迭代器和生成器
一 、迭代的概念
#迭代器即迭代的工具,那什么是迭代呢? #迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值 while True: #只是单纯地重复,因而不是迭代 print('===>') l=[1,2,3] count=0 while count < len(l): #迭代 print(l[count]) count+=1
二、什么是迭代器协议
1、迭代器协议指:对象必须提供一个 next 方法,执行该方法要么返回迭代中的下一项,要么引起一个StopIteration异常,以终止迭代(只能往后不能往前退)
2、可迭代对象:实现了迭代器协议的对象(如何实现:对象内部定义了一个__iter__() 方法)
3、协议是一种约定,可迭代对象实现了迭代器协议,Python内部工具(如for循环,sum,min,max等)使用迭代器协议访问对象。
三、为何要有迭代器?什么是可迭代对象?什么是迭代器对象?
#1、为何要有迭代器? 对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,
若还想取出其内部包含的元素,则必须找出一种不依赖于索引的迭代方式,这就是迭代器 #2、什么是可迭代对象? 可迭代对象指的是内置有 __iter__ 方法的对象,即 obj.__iter__,如下 'hello'.__iter__ (1,2,3).__iter__ [1,2,3].__iter__ {'a':1}.__iter__ {'a','b'}.__iter__ open('a.txt').__iter__ #3、什么是迭代器对象? 可迭代对象执行obj.__iter__()得到的结果就是迭代器对象 而迭代器对象指的是即内置有__iter__又内置有__next__方法的对象 文件类型是迭代器对象 open('a.txt').__iter__() open('a.txt').__next__() #4、注意: 迭代器对象(obj.__iter__())一定是可迭代对象,而可迭代对象("hello")不一定是迭代器对象
四、 迭代器对象的使用
dic={'a':1,'b':2,'c':3}
iter_dic=dic.__iter__() #得到迭代器对象,迭代器对象即有__iter__又有__next__,但是:迭代器.__iter__()得到的仍然是迭代器本身
iter_dic.__iter__() is iter_dic #True
print(iter_dic.__next__()) #等同于next(iter_dic)
print(iter_dic.__next__()) #等同于next(iter_dic)
print(iter_dic.__next__()) #等同于next(iter_dic)
# print(iter_dic.__next__()) #抛出异常StopIteration,或者说结束标志
补充:print(next(iter_dic)) # next()<===>iter_dic.__next__()
#有了迭代器,我们就可以不依赖索引迭代取值了
#下面是用一个while循环 模拟 for循环
li = [1,2,3,4,5]
# for i in li:
# print(i)
"""模拟for循环过程"""
iter_li = li.__iter__()
while True:
try:
print(iter_li.__next__())
except StopIteration:
# print("迭代完毕,循环结束!")
break
#这么写太丑陋了,需要我们自己捕捉异常,控制next,python这么牛逼,能不能帮我解决呢?能,请看for循环
五、 for循环
#基于for循环,我们可以完全不再依赖索引去取值了 dic={'a':1,'b':2,'c':3} for k in dic: print(dic[k]) #for循环的工作原理 #1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic #2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码 #3: 重复过程2,直到捕捉到异常StopIteration,结束循环
六、 迭代器的优缺点
#优点: - 提供一种统一的、不依赖于索引的迭代方式 - 惰性计算,节省内存 #缺点: - 无法获取长度(只有在next完毕才知道到底有几个值) - 一次性的,只能往后走,不能往前退
一、什么是生成器
生成器可以理解为一种数据类型,这种数据类型自动实现迭代器协议(其他的数据类型需要调用自己的__iter__() 方法,所以生成器就是可迭代对象)
二、生成器在Python中的表现形式
1、生成器函数:常规函数定义,但是使用yield语句 而不是return 语句返回函数结果,碰到一个yield语句返回一个结果(def 函数只能有一个return 但是可以有多个yield),
在每个结果中间保留函数状态,下次执行__next__() 时从上次函数保留的状态处继续执行


#只要函数内部包含有yield关键字,那么函数名()的到的结果就是生成器,并且不会执行函数内部代码 def func(): print('====>first') yield 1 print('====>second') yield 2 print('====>third') yield 3 print('====>end') g=func() print(g) #<generator object func at 0x0000000002184360>
import time def test(): print("开始生孩子了。。。") yield "我" #第1次执行 __next__() 碰到一个yield 返回,函数保留到该状态 time.sleep(3) print("开始生儿子了。。。") #第2次执行 __next__() 碰到一个yield 返回,函数保留到该状态 yield "儿子" time.sleep(3) print("开始生孙子了。。。") #第3次执行 __next__() 碰到一个yield 返回,函数保留到该状态 yield "孙子" time.sleep(3) print("开始生重孙子了。。。") #第4次执行 __next__() 碰到一个yield 返回,函数保留到该状态 yield "重孙子" res = test() print(res) #<generator object test at 0x00000174FBCF10A0> print(res.__next__()) #开始生孩子了。。。 我 print(res.__next__()) #开始生儿子了。。。 儿子 print(res.__next__()) #开始生孙子了。。 孙子 print(res.__next__()) #开始生重孙子了。。 重孙子

2、生成器表达式:类似于列表推导,但是生成器返回按需产生结果的一个对象,而不是一次性构建一个结果列表(优点:可以节省内存)
补充:三元表达式和列表解析
# 三元表达式 name = "xiong" # name = "wang" res = "帅哥" if name == "xiong" else "sb" print(res) li1 = ["鸡蛋%s"%i for i in range(10)] #二元列表解析 li2 = ["鸡蛋%s"%i for i in range(10) if i>5] #三元列表解析 print(li1) print(li2)
li3 = ("鸡蛋%s"%i for i in range(10) if i>5) #生成器表达式 print(li3) #<generator object <genexpr> at 0x000002230C8F1048> print(li3.__next__()) print(li3.__next__())
总结:
1、把列表解析的 [] 换成 () 得到的就是生成器表达式
2、列表解析和生成器表达式都是一种便利的编程方式,只不过生成器表达式更省内存
3、Python不但使用迭代器协议让for循环变得更加通用,而且大部分内置函数也使用迭代器协议访问对象。
例如:sum() max() min() sorted()
# 可以直接使用sum求和 ss1 = sum(x**2 for x in range(10)) print(ss1) # 不需要多此一举先构造一个列表 ss2 = sum([x**2 for x in range(10)]) print(ss2)
三、为何使用生成器及生成器的优点
Python使用生成器对延迟操作提供了支持。所谓延迟操作,是指在需要的时候才产生结果,而不是立即产生结果存在内存中。这样生成器节省了内存
