主从复制介绍
为了避免单点Redis服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服 务器上,连接在一起,并保证数据是同步的。即使有其中一台服务器宕机,其他服务器依然可以继续 提供服务,实现Redis的高可用,同时实现数据冗余备份。
多台服务器连接方案

核心工作: master的数据复制到slave中
主从复制即将master中的数据即时、有效的复制到slave中
特征:一个master可以拥有多个slave,一个slave只对应一个master
职责:
- master:
- 写数据
- 执行写操作时,将出现变化的数据自动同步到slave
- 读数据(可忽略)
- slave:
- 读数据
- 写数据(禁止)
主从复制的作用
- 读写分离:master写、slave读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数 量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
- 故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
主从复制工作流程
主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段
阶段一:建立连接阶段
建立slave到master的连接,使master能够识别slave,并保存slave端口号
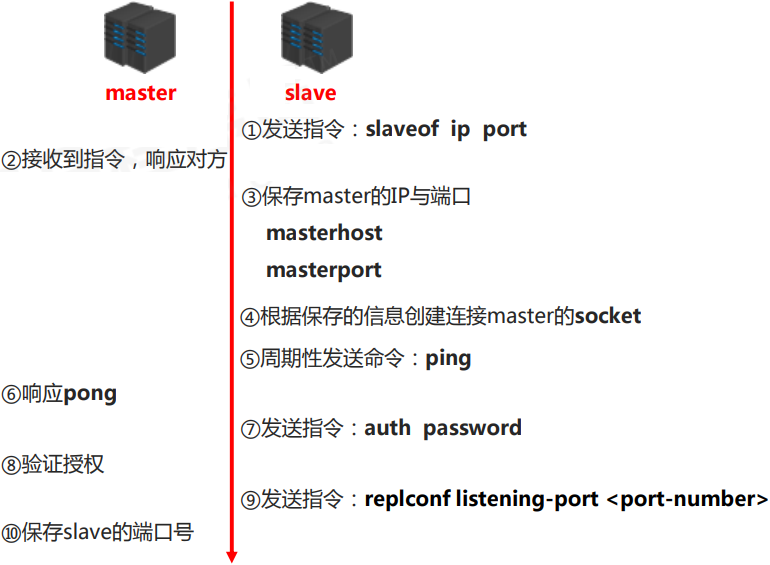
slave: 保存master的地址与端口
master: 保存slave的端口
之间创建了连接的socket
主从连接(slave连接master)
方式一:客户端发送命令
slaveof <masterip> <masterport>
方式二:启动服务器参数
redis-server -slaveof <masterip> <masterport>
方式三:服务器配置 redis.conf
slaveof <masterip> <masterport>
主从断开连接
客户端发送命令
slaveof no one
slave断开连接后,不会删除已有数据,只是不再接受master发送的数据
授权访问
master客户端发送命令设置密码
requirepass <password>
master配置文件设置密码
config set requirepass <password>
config get requirepass
slave客户端发送命令设置密码
auth <password>
slave配置文件设置密码
masterauth <password>
slave启动服务器设置密码
redis-server –a <password>
阶段二:数据同步阶段工作流程
在slave初次连接master后,复制master中的所有数据到slave
将slave的数据库状态更新成master当前的数据库状态

