Naive Bayes-朴素贝叶斯
Bayes’ theorem(贝叶斯法则)
在概率论和统计学中,Bayes’ theorem(贝叶斯法则)根据事件的先验知识描述事件的概率。贝叶斯法则表达式如下所示
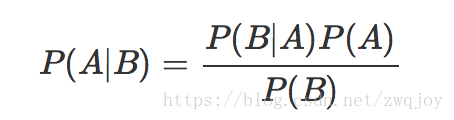
- P(A|B) – 在事件B下事件A发生的条件概率
- P(B|A) – 在事件A下事件B发生的条件概率
- P(A), P(B) – 独立事件A和独立事件B的边缘概率
顺便提一下,上式中的分母P(B)可以根据全概率公式分解为:
Bayesian inferenc(贝叶斯推断)
贝叶斯定理的许多应用之一就是贝叶斯推断,一种特殊的统计推断方法,随着信息增加,贝叶斯定理可以用于更新假设的概率。在决策理论中,贝叶斯推断与主观概率密切相关,通常被称为“Bayesian probability(贝叶斯概率)”。
贝叶斯推断根据 prior probability(先验概率) 和统计模型导出的“likelihood function(似然函数)”的结果,再由贝叶斯定理计算 posterior probability(后验概率):
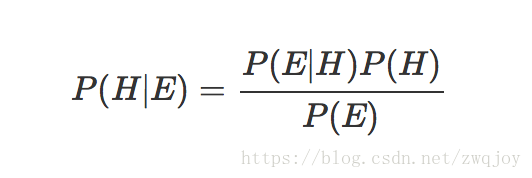
- P(H) – 已知的先验概率
- P(H|E) – 我们想求的后验概率,即在B事件发生后对于事件A概率的评估
- P(E|H) – 在事件H下观测到E的概率
- P(E) – marginal likelihood(边际似然),对于所有的假设都是相同的,因此不参与决定不同假设的相对概率
- P(E|H)/P(E) – likelihood function(可能性函数),这是一个调整因子,通过不断的获取信息,可以使得预估概率更接近真实概率
贝叶斯推断例子
假设我们有两个装满了饼干的碗,第一个碗里有10个巧克力饼干和30个普通饼干,第二个碗里两种饼干都有20个。我们随机挑一个碗,再在碗里随机挑饼干。那么我们挑到的普通饼干来自一号碗的概率有多少?
我们用 H1 代表一号碗,H2 代表二号碗,而且 P(H1) = P(H2) = 0.5。事件 E 代表普通饼干。由上面可以得到 P(E|H1) = 30 / 40 = 0.75,P(E|H2) = 20 / 40 = 0.5。由贝叶斯定理我们得到

- P(E|H1)P(H1), P(E|H2)P(H2) – 分别表示拿到来自一号碗的普通饼干、来自二号碗的普通饼干的概率
- P(E|H1)P(H1) + P(E|H2)P(H2) – 表示拿到普通饼干的概率
在我们拿到饼干前,我们会选到一号碗的概率是先验概率 P(H1),在拿到了饼干后,我们要得到是后验概率 P(H1|E)
特征条件独立假设
这一部分开始朴素贝叶斯的理论推导,从中你会深刻地理解什么是特征条件独立假设。
给定训练数据集(X,Y),其中每个样本x都包括n维特征,即x=(x1,x2,x3,...,xn),类标记集合含有k种类别,即y=(y1,y2,...,yk)。
如果现在来了一个新样本x,我们要怎么判断它的类别?从概率的角度来看,这个问题就是给定x,它属于哪个类别的概率最大。那么问题就转化为求解P(y1|x),P(y2|x),...,P(yk|x)中最大的那个,即求后验概率最大的输出:argmaxykP(yk|x)
那P(yk|x)怎么求解?答案就是贝叶斯定理:
根据全概率公式,可以进一步地分解上式中的分母:
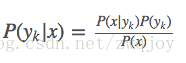

先不管分母,分子中的P(yk)
是先验概率,根据训练集就可以简单地计算出来。
而条件概率P(x|yk)=P(x1,x2,...,xn|yk)
它的参数规模是指数数量级别的,假设第i维特征xi可取值的个数有Si个,类别取值个数为k个,那么参数个数为:k∏ni=1Si这显然不可行。针对这个问题,朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征x1,x2,...,xn互相独立,在这个假设的前提上,条件概率可以转化为:
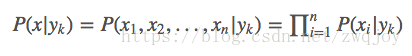
这样,参数规模就降到∑ni=1Sik
以上就是针对条件概率所作出的特征条件独立性假设,至此,先验概率P(yk)
和条件概率P(x|yk)的求解问题就都解决了,那么我们是不是可以求解我们所要的后验概率P(yk|x)了?答案是肯定的。我们继续上面关于P(yk|x)
的推导,将【公式2】代入【公式1】得到:
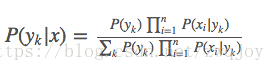
于是朴素贝叶斯分类器可表示为:
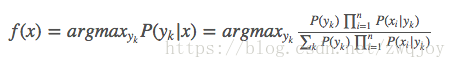
因为对所有的yk,上式中的分母的值都是一样的(为什么?注意到全加符号就容易理解了),所以可以忽略分母部分,朴素贝叶斯分类器最终表示为:

Naive Bayes Classifiers(朴素贝叶斯分类器)
在机器学习中,朴素贝叶斯分类器是一个基于贝叶斯定理的比较简单的概率分类器,其中 naive(朴素)是指的对于模型中各个 feature(特征) 有强独立性的假设,并未将 feature 间的相关性纳入考虑中。
朴素贝叶斯分类器一个比较著名的应用是用于对垃圾邮件分类,通常用文字特征来识别垃圾邮件,是文本分类中比较常用的一种方法。朴素贝叶斯分类通过选择 token(通常是邮件中的单词)来得到垃圾邮件和非垃圾邮件间的关联,再通过贝叶斯定理来计算概率从而对邮件进行分类。
由单个单词分类邮件
假设可疑消息中含有“sex”这个单词,平时大部分收到邮件的人都会知道,这封邮件可能是垃圾邮件。然而分类器并不知道这些,它只能计算出相应的概率。假设在用户收到的邮件中,“sex”出现在在垃圾邮件中的频率是5%,在正常邮件中出现的概率是0.5%。
我们用 S 表示垃圾邮件(spam),H 表示正常邮件(healthy)。两者的先验概率都是50%,即:
我们用 W 表示这个词,那么问题就变成了计算 P(S|W) 的值,根据贝叶斯定理我们可以得到:
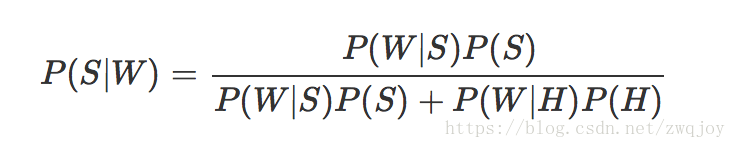
P(W|S)和P(W|H)的含义是,这个词语在垃圾邮件和正常邮件中,分别出现的概率。通过计算可以得到 P(S|W) = 99.0%,说明“sex”的判断能力很强,将50%的先验概率提高到了99%的后验概率。
结合独立概率
大多数贝叶斯垃圾邮件分类器基于这样的假设:邮件中的单词是独立的事件,实际上这种条件一般不被满足,这也是为什么被称作朴素贝叶斯。这是对于应用情景的理想化,在此基础上,我们可以通过贝叶斯定理得到以下公式:
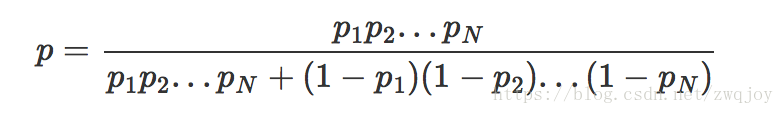
- p 是可疑邮件是垃圾邮件的概率
- pN 当邮件中包含第 Nth 个单词时邮件是垃圾邮件的概率 p(S|WN)
对于输出的概率,我们将它和一个 threshold(阈值)相比较,小于阈值的是正常邮件,否则认为它是垃圾邮件。
scikit-learn 朴素贝叶斯类库概述
朴素贝叶斯是一类比较简单的算法,scikit-learn中朴素贝叶斯类库的使用也比较简单。相对于决策树,KNN之类的算法,朴素贝叶斯需要关注的参数是比较少的,这样也比较容易掌握。在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
这三个类适用的分类场景各不相同:
- 高斯朴素贝叶斯:sklearn.naive_bayes.GaussianNB(priors=None) 用于样本特征的分布大部分是连续值
- 多项式朴素贝叶斯:sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)主要用于离散特征分类,例如文本分类单词统计,以出现的次数作为特征值
- 伯努利朴素贝叶斯:sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True,class_prior=None)类似于多项式朴素贝叶斯,也主要用户离散特征分类,和MultinomialNB的区别是:MultinomialNB以出现的次数为特征值,BernoulliNB为二进制或布尔型特性
1. GaussianNB类使用总结
GaussianNB假设特征的先验概率为正态分布,即如下式:
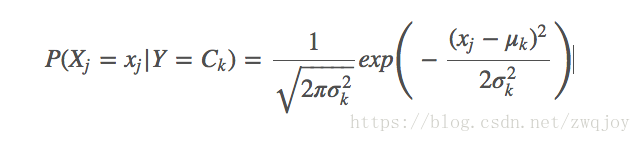
GaussianNB会根据训练集求出μk和σ2k。 μk为在样本类别Ck中,所有Xj的平均值。σ2k为在样本类别Ck中,所有Xj的方差。
GaussianNB类的主要参数仅有一个,即先验概率priors ,对应Y的各个类别的先验概率P(Y=Ck)。这个值默认不给出,如果不给出此时P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。如果给出的话就以priors 为准。
高斯模型假设每一维特征都服从高斯分布(正态分布):

