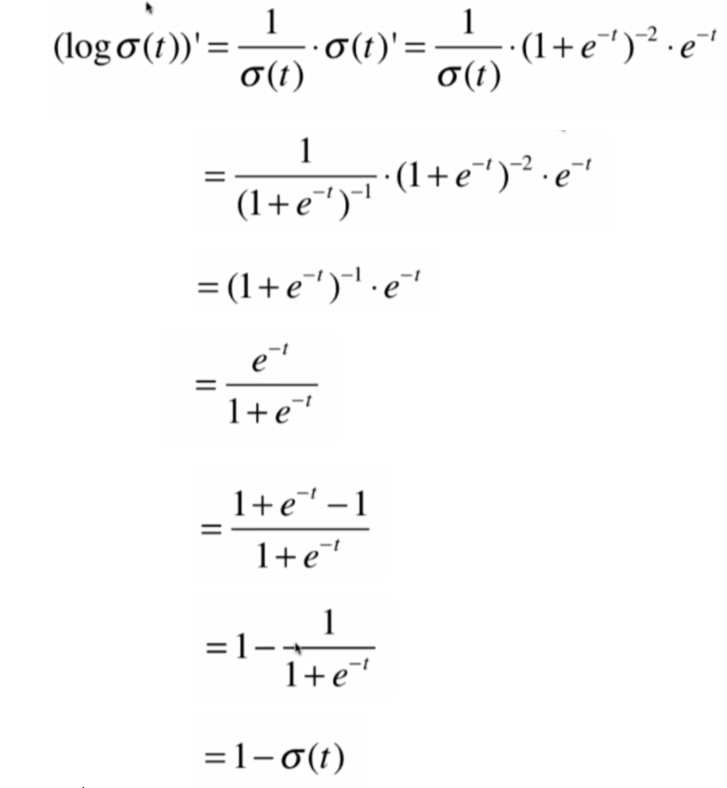
由此可知, 前半部分的导数:
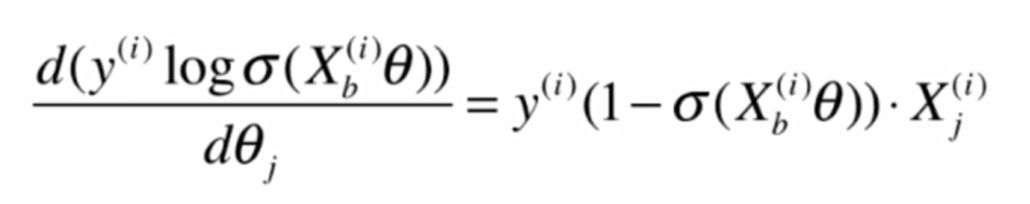
其中y(i)是常数
再求后半部分:
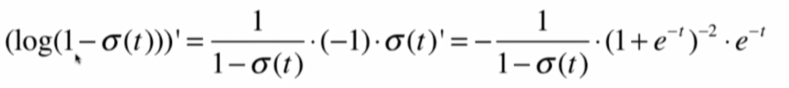
这其中
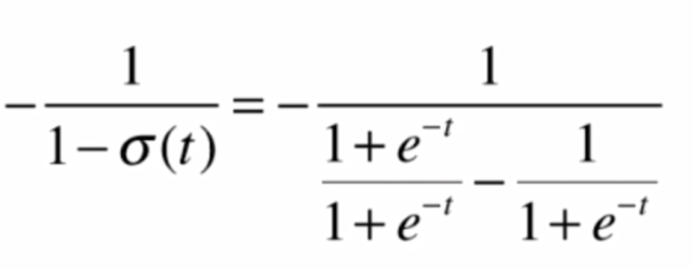
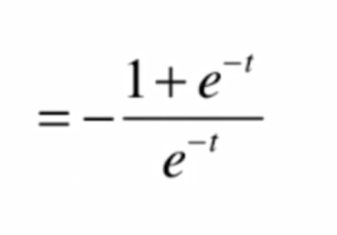
将结果代入,化简得:
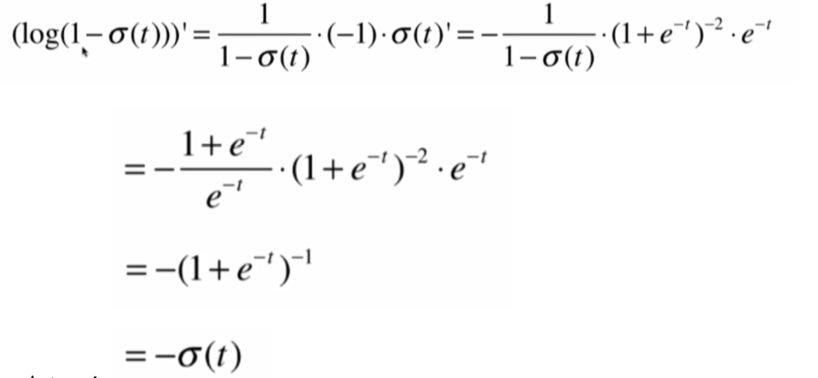
就得到后半部分的求导结果:
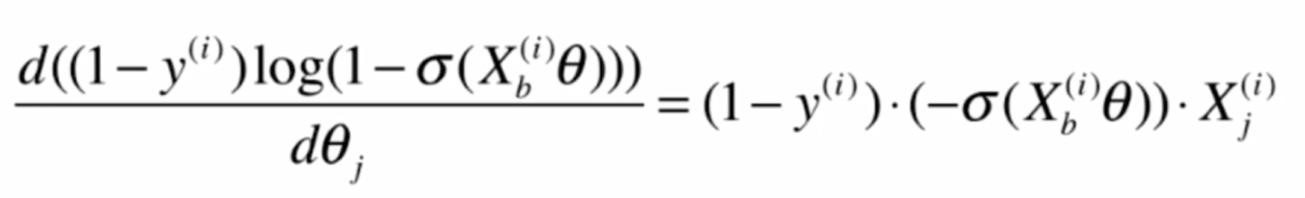
将前后部分相加:
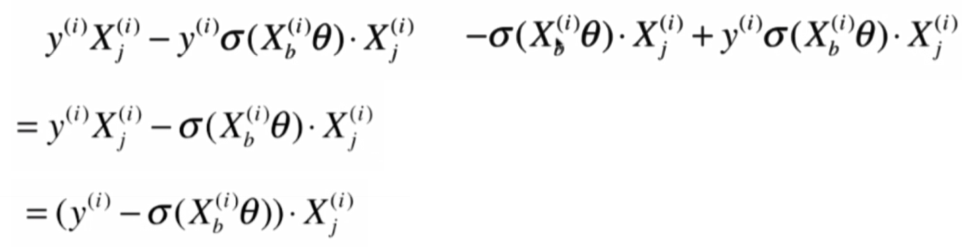
即:
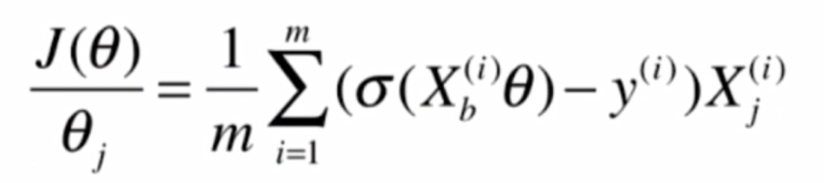
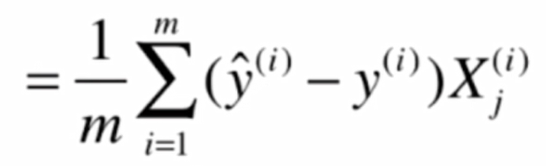
就可以得到:
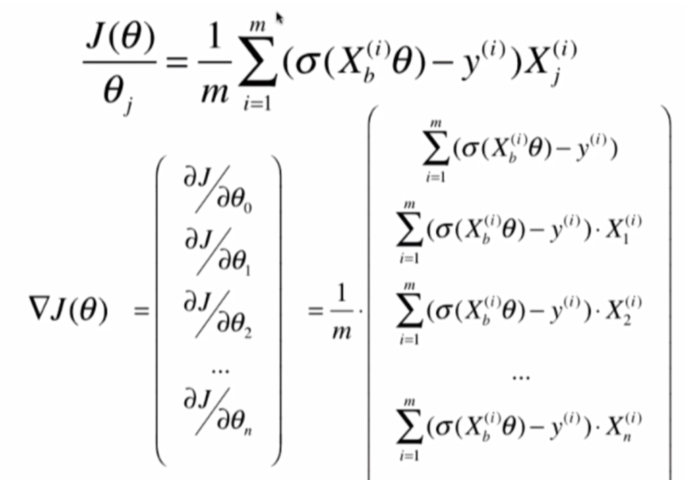
此时我们回忆一下线性回归的向量化过程

参考这个,可以得到:

这就是我们要求的梯度,再使用梯度下降法,就可以求得结果
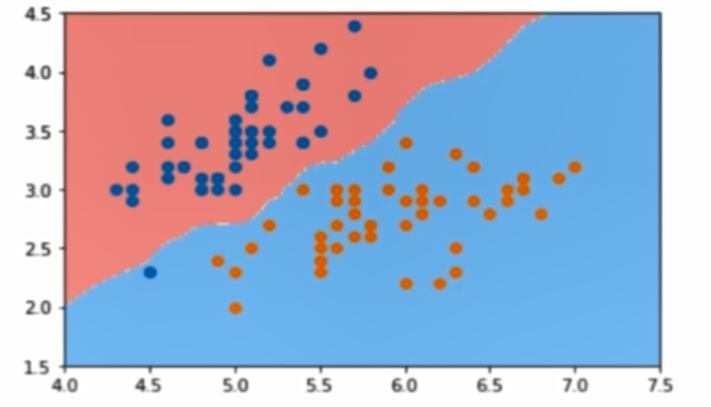
决策边界:
这里引入一个概念,叫做判定边界,可以理解为是用以对不同类别的数据分割的边界,边界的两旁应该是不同类别的数据
从二维直角坐标系中,举几个例子,大概是如下这个样子:
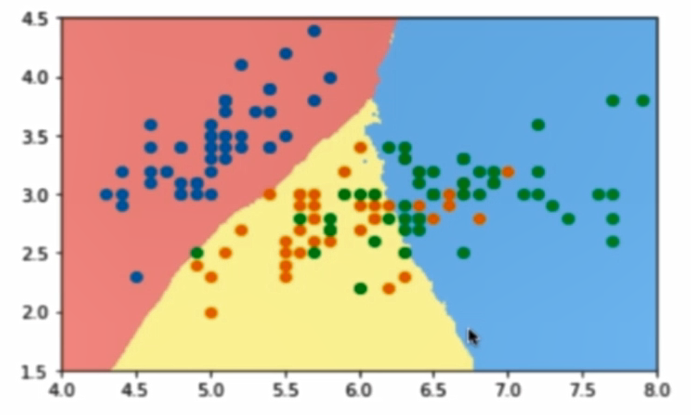
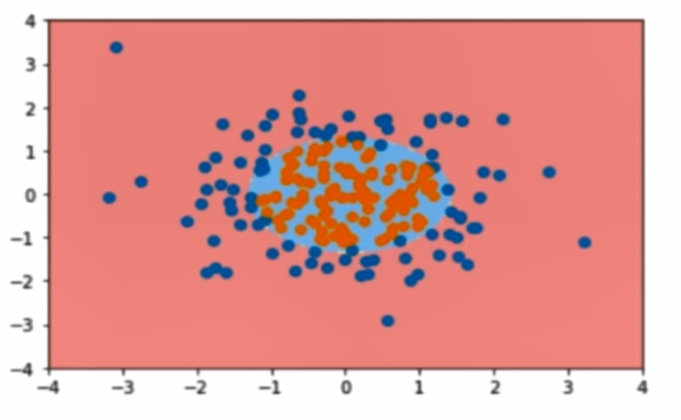
使用OvR和OvO方法解决多分类:
原本的逻辑回归只能解决双分类问题,但我们可以通过一些方法,让它支持多分类问题,比如OvR和OvO方法
OvR:
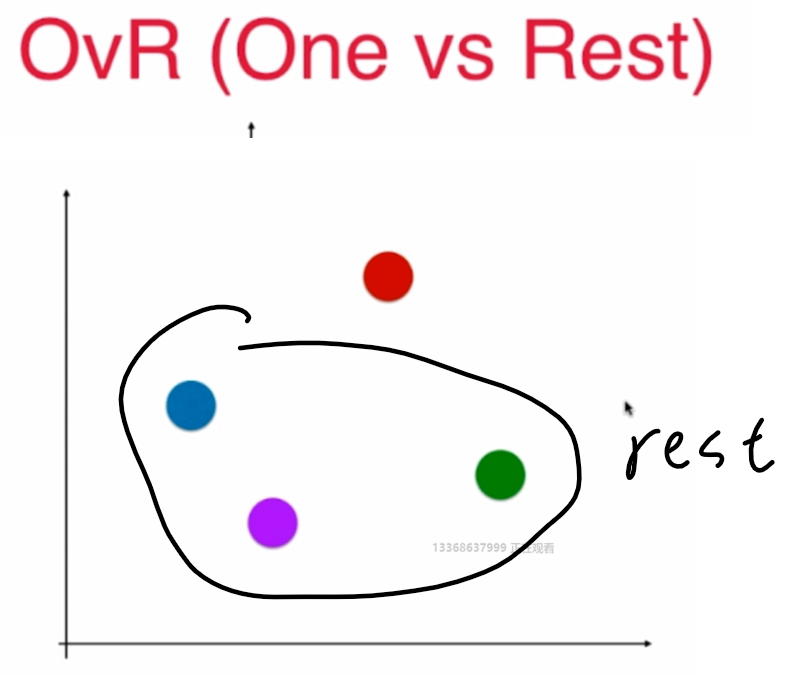
n 种类型的样本进行分类时,分别取一种样本作为一类,将剩余的所有类型的样本看做另一类,这样就形成了 n 个二分类问题,使用逻辑回归算法对 n 个数据集训练出 n 个模型,将待预测的样本传入这 n 个模型中,所得概率最高的那个模型对应的样本类型即认为是该预测样本的类型

n个类别就进行n次分类,选择分类得分最高的
OvO:

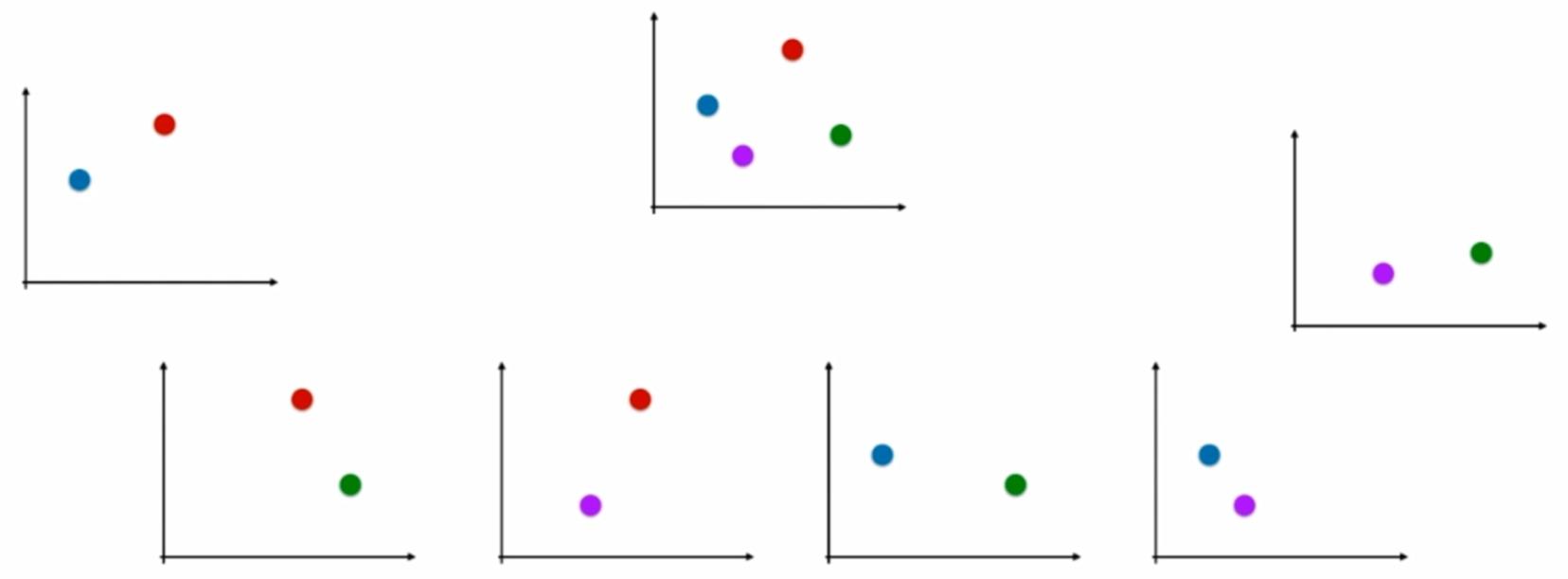
n 类样本中,每次挑出 2 种类型,两两结合,一共有 Cn2 种二分类情况,使用 Cn2 种模型预测样本类型,有 Cn2 个预测结果,种类最多的那种样本类型,就认为是该样本最终的预测类型
这两种方法中,OvO的分类结果更加精确,因为每一次二分类时都用真实的类型进行比较,没有混淆其它的类别,但时间复杂度较高
代码实现 :
1 import numpy as np 2 from .metrics import accuracy_score 3 4 5 class LogisticRegression: 6 7 def __init__(self): 8 """初始化Linear Regression模型""" 9 self.coef_ = None 10 self.intercept_ = None 11 self._theta = None 12 13 def _sigmoid(self, t): 14 return 1. / (1. + np.exp(-t)) 15 16 def fit(self, X_train, y_train, eta=0.01, n_iters=1e4): 17 """根据训练数据集X_train, y_train, 使用梯度下降法训练Logistic Regression模型""" 18 assert X_train.shape[0] == y_train.shape[0], 19 "the size of X_train must be equal to the size of y_train" 20 21 def J(theta, X_b, y): 22 y_hat = self._sigmoid(X_b.dot(theta)) 23 try: 24 return - np.sum(y*np.log(y_hat) + (1-y)*np.log(1-y_hat)) / len(y) 25 except: 26 return float('inf') 27 28 def dJ(theta, X_b, y): 29 return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) / len(X_b) 30 31 def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8): 32 33 theta = initial_theta 34 cur_iter = 0 35 36 while cur_iter < n_iters: 37 gradient = dJ(theta, X_b, y) 38 last_theta = theta 39 theta = theta - eta * gradient 40 if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon): 41 break 42 43 cur_iter += 1 44 45 return theta 46 47 X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) 48 initial_theta = np.zeros(X_b.shape[1]) 49 self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters) 50 51 self.intercept_ = self._theta[0] 52 self.coef_ = self._theta[1:] 53 54 return self 55 56 57 58 def predict_proba(self, X_predict): 59 """给定待预测数据集X_predict,返回表示X_predict的结果概率向量""" 60 assert self.intercept_ is not None and self.coef_ is not None, 61 "must fit before predict!" 62 assert X_predict.shape[1] == len(self.coef_), 63 "the feature number of X_predict must be equal to X_train" 64 65 X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict]) 66 return self._sigmoid(X_b.dot(self._theta)) 67 68 def predict(self, X_predict): 69 """给定待预测数据集X_predict,返回表示X_predict的结果向量""" 70 assert self.intercept_ is not None and self.coef_ is not None, 71 "must fit before predict!" 72 assert X_predict.shape[1] == len(self.coef_), 73 "the feature number of X_predict must be equal to X_train" 74 75 proba = self.predict_proba(X_predict) 76 return np.array(proba >= 0.5, dtype='int') 77 78 def score(self, X_test, y_test): 79 """根据测试数据集 X_test 和 y_test 确定当前模型的准确度""" 80 81 y_predict = self.predict(X_test) 82 return accuracy_score(y_test, y_predict) 83 84 def __repr__(self): 85 return "LogisticRegression()"