ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号。在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号。
ROW_NUMBER()
说明:返回结果集分区内行的序列号,每个分区的第一行从1开始。
语法:ROW_NUMBER () OVER ([ <partition_by_clause> ] <order_by_clause>) 。
备注:ORDER BY 子句可确定在特定分区中为行分配唯一 ROW_NUMBER 的顺序。
参数:<partition_by_clause> :将 FROM 子句生成的结果集划入应用了 ROW_NUMBER 函数的分区。
<order_by_clause>:确定将 ROW_NUMBER 值分配给分区中的行的顺序。
返回类型:bigint 。
======================================================================
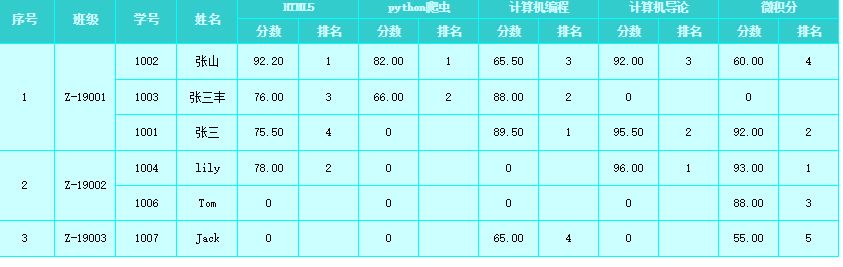
此次实现的是Finereport中根据学生各科成绩进行各科成绩的排名
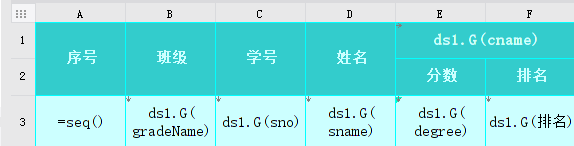
准备数据:
create table grade --班级表
(
gno INT, --编号
gradeName VARCHAR(100) --班级名称
)
go
insert into grade values(1901,'Z-19001'),
(1902,'Z-19002'),
(1903,'Z-19003')
go
create table course --课程表
(
cno INT,--课程编号
cname VARCHAR(100), --课程名称
tno INT --教师编号
)
go
insert into course values(1,'微积分',804),
(2,'计算机导论',801),
(3,'计算机编程',802),
(4,'python爬虫',803),
(5,'HTML5',805)
go
create table student --学生表
(
sno INT, --学生编号
sname VARCHAR(100),--学生姓名
ssex VARCHAR(100),--学生性别
sbirthday VARCHAR(100),--学生生日
gno INT --班级编号
)
go
insert into student values(1001,'张三','男','1998-12-11',1901),
(1002,'张山','男','1999-11-11',1901),
(1003,'张三丰','男','1978-09-19',1901),
(1004,'lily','女','1988-11-01',1902),
(1005,'candy','女','1989-03-12',1902),
(1006,'Tom','男','1992-05-28',1902),
(1007,'Jack','男','1994-04-13',1903),
(1008,'mark','男','1996-06-06',1903),
(1009,'shary','女','1997-06-08',1903)
go
create table score --分数表
(
sno INT, --学生编号
cno INT, --课程编号
degree decimal(10,2) --分数
)
go
insert into score values(1001,1,'92'),
(1001,2,'95.5'),
(1001,3,'89.5'),
(1002,2,'92'),
(1002,3,'65.5'),
(1002,5,'92.2'),
(1003,3,'88'),
(1003,4,'66'),
(1003,5,'76'),
(1004,1,'93'),
(1004,2,'96'),
(1004,5,'78')
go
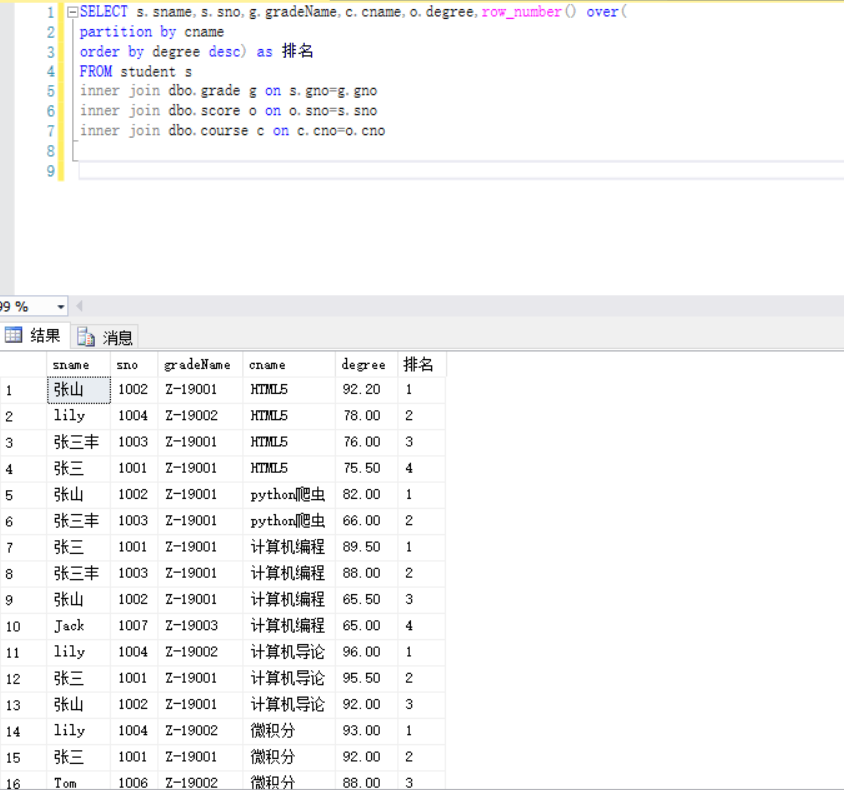
执行组内排序:
SELECT s.sname,s.sno,g.gradeName,c.cname,o.degree,row_number() over(partition by cname order by degree desc) as 排名 FROM student s inner join dbo.grade g on s.gno=g.gno inner join dbo.score o on o.sno=s.sno inner join dbo.course c on c.cno=o.cno
※※ over(partition by cname order by degree desc) 按照degree排序进行累计,order by是个默认的开窗函数,按照cname分区
查询结果:
报表展示结果: