| 这个作业属于哪个课程 | 信息安全1812 |
|---|---|
| 这个作业要求在哪里 | 个人项目作业 |
| 这个作业的目标 | 熟悉软件开发的规范流程 |
项目介绍
仓库地址
开发思路
在做前期准备时,我查阅了许多算法,诸如 SimHash 算法、余弦相似度算法等。查阅中,我偶然看到了 一篇讲述使用二维矩阵求出两个字符串中最长公共字符串文章 ,便开始思考能不能在不用任何分词算法的情况下,只通过依次算出对应的两个句子的所有公共字符串的数量,达到计算文章重复率的目的。最终,我选择了使用二维矩阵求出两个字符串中所有连续的公共字符串这一思路并着手开发本项目。
核心算法的原理
参照文章 Java算法——求出两个字符串的最长公共字符串,本项目的核心算法基于此文章所描述的算法改造而成
核心算法的代码实现 —— repeated_str_with_matrix.py
-
RepeatedStrWithMatrix类的初始化_org_str表示原始字符串,_cmp_str表示待比较的字符串,_res_lst表示用于存储所有公共字符串的列表
def __init__(self, _org_str, _cmp_str): self._org_str = _org_str self._org_str_len = len(_org_str) self._cmp_str = _cmp_str self._cmp_str_len = len(_cmp_str) self._res_lst = [] self._init_matrix() self._calc_res_lst() -
初始化矩阵函数
_init_matrix()- 初始化一个
i * j的二维矩阵,其中i表示待比较的字符串的长度,j表示原始字符串的长度 - 矩阵中所有位置置
0
def _init_matrix(self): """Init matrix""" self._matrix = [[0] * self._org_str_len for _ in range(self._cmp_str_len)] - 初始化一个
-
计算所有公共字符串
- 遍历整个矩阵,遍历时的索引
i表示待比较的字符串中下标为i的字符,j表示原始字符串中下标为j的字符 - 当遍历到第一行和第一列时,若
i和j所对应的的字符相同,则 当前位置置1 - 当遍历到其它位置时
- 当前位置的值为其左上角位置的值加
1 - 若当前位置的值为
0而其左上角位置的值非0,说明其左上角的对角线上存在重复的字符串,需触发相应的处理函数_push_res()
- 当前位置的值为其左上角位置的值加
- 特别地,若遍历到最后一行和最后一列,若当前位置的值非
0,同样说明*其左上角的对角线上存在重复的字符串**,需触发相应的处理函数_push_res()
def _calc_res_lst(self): """Calculate common parts""" for i, str2_val in enumerate(self._cmp_str): for j, str1_val in enumerate(self._org_str): if str1_val == str2_val: val = self._matrix[i - 1][j - 1] + 1 if i and j else 1 self._matrix[i][j] = val if i and j: if self._matrix[i - 1][j - 1] and not self._matrix[i][j]: self._push_res(i, j) if i == self._cmp_str_len - 1 or j == self._org_str_len - 1: if self._matrix[i][j] != 0: self._push_res(i + 1, j + 1) - 遍历整个矩阵,遍历时的索引
