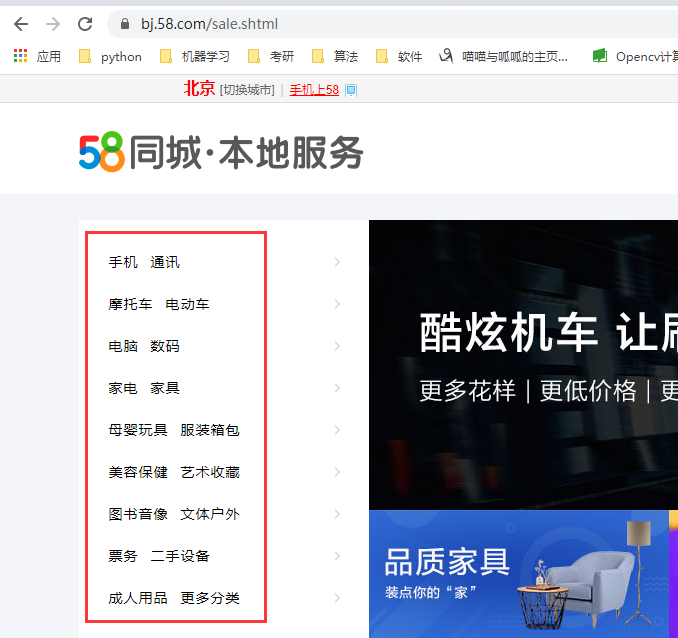
1.获取大页面下各个分类的小URL合集
from bs4 import BeautifulSoup
import requests
start_url = 'http://bj.58.com/sale.shtml'
url_host = 'http://bj.58.com'
def get_index_url(url):
# url = start_url
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
links = soup.select('ul.ym-submnu > li > b > a')
for link in links:
page_url = url_host + link.get('href')
print(page_url)
get_index_url(start_url)
channel_list = '''
http://bj.58.com/shouji/
http://bj.58.com/shoujihao/
http://bj.58.com/tongxunyw/
http://bj.58.com/diannao/
http://bj.58.com/bijiben/
http://bj.58.com/pbdn/
http://bj.58.com/diannaopeijian/
http://bj.58.com/zhoubianshebei/
http://bj.58.com/shuma/
http://bj.58.com/shumaxiangji/
http://bj.58.com/mpsanmpsi/
http://bj.58.com/youxiji/
http://bj.58.com/jiadian/
http://bj.58.com/dianshiji/
http://bj.58.com/ershoukongtiao/
http://bj.58.com/xiyiji/
http://bj.58.com/bingxiang/
http://bj.58.com/binggui/
http://bj.58.com/chuang/
http://bj.58.com/ershoujiaju/
http://bj.58.com/yingyou/
http://bj.58.com/yingeryongpin/
http://bj.58.com/muyingweiyang/
http://bj.58.com/muyingtongchuang/
http://bj.58.com/yunfuyongpin/
http://bj.58.com/fushi/
http://bj.58.com/nanzhuang/
http://bj.58.com/fsxiemao/
http://bj.58.com/xiangbao/
http://bj.58.com/meirong/
http://bj.58.com/yishu/
http://bj.58.com/shufahuihua/
http://bj.58.com/zhubaoshipin/
http://bj.58.com/yuqi/
http://bj.58.com/tushu/
http://bj.58.com/tushubook/
http://bj.58.com/wenti/
http://bj.58.com/yundongfushi/
http://bj.58.com/jianshenqixie/
http://bj.58.com/huju/
http://bj.58.com/qiulei/
http://bj.58.com/yueqi/
http://bj.58.com/bangongshebei/
http://bj.58.com/diannaohaocai/
http://bj.58.com/bangongjiaju/
http://bj.58.com/ershoushebei/
http://bj.58.com/danche/
http://bj.58.com/fzixingche/
http://bj.58.com/diandongche/
http://bj.58.com/sanlunche/
http://bj.58.com/peijianzhuangbei/
http://bj.58.com/tiaozao/
'''
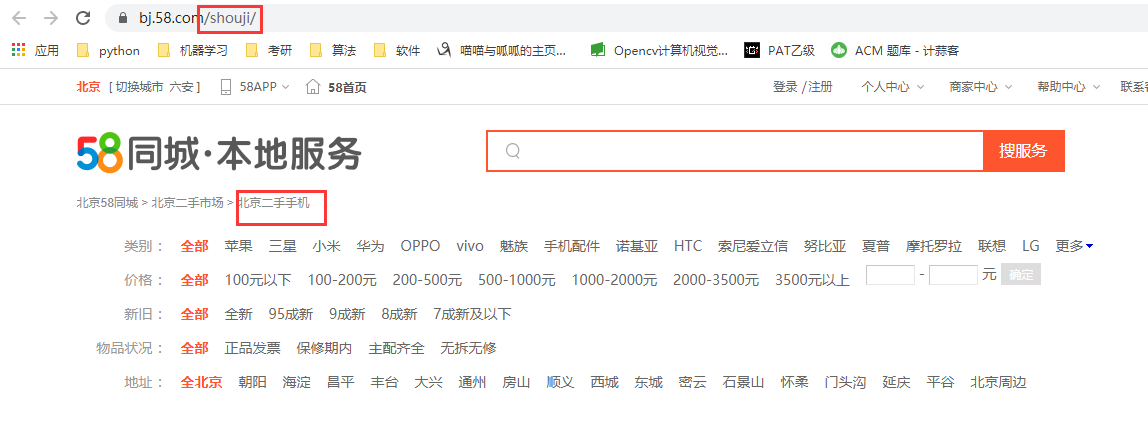
2.针对每一个小URL进行信息提取
from bs4 import BeautifulSoup
import requests
import time
import pymongo
client = pymongo.MongoClient('localhost', 27017)
ceshi = client['ceshi']
url_list = ceshi['url_list4']
item_info = ceshi['item_info4']
# 在最左边是在python 中对象的名称,后面的是在数据库中的名称
# spider 1
def get_links_from(channel, pages, who_sells=0):
# td.t 没有这个就终止
#https://bj.58.com/shouji/pn2/
list_view = '{}{}/pn{}/'.format(channel, str(who_sells), str(pages))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text, 'lxml')
#if else 为了防止https://bj.58.com/shouji/pn100/这样不存在的页面
if soup.find('td', 't'):
for link in soup.select('td.t a.t'):
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url': item_link})
#读取商品信息并且存入数据库
get_item_info(item_link)
time.sleep(1)
# return urls
else:
# It's the last page !
pass
# spider 2 解析每一个URL
def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
