假设磁盘上有N个.java文件,首先我们把这些java文件编译成class文件,继而java虚拟机启动会把这些class文件load到内存,当遇到new关键字的时候会根据类的模板信息实例化这个对象也就是在堆上面分配内存
用一副图来说明java实例化一个对象的基本流程

但是spring的bean实例化过程和一个普通java对象的实例化过程还是有区别的,同样用一幅图来说明一下

在springbean实例化简图当中我一共标记了⑤步;
逐一来说明吧
前提:假设在你的项目或者磁盘上有X和Y两个类,X是被加了spring注解的,Y没有加spring的注解;也就是正常情况下当spring容器启动之后通过getBean(X)能正常返回X的bean,但是如果getBean(Y)则会出异常,因为Y不能被spring容器扫描到不能被正常实例化;
①当spring容器启动的时候会去调用ConfigurationClassPostProcessor这个bean工厂的后置处理器完成扫描,关于什么是bean工厂的后置处理器下文再来详细解释;
比如当spring扫描到X的时候Class clazzx = X.class;那么这个classx里面就已经具备的前面说的那些信息了,确实如此,但是spring实例化一个bean不仅仅只需要这些信息,还有我上文说到的scope,lazy,dependsOn等等信息需要存储,所以spring设计了一个BeanDefintion的类用来存储这些信息。故而当spring读取到类的信息之后
②会实例化一个BeanDefinition的对象,继而调用这个对象的各种set方法存储信息;每扫描到一个符合规则的类,spring都会实例化一个BeanDefinition对象,然后把根据类的类名生成一个bean的名字(比如一个类IndexService,spring会根据类名IndexService生成一个bean的名字`indexService`,spring内部有一套默认的名字生成规则,但是程序员可以提供自己的名字生成器覆盖spring内置的,这个后面更新)
③继而spring会把这个beanDefinition对象和生成的beanName放到一个map当中,key=beanName,value=beanDefinition对象;至此上图的第①②③步完成。
这里需要说明的是spring启动的时候会做很多工作,不仅仅是完成扫描,在扫描之前spring还干了其他大量事情;比如实例化beanFacctory、比如实例化类扫描器等等,这里不讨论,在以后的文章
再来讨论
用一段代码和结果来证明上面的理论
@ComponentScan("com.zhyp.config")
@Configuration
public class AppConfig {
}
@Component
class X{
public X(){
System.out.println("-------x constructer");
}
}
class Y{
}
class Test{
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
applicationContext.register(AppConfig.class);
applicationContext.refresh();
}
}
④当spring把类所对应的beanDefintion对象存到map之后,spring会调用程序员提供的bean工厂后置处理器。
什么叫bean工厂后置处理器?在spring的代码级别是用一个接口来表示BeanFactoryPostProcessor,只要实现这个接口便是一个bean工厂后置处理器了,ConfigurationClassPostProcessor便是一个spring自己实现的bean工厂后置处理器,这个类是阅读spring源码当中最重要的类,没有之一;他完成的功能太多了,以后我们一一分析,先看一下这个类的类结构图。
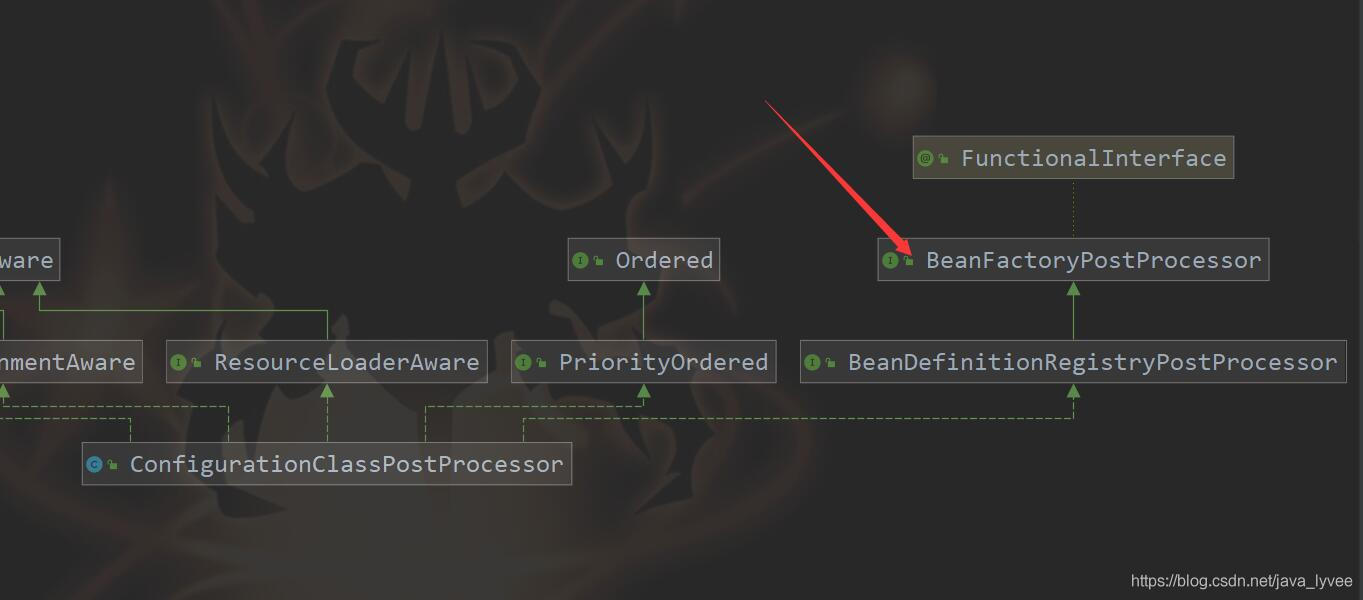
ConfigurationClassPostProcessor实现了很多接口,和本文有关的只需关注两个接口:BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor;但是由于
BeanDefinitionRegistryPostProcessor是继承了BeanFactoryPostProcessor所以也可以理解这是一个接口,但是笔者更加建议你理解成两个接口比较合适,因为spring完成上述①②③步的功能就是调用
BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法完成的,到了第④步的时候spring是执行BeanFactoryPostProcessor的postProcessBeanFactory方法;这里可能说的有点绕,大概意思spring完成①②③的功能是调用ConfigurationClassPostProcessor的BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法,到了第④步spring首先会调用ConfigurationClassPostProcessor的BeanFactoryPostProcessor的postProcessBeanFactory的方法,然后在调用程序员提供的BeanFactoryPostProcessor的postProcessBeanFactory方法,
所以上图当中第④步我画的是红色虚线,因为第④步可能没有(如果程序员没有提供自己的BeanFactoryPostProcessor;当然这里一定得说明,即使程序员没有提供自己扩展的BeanFactoryPostProcessor,spring也会执行内置的BeanFactoryPostProcessor也就是ConfigurationClassPostProcessor,所以上图画的并不标准,少了一步;即spring执行内置的BeanFactoryPostProcessor;