生成器总结:
1、是可迭代对象
2、实现延迟操作,省内存(可以保留函数运行状态,碰到一个yield返回,下次再运行__next__() 从上次停下来的地方继续运行)
3、生成器本质和其他数据类型一样,都是实现了迭代器协议,只不过生成器附加了延迟操作省内存的特点,而其他可迭代对象没有这个优点
四、生成器总结
综上已经对生成器有了一定的认识,下面我们以生成器函数为例进行总结
- 语法上和函数类似:生成器函数和常规函数几乎是一样的。它们都是使用def语句进行定义,差别在于,生成器使用yield语句返回一个值,而常规函数使用return语句返回一个值
- 自动实现迭代器协议:对于生成器,Python会自动实现迭代器协议,以便应用到迭代背景中(如for循环,sum函数)。由于生成器自动实现了迭代器协议,所以,我们可以调用它的next方法,并且,在没有值可以返回的时候,生成器自动产生StopIteration异常
- 状态挂起:生成器使用yield语句返回一个值。yield语句挂起该生成器函数的状态,保留足够的信息,以便之后从它离开的地方继续执行
优点一:生成器的好处是延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据量处理,将会非常有用。
#列表解析 sum([i for i in range(100000000)])#内存占用大,机器容易卡死 #生成器表达式 sum(i for i in range(100000000))#几乎不占内存
优点二:生成器还能有效提高代码可读性
#求一段文字中,每个单词出现的位置 def index_words(text): result = [] if text: result.append(0) for index, letter in enumerate(text, 1): if letter == ' ': result.append(index) return result print(index_words('hello alex da sb'))
#求一段文字中每个单词出现的位置 def index_words(text): if text: yield 0 for index, letter in enumerate(text, 1): if letter == ' ': yield index g=index_words('hello alex da sb') print(g) print(g.__next__()) print(g.__next__()) print(g.__next__()) print(g.__next__()) print(g.__next__())#报错
这里,至少有两个充分的理由说明 ,使用生成器比不使用生成器代码更加清晰:
- 使用生成器以后,代码行数更少。大家要记住,如果想把代码写的Pythonic,在保证代码可读性的前提下,代码行数越少越好
- 不使用生成器的时候,对于每次结果,我们首先看到的是result.append(index),其次,才是index。也就是说,我们每次看到的是一个列表的append操作,只是append的是我们想要的结果。使用生成器的时候,直接yield index,少了列表append操作的干扰,我们一眼就能够看出,代码是要返回index。
这个例子充分说明了,合理使用生成器,能够有效提高代码可读性。只要大家完全接受了生成器的概念,理解了yield语句和return语句一样,也是返回一个值。那么,就能够理解为什么使用生成器比不使用生成器要好,能够理解使用生成器真的可以让代码变得清晰易懂。
注意事项:生成器只能遍历一次(母鸡一生只能下一定数量的蛋,下完了就死掉了)
人口信息.txt文件内容 {'name':'北京','population':10} {'name':'南京','population':100000} {'name':'山东','population':10000} {'name':'山西','population':19999} def get_provice_population(filename): with open(filename) as f: for line in f: p=eval(line) yield p['population'] gen=get_provice_population('人口信息.txt') all_population=sum(gen) for p in gen: print(p/all_population) 执行上面这段代码,将不会有任何输出,这是因为,生成器只能遍历一次。在我们执行sum语句的时候,就遍历了我们的生成器,当我们再次遍历我们的生成器的时候,将不会有任何记录。所以,上面的代码不会有任何输出。 因此,生成器的唯一注意事项就是:生成器只能遍历一次。
def test(): for i in range(4): yield i g=test() g1=(i for i in g) g2=(i for i in g1) print(list(g1)) print(list(g2))
def add(n,i): return n+i def test(): for i in range(4): yield i g=test() for n in [1,10]: g=(add(n,i) for i in g) print(list(g))
