结对第二次—文献摘要热词统计及进阶需求
作业格式
-
这个作业属于哪个课程 :软件工程 1916|W
-
作业要求 :结对第二次—文献摘要热词统计及进阶需求
-
作业目标:结对完成一次编程任务,了解测试的方法及逻辑,能够合作完成一个较完整的项目,包括需求分析、编程、测试等。
-
GitHub链接:221600306&221600307
-
代码签入记录:
作业正文
分工
- 221600306
- 需求分析
- 结构设计
- 编码开发
- 221600307
- 需求分析
- 代码分析测试
- 博客撰写
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 600 | 720 |
| • Analysis | • 需求分析 (包括学习新技术) | 100 | 60 |
| • Design Spec | • 生成设计文档 | 60 | 120 |
| • Design Review | • 设计复审 | 60 | 45 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 30 | 30 |
| • Coding | • 具体编码 | 500 | 600 |
| • Code Review | • 代码复审 | 60 | 100 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | 90 | 150 |