重点:我们用自己的话总结一下BeanFactoryPostProcessor的执行时机(不管内置的还是程序员提供)————Ⅰ:如果是直接实现BeanFactoryPostProcessor的类是在spring完成扫描类之后(所谓的扫描包括把类变成beanDefinition然后put到map之中),在实例化bean(第⑤步)之前执行;Ⅱ如果是实现BeanDefinitionRegistryPostProcessor接口的类;诚然这种也叫bean工厂后置处理器他的执行时机是在执行直接实现BeanFactoryPostProcessor的类之前,和扫描(上面①②③步)是同期执行;假设你的程序扩展一个功能,需要在这个时期做某个功能则可以实现这个接口;但是笔者至今没有遇到这样的需求,如果以后遇到或者看到再来补上;(说明一下当笔者发表这篇博客有一个读者联系笔者说他看到了一个主流框架就是扩展了BeanDefinitionRegistryPostProcessor类,瞬间笔者如久旱遇甘霖,光棍遇寡妇;遂立马请教;那位读者说mybatis的最新代码里面便是扩展这个类来实现的,笔者记得以前mybatis是扩展没有用到这个接口,后来笔者看了一下最新的mybatis源码确实如那位读者所言,在下一篇笔者分析主流框架如何扩展spring的时候更新)
那么第④步当中提到的执行程序员提供的BeanFactoryPostProcessor到底有什么意义呢?程序员提供BeanFactoryPostProcessor的场景在哪里?有哪些主流框架这么干过呢?
首先回答第一个问题,意义在哪里?可以看一下这个接口的方法签名
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
其实是spring提供的一个扩展点(spring提供很多扩展点,学习spring源码的一个非常重要的原因就是要学会这些扩展点,以便对spring做二次开发或者写出优雅的插件),可以让程序员干预bean工厂的初始化过程(重点会考);这句话最重要的几个字是初始化过程,注意不是实例化过程 ;
初始化和实例化有很大的区别的,特别是在读spring源码的时候一定要注意这两个名词;翻开spring源码你会发现整个容器初始化过程就是spring各种后置处理器调用过程;而各种后置处理器当中大体分为两种;一种关于实例化的后置处理器一种是关于初始化的后置处理器,这里不是笔者臆想出来的,如果读者熟悉spring的后置处理器体系就可以从spring的后置处理器命名看出来spring对初始化和实例化是有非常大的区分的。
说白了就是——beanFactory怎么new出来的(实例化)BeanFactoryPostProcessor是干预不了的,但是beanFactory new出来之后各种属性的填充或者修改(初始化)是可以通过BeanFactoryPostProcessor来干预;可以看到BeanFactoryPostProcessor里唯一的方法postProcessBeanFactory中唯一的参数就是一个标准的beanFactory对象——ConfigurableListableBeanFactory;既然spring在调用postProcessBeanFactory方法的时候把已经实例化好的beanFactory对象传过来了,那么自然而然我们可以对这个beanFactory肆意妄为了;
@Component public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory){ //转换为子类,因为父类没有添加beanDefintion对象的api
DefaultListableBeanFactory defaultbf =(DefaultListableBeanFactory)beanFactory
//new一个Y的beanDefinition对象,方便测试动态添加
GenericBeanDefinition y = new GenericBeanDefinition();
y.setBeanClass();
//添加一个beanDefinition对象,原本这个Y没有被spring扫描到
defaultbf.registerBeanDefinition ("y",y);
//得到一个已经被扫描出来的beanDefintion对象x
//因为X本来就被扫描出来了,所以是直接从map中获取
BeanDefinition x = defaultbf.getBeanDefinition("x");
//修改这个X的beanDefintion对象的class为Z
//原本这个x代表的class为X.class;现在为Z.class
X.setBeanClassName("com.luban.beanDefinition.Z");
}
项目里面有三个类X,Y,Z其中只有X加了@Component注解;也就是当代码执行到上面那个方法的时候只扫描到了X;beanFactory里的beanDefinitionMap当中也只有X所对应的beanDefinition对象;笔者首先new了一个Y所对应的beanDefinition对象然后调用registerBeanDefinition("y", y);把y对应的beanDefinition对象put到beanDefinitionMap,这是演示动态添加一个自己实例化的beanDefinition对象;继而又调用getBeanDefinition("x")得到一个已经存在的beanDefinition对象,然后调用x.setBeanClassName("Z");把x所对应的beanDefinition对象所对应的class改成了Z,这是演示动态修改一个已经扫描完成的beanDefinition对象;