μyk,i表示类别为yk的样本中,第i维特征的均值。
σ2yk,i表示类别为yk的样本中,第i维特征的方差。
在使用GaussianNB的fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。 predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。
当特征是连续变量的时候,运用多项式模型就会导致很多P(xi|yk)=0(不做平滑的情况下),此时即使做平滑,所得到的条件概率也难以描述真实情况。所以处理连续的特征变量,应该采用高斯模型。
下面是一组人类身体特征的统计资料。
| 性别 | 身高(英尺) | 体重(磅) | 脚掌(英寸) |
|---|---|---|---|
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?
根据朴素贝叶斯分类器,计算下面这个式子的值。
P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)
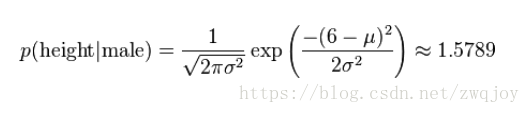
对于脚掌和体重同样可以计算其均值与方差。有了这些数据以后,就可以计算性别的分类了。
P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男) x P(男) = 6.1984 x e-9
P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) x P(女) = 5.3778 x e-4- 1
- 2
- 3
- 4
可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
2. MultinomialNB类使用总结
MultinomialNB假设特征的先验概率为多项式分布,即如下式:

其中,P(Xj=xjl|Y=Ck)是第k个类别的第j维特征的第l个个取值条件概率。mk是训练集中输出为第k类的样本个数。λ
为一个大于0的常数,常常取为1,即拉普拉斯平滑。也可以取其他值。
MultinomialNB参数比GaussianNB多,但是一共也只有仅仅3个。其中,参数alpha即为上面的常数λ,如果你没有特别的需要,用默认的1即可。如果发现拟合的不好,需要调优时,可以选择稍大于1或者稍小于1的数。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。
在使用MultinomialNB的fit方法或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。由于方法和GaussianNB完全一样,这里就不累述了。
多项式模型在计算先验概率P(yk)和条件概率P(xi|yk)时,会做一些平滑处理,具体公式为:

N是总的样本个数,k是总的类别个数,Nyk是类别为yk的样本个数,α是平滑值。

Nyk是类别为yk的样本个数,n是特征的维数,Nyk,xi是类别为yk的样本中,第i维特征的值是xi的样本个数,α是平滑值。
当α=1时,称作Laplace平滑,当0<α<1时,称作Lidstone平滑,α=0时不做平滑。
如果不做平滑,当某一维特征的值xi
没在训练样本中出现过时,会导致P(xi|yk)=0,从而导致后验概率为0。加上平滑就可以克服这个问题。
2.1 举例
有如下训练数据,15个样本,2维特征X1,X2
,2种类别-1,1。给定测试样本x=(2,S)T,判断其类别。

解答如下:
运用多项式模型,令α=1
- 计算先验概率
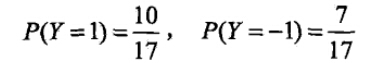
- 计算各种条件概率
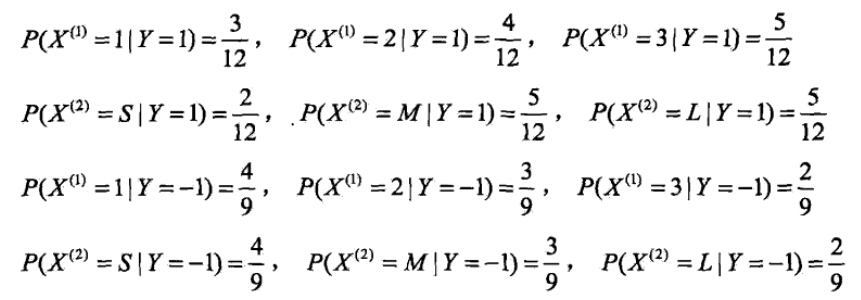
- 对于给定的x=(2,S)T计算:
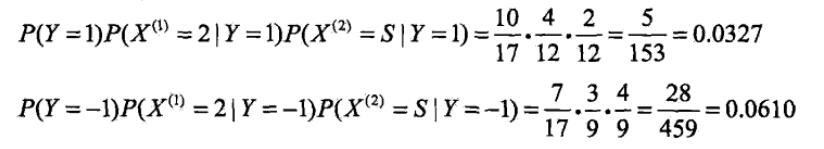
由此可以判定y=-1。
3. BernoulliNB类使用总结
BernoulliNB假设特征的先验概率为二元伯努利分布,即如下式:

此时l只有两种取值。xjl只能取值0或者1。
BernoulliNB一共有4个参数,其中3个参数的名字和意义和MultinomialNB完全相同。唯一增加的一个参数是binarize。这个参数主要是用来帮BernoulliNB处理二项分布的,可以是数值或者不输入。如果不输入,则BernoulliNB认为每个数据特征都已经是二元的。否则的话,小于binarize的会归为一类,大于binarize的会归为另外一类。
在使用BernoulliNB的fit或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。由于方法和GaussianNB完全一样,这里就不累述了。
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
伯努利模型中,条件概率P(xi|yk)的计算方式是:
当特征值xi为1时,P(xi|yk)=P(xi=1|yk);
当特征值xi为0时,P(xi|yk)=1−P(xi=1|yk);
伯努利模型和多项式模型是一致的,BernoulliNB需要比MultinomialNB多定义一个二值化的方法,该方法会接受一个阈值并将输入的特征二值化(1,0)。当然也可以直接采用MultinomialNB,但需要预先将输入的特征二值化。
参考:
- 《统计学习方法》,李航
- 《机器学习》,Tom M.Mitchell
- 维基百科Sex classification
- 朴素贝叶斯的三个常用模型:高斯、多项式、伯努利
- 朴素贝叶斯分类器的应用
- 数学之美番外篇:平凡而又神奇的贝叶斯方法
朴素贝叶斯理论推导与三种常见模型