-
处理重复字符串的函数
_push_res()- 若该字符串的长度大于
1,则将其存入_res_lst
def _push_res(self, i, j): length = self._matrix[i - 1][j - 1] if length > 1: self._res_lst.append(self._org_str[j - length:j]) - 若该字符串的长度大于
核心算法的单元测试 —— test_matrix.py
- 测试方法: 使用 Python 内置的
unittest模块 - 测试用例
test_matrix_cases.json
{
"cases": [
{
"org_str": "今天是星期天",
"cmp_str": "今天是周天",
"expected": 3
},
{
"org_str": "天气晴",
"cmp_str": "天气晴朗",
"expected": 3
},
{
"org_str": "今天晚上我要去看电影",
"cmp_str": "我晚上要去看电影",
"expected": 7
},
{
"org_str": "delicate",
"cmp_str": "dedicate",
"expected": 7
}
]
}
- 测试结果
Ran 1 test in 0.013s
OK
核心算法的缺点
该算法的可行性高度依赖对文章句子划分的准确度。
目前,本项目里采用的是先将文章按换行符分成几段段落,再将每个段落按标点符号划分成句后,对两篇文章里对应段落里的句子一一比对,尽量确保每次执行核心算法的两个字符串是相对应的两个句子,而不是毫无相干的两句,以确保最终结果的准确。
但是,就以项目中的五个用于对比的测试用例来说,只有像 orig_0.8_add.txt 和 orig_0.8_del.txt 这种在原句上进行增删、对整体句子、段落的结构影响不大的文件才是该算法能够胜任的。而像 orig_0.8_dis_15.txt 这种有些原句被分拆成三行以及有些标点符号缺失了的文件,则因为无法进行准确分句而导致最终得到的重复率及不准确。
开发环境
- Microsoft Windows 10 Insider Preview Build 20221
- Microsoft Visual Studio Code 1.49.1
- Python 3.8.5 64-bit
代码规范 & 静态检查
本项目的代码规范采用 Google 的 Python 风格规范 ,并配置了 flake8 和 yapf 作为代码静态检查工具和代码风格化工具
目录结构
|--.vscode
|--analysis
| |-- gprof2dot.py 将 Python 内置的cProfile模块的分析输出文件转为dot图谱文件
|--calc-text-repetition-rate 项目目录
| |-- algo 核心算法
| |-- test 单元测试
| |-- util 辅助工具函数
| |-- main.py 主函数入口
|--test-cases 测试用例
|--.gitignore
|--README.md
|--requirements.txt 项目依赖
运行要求
安装 & 使用
安装依赖
$ pip install -r requirements.txt
第三方依赖列表
计算重复率
$ cd calc-text-repetition-rate
$ python main.py [原始文件] [待比较文件] [输出文件]
计算重复率 + 使用 cProfile 进行性能分析
$ python -m cProfile main.py [原始文件] [待比较文件] [输出文件] # 输出性能分析结果至控制台
$ python -m cProfile -o [性能分析输出文件] main.py [原始文件] [待比较文件] [输出文件] # 输出性能分析结果至文件
$ python -m cProfile -o [性能分析输出文件] -s tottime main.py [原始文件] [待比较文件] [输出文件] # 输出性能分析结果至文件、按函数内部消耗的总时间排序
详细操作可参阅 cProfile 文档
将 cProfile 模块的性能分析结果图形化
$ cd analysis
$ python gprof2dot.py -f pstats [cProfile 性能分析输出文件] | dot -Tpng -o [图片输出文件]
详细操作可参阅 jrfonseca/gprof2dot 和 graphviz
运行单元测试
$ cd calc-text-repetition-rate/test
$ python test_matrix.py
性能分析
用 cProfile 模块分析计算测试用例文件夹中的 orig.txt 和 orig_0.8_add.txt 的文本重复率且将结果输出到同文件夹下的 orig_0.8_add_answer.txt 的整个过程,并将其图形化。
- 文本重复率输出结果如下
原始文件名: orig.txt
待比较文件名: orig_0.8_add.txt【文本重复率运算结果】
- 利用二维矩阵查找连续重复的字符串实现
文本重复率: 76.11%
运算时间: 0.03719s
- 性能分析结果如下:
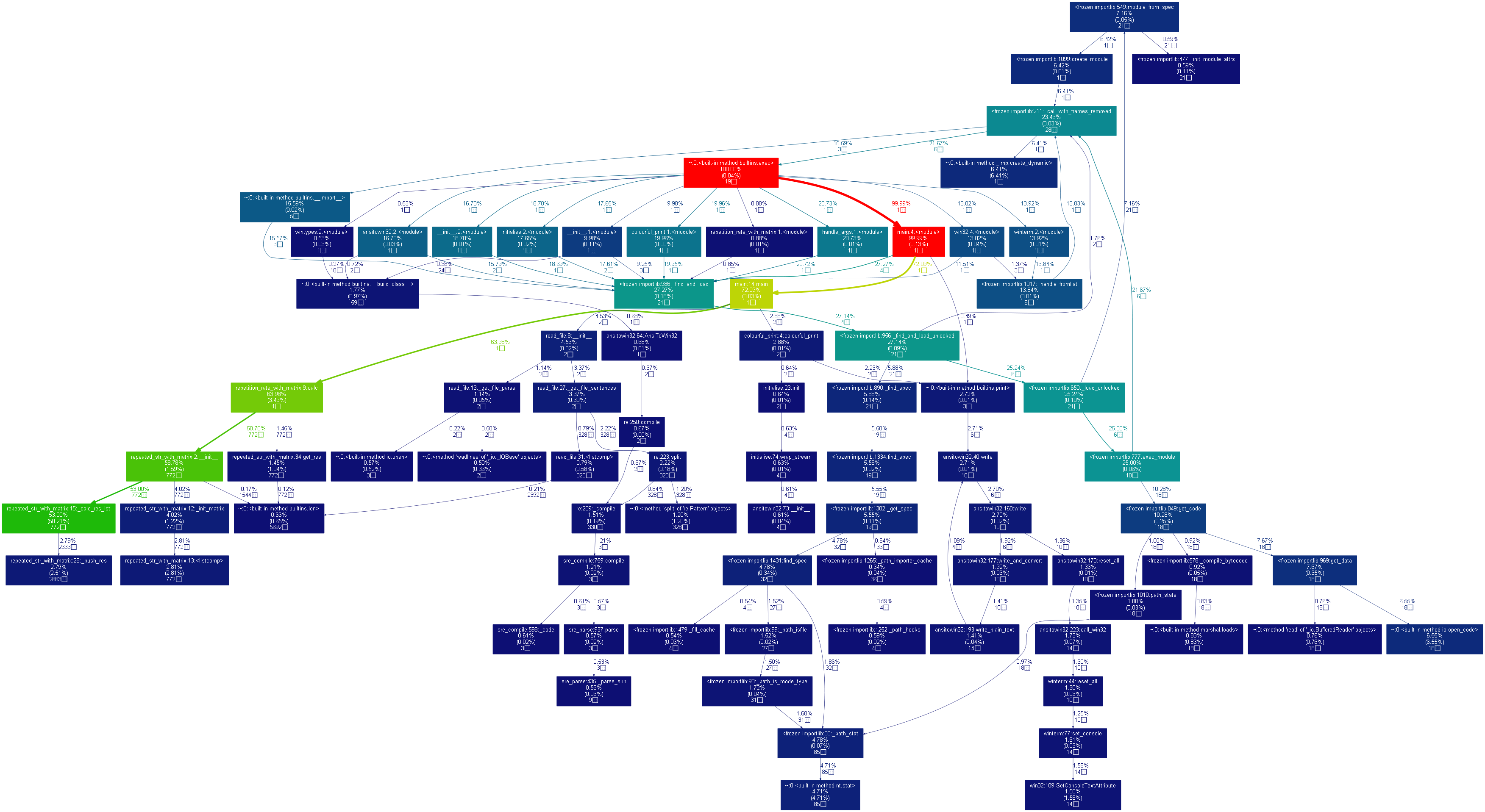
个人开发流程 (Personal Software Process, PSP)
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) | |
| Planning | 计划 | 20 | 30 |
| - Estimate | - 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 655 | 835 |
| - Analysis | - 需求分析 (包括学习新技术) | 60 | 60 |
| - Design Spec | - 生成设计文档 | 20 | 30 |
| - Design Review | - 设计复审 | 10 | 10 |
| - Coding Standard | - 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| - Design | - 具体设计 | 30 | 60 |
| - Coding | - 具体编码 | 200 | 240 |
| - Code Review | - 代码复审 | 30 | 30 |
| - Test | - 测试(自我测试,修改代码,提交修改) | 300 | 400 |
| Reporting | 报告 | 170 | 320 |
| - Test Report | - 测试报告 | 60 | 100 |
| - Size Measurement | - 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 100 | 200 |
| 合计 | 845 | 1185 | |