import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def list_files(target): while 1: dir_to_search=yield for top_dir,dir,files in os.walk(dir_to_search): for file in files: target.send(os.path.join(top_dir,file)) @init def opener(target): while 1: file=yield fn=open(file) target.send((file,fn)) @init def cat(target): while 1: file,fn=yield for line in fn: target.send((file,line)) @init def grep(pattern,target): while 1: file,line=yield if pattern in line: target.send(file) @init def printer(): while 1: file=yield if file: print(file) g=list_files(opener(cat(grep('python',printer())))) g.send('/test1')
五、练习
1、自定义函数模拟range(1,7,2)
2、模拟管道,实现功能:tail -f access.log | grep '404'
#题目一: def my_range(start,stop,step=1): while start < stop: yield start start+=step #执行函数得到生成器,本质就是迭代器 obj=my_range(1,7,2) #1 3 5 print(next(obj)) print(next(obj)) print(next(obj)) print(next(obj)) #StopIteration #应用于for循环 for i in my_range(1,7,2): print(i) #题目二 import time def tail(filepath): with open(filepath,'rb') as f: f.seek(0,2) while True: line=f.readline() if line: yield line else: time.sleep(0.2) def grep(pattern,lines): for line in lines: line=line.decode('utf-8') if pattern in line: yield line for line in grep('404',tail('access.log')): print(line,end='') #测试 with open('access.log','a',encoding='utf-8') as f: f.write('出错啦404 ')
生产者消费者模型(吃包子案例--->实现并发)
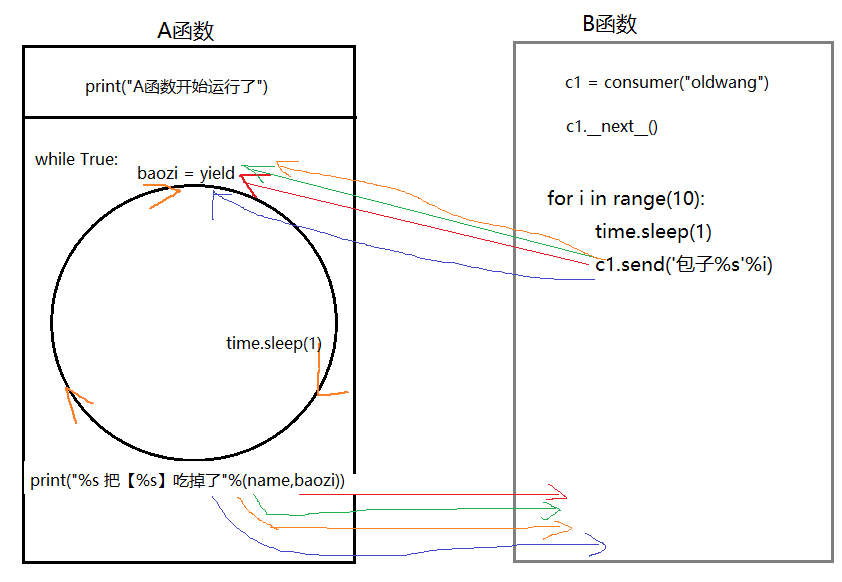
def consumer(name): print('我是[%s],我准备开始吃包子了' %name) while True: baozi=yield time.sleep(1) print('%s 很开心的把【%s】吃掉了' %(name,baozi)) def producer(): c1=consumer('wupeiqi') c2=consumer('yuanhao_SB') c1.__next__() c2.__next__() for i in range(10): time.sleep(1) c1.send('包子 %s' %i) c2.send('包子 %s' %i) producer() ##输出结果 我是[wupeiqi],我准备开始吃包子了 我是[yuanhao_SB],我准备开始吃包子了 wupeiqi 很开心的把【包子 0】吃掉了 yuanhao_SB 很开心的把【包子 0】吃掉了 wupeiqi 很开心的把【包子 1】吃掉了 yuanhao_SB 很开心的把【包子 1】吃掉了 wupeiqi 很开心的把【包子 2】吃掉了 yuanhao_SB 很开心的把【包子 2】吃掉了 wupeiqi 很开心的把【包子 3】吃掉了 yuanhao_SB 很开心的把【包子 3】吃掉了 wupeiqi 很开心的把【包子 4】吃掉了 yuanhao_SB 很开心的把【包子 4】吃掉了 wupeiqi 很开心的把【包子 5】吃掉了 yuanhao_SB 很开心的把【包子 5】吃掉了 wupeiqi 很开心的把【包子 6】吃掉了 yuanhao_SB 很开心的把【包子 6】吃掉了 wupeiqi 很开心的把【包子 7】吃掉了 yuanhao_SB 很开心的把【包子 7】吃掉了 wupeiqi 很开心的把【包子 8】吃掉了 yuanhao_SB 很开心的把【包子 8】吃掉了 wupeiqi 很开心的把【包子 9】吃掉了 yuanhao_SB 很开心的把【包子 9】吃掉了
参考: