这篇论文是2017ACL的短文(short paper),做的是时间关系抽取(temporal relation extraction)。作者四个Julien Tourille,Olivier Ferret,Xavier Tannier和Aurélie Névéol,没看出哪个是通讯作者。。
这是我第一次接触时间关系抽取,和平时我做的关系抽取不一样。但是也是鉴别两个实体之间是否有什么关系。
在引言和相关工作部分,作者对医疗事件(EVENT)和时间表达(TIMEX3)之间的narrative container identification 提出了一种网络结构,实验语料为THYME,这是一个英语的临床医学文本。SemEval已经连续两年提出了从临床叙事性文本进行时间关系抽取。这个任务有两步:
- 抽取实体EVENT和TIMEX3
- 第二步:抽取关系。有两个关系,一个是叙事包含关系,另外一个是文档创造的时间关系
作者是在已知实体的情况下识别实体之间存在的关系,并且只识别叙事包含关系。
接着作者介绍了一下语料THYME,这是用英语写的临床文本集合,来自癌症部门,在Clinical TempEval活动中被发布。这个语料包含被医学事件、时间表达式和叙事包含关系标注的文档。
EVENT的定义为病人临床时间轴上任何有兴趣的点,比如:医疗过程、疾病、诊断。每个事件还有五个属性:Contextual Modality, Degree, Polarity, Type and DocTimeRel。时间表达式有一个Class属性。
叙事包含关系有跨句子的情况出现,论文将这两种情况分别称之为intra和inter sentence relations。
对语料的预处理使用的是cTAKES,这是自然语言处理系统,用于从临床电子病历自由文本中抽取信息。对这个工具没什么了解,等以后用到的时候再看看。
在任务描述时,作者说可以将这个任务看作是三分类任务,这三类分别是:
- 第一个实体包含第二个实体
- 第二个实体包含第一个实体
- 没有关系
作者再次强调将跨句子和句子内的关系当做两个不同的分类任务,采用不同的分类器(文章只介绍了一个模型,所以照此推断的话,应该是将两种关系分开训练)。并且对于跨句子的关系,不考虑整个文档中的实体对,否则训练集将会很大,而真正存在关系的实例很少。于是实验将跨句子的关系限制在三句。
接下来是对模型的介绍了,结构很简单,就是一个双向的LSTM,如图所示:
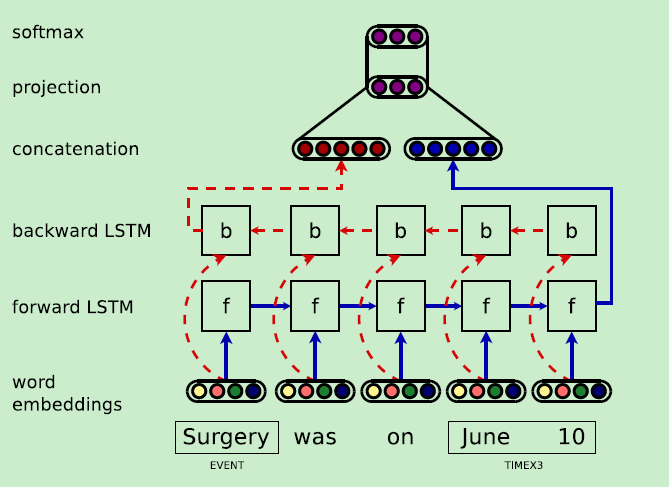
输入的词向量是由几部分组成的,分别是:
- 基于字符的向量
- 词向量
- 每个标准属性一个词向量
- 每个cTAKES属性一个词向量
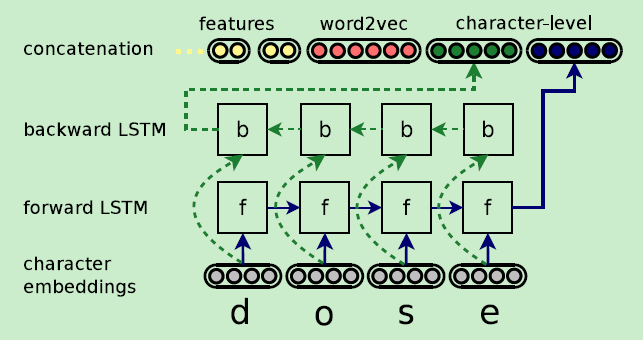
前面也介绍过实体都有属性,cTAKES处理过的文本的实体也有属性,将这些属性词向量随机初始化就行;词向量使用word2vec训练得到;字符词向量使用BiLSTM,如图所示:
具体参数的设置可以看看论文。
然后就是实验部分,只是在那个语料上做实验,具体看看论文的实验结果表就行。
最后的部分是结论和展望,我就不说了。有兴趣的同学可以自己读读论文。
写在最后:论文中可能有读错的地方,如果哪位热心人士看到了,请不吝赐教。