验证码截图如下:

# coding:utf-8
from PIL import Image,ImageEnhance
import pytesseract
#上面都是导包,只需要下面这一行就能实现图片文字识别
im = Image.open('merge_source.jpg')
#下面为增强部分
enh_con = ImageEnhance.Contrast(im)
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
#image_contrasted.show()
#增强亮度
enh_bri = ImageEnhance.Brightness(image_contrasted)
brightness = 1.5
image_brightened = enh_bri.enhance(brightness)
#image_brightened.show()
#增强对比度
enh_col = ImageEnhance.Color(image_brightened)
color = 1.5
image_colored = enh_col.enhance(color)
#image_colored.show()
#增强锐度
enh_sha = ImageEnhance.Sharpness(image_colored)
sharpness = 3.0
image_sharped = enh_sha.enhance(sharpness)
#image_sharped.show()
#灰度处理部分
im2=image_sharped.convert("L")
im2.show()
text=pytesseract.image_to_string(im2,lang='chi_sim').strip() #使用image_to_string识别验证码
print(text)
打印结果:
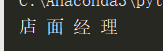
知识扩展:
1.需要安装的库Pillow 库(PIL)和pytesseract ,安装方式直接通过pip安装
2.需要安装windows版本的TesseractOCRiOS(光学字符识别)程序,下载地址:http://xza.198424.com/tesserract.zip
特别注意,ocr安装完成后需要配置环境变量
① 在安装位置时,需要在语言选择
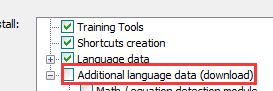
展开,找到简体中文进行勾选,如果有其他字体需要也可以勾选安装,语言会安装到安装目录下的tessdata文件夹中
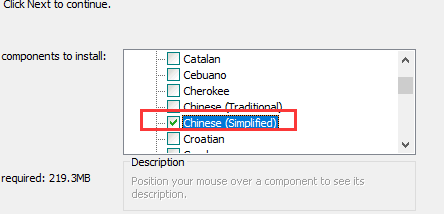
① tesseract的环境变量 C:Program Files (x86)Tesseract-OCR ,根据实际安装位置填写
②C:Program Files (x86)Tesseract-OCR essdata
#打码的路上还很长