slave: 具有master端全部数据,包含RDB过程接收的数据
master: 保存slave当前数据同步的位置
完成数据克隆
数据同步阶段master说明
1. 如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
2. 复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已 经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态。
repl-backlog-size xxmb(默认:1mb)
master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执 行bgsave命令和创建复制缓冲区
数据同步阶段slave说明
1. 为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
slave-serve-stale-data yes|no
2. 多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果 master带宽不足,因此数据同步需要根据业务需求,适量错峰
3. slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是master,也是 slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟 较大,数据一致性变差,应谨慎选择
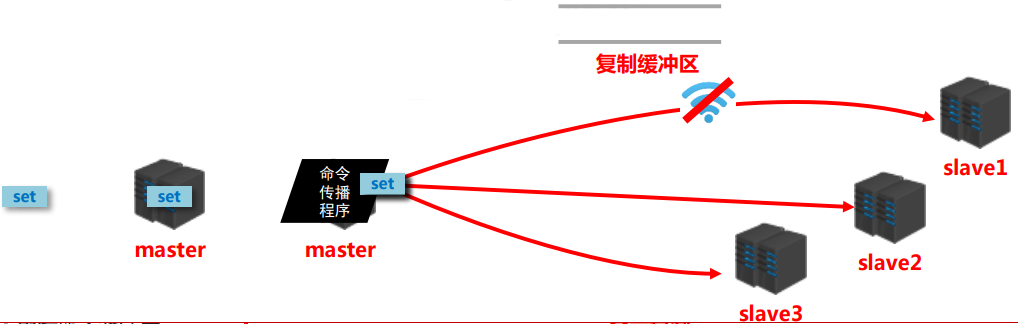
阶段三:命令传播阶段
当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的 状态,同步的动作称为命令传播
master将接收到的数据变更命令发送给slave,slave接收命令后执行命令
命令传播阶段的部分复制
部分复制的三个核心要素
- 服务器的运行 id(run id)
- 主服务器的复制积压缓冲区
- 主从服务器的复制偏移量
服务器运行ID(runid)
概念:服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
组成:运行id由40位字符组成,是一个随机的十六进制字符 例如:fdc9ff13b9bbaab28db42b3d50f852bb5e3fcdce
作用:运行id被用于在服务器间进行传输,识别身份 如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
实现方式:运行id在每台服务器启动时自动生成的,master在首次连接slave时,会将自己的运行ID发 送给slave,slave保存此ID,通过info Server命令,可以查看节点的runid
复制缓冲区
概念:复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命 令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
复制缓冲区内部工作原理
- 组成
- 偏移量
- 字节值
- 工作原理
- 通过offset区分不同的slave当前数据传播的差异
- master记录已发送的信息对应的offset
- slave记录已接收的信息对应的offset

数据同步阶段工作流程

心跳机制
进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
- master心跳:
- 指令:PING
- 周期:由repl-ping-slave-period决定,默认10秒
- 作用:判断slave是否在线
- 查询:INFO replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
- slave心跳任务
- 指令:REPLCONF ACK {offset}
- 周期:1秒
- 作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
- 作用2:判断master是否在线
心跳阶段注意事项
当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步操作
min-slaves-to-write 2 min-slaves-max-lag 8
slave数量少于2个,或者所有slave的延迟都大于等于8秒时,强制关闭master写功能,停止数据同步
slave数量和slave延迟 由slave发送REPLCONF ACK命令做确认

主从复制常见问题
频繁的全量复制(1)
伴随着系统的运行,master的数据量会越来越大,一旦master重启,runid将发生变化,会导致全部slave的 全量复制操作
内部优化调整方案:
1. master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave
2. 在master关闭时执行命令 shutdown save,进行RDB持久化,将runid与offset保存到RDB文件中
-
- repl-id repl-offset
- 通过redis-check-rdb命令可以查看该信息
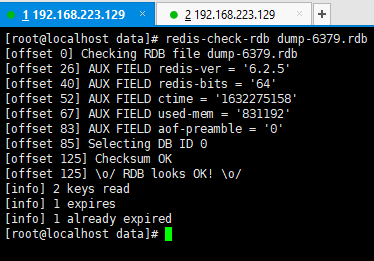
3. master重启后加载RDB文件,恢复数据
重启后,将RDB文件中保存的repl-id与repl-offset加载到内存中
-
- master_repl_id = repl master_repl_offset = repl-offset
- 通过info命令可以查看该信息
作用: 本机保存上次runid,重启后恢复该值,使所有slave认为还是之前的master
搭建主从
master
master配置 redis-6379.conf
port 6379 daemonize no #logfile "log_6379.log" dir ./data save 60 2 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename "dump-6379.rdb" appendonly yes appendfsync always appendfilename "appendonly-6379.aof" bind 127.0.0.1
启动
redis-server redis-config/redis-6379.conf
slave
slave配置redis-6380.conf
port 6380 daemonize no #logfile "log_6380.log" dir ./data slaveof 127.0.0.1 6379
启动
redis-server redis-config/redis-6380.conf
测试
master客户端
[root@localhost ~]# redis-cli -p 6379 127.0.0.1:6379> set name zhangsan OK
slave客户端
[root@localhost ~]# redis-cli -p 6380 127.0.0.1:6380> get name "zhangsan"