#如果爬取URL时候还存在,但是get_item_info解析每一个URL时候恰好被买走了,那么就会出现404错误
#分析404错误的页面的源代码发现有这么一句:
#<link rel="stylesheet" type="text/css" href="https://c.58cdn.com.cn/ui6/list/404news_v20161103135554.css">
#所以使用'404' in soup.find('link', type="text/css", rel="stylesheet").get('href').split('/')来判断
no_longer_exist = '404' in soup.find('link', type="text/css", rel="stylesheet").get('href').split('/')
if no_longer_exist:#存在404错误的话就pass
pass
else:
# title = soup.title.text.split('-')[0]
# # print(title)
# #网页源代码中存在这样一句:<title>OPPOreno10倍变焦版 - 北京58同城</title>
# price = soup.select('span.infocard__container__item__main__text--price')[0].text
# #<span class="infocard__container__item__main__text--price"> 360元</span>
# date = soup.select('span.detail-title__info__text')[0].text
# #<div class="detail-title__info__text">2020-01-24 更新</div>
# area = list(soup.select('.infocard__container__item__main a')[0].stripped_strings) if soup.find_all('span', 'infocard__container__item__main') else None
# #<div class="infocard__container__item__main"><a href='/chaoyang/shouji/' target="_blank">朝阳</a></div>
# #存入数据库
# item_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
# print({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
if ((soup.title.text.split('-')[0]=="请输入验证码 ws:36.161.10.181")|(soup.title.text.split('-')[0]=='【58同城 58.com】六安分类信息 ')):
title = ""
else:
title = soup.title.text.split('-')[0]
if soup.select('.infocard__container__item__main__text--price')!=[]:
price = soup.select('.infocard__container__item__main__text--price')[0].get_text().strip()
else:
price = []
# price = soup.select('.infocard__container__item__main__text--price')
# print(price)
if soup.select('.detail-title__info__text')!=[]:
date = soup.select('.detail-title__info__text')[0].get_text().strip()
else:
date = []
if soup.select('.infocard__container__item__main a')!=[]:
area = soup.select('.infocard__container__item__main a')[0].get_text().strip()
else:
area = []
#area 这里还有不完善的地方:需要判断如果area不存在的话应该设置为None
# if soup.find_all('span', 'infocard__container__item__main') else None
item_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
print({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
# get_links_from("http://bj.58.com/shouji/",2)
不知道怎么破解58的验证码反爬机制......在知乎上听大佬说,好像sleep可以解决
3.进行主函数编写+爬取次数的统计
from multiprocessing import Pool
from channel_extact import channel_list
from pages_parsing import get_links_from
from pages_parsing import get_item_info
def get_all_links_from(channel):
for i in range(1,100):
get_links_from(channel,i)
if __name__ == '__main__':
#多线程pool = Pool()
pool = Pool()
# pool = Pool(processes=6)
#map方法:map(一个函数,传入该函数的值)
pool.map(get_all_links_from,channel_list.split())
import time
from pages_parsing import url_list
while True:
print(url_list.find().count())
time.sleep(4)
#爬取1000条数据
if url_list.find().count()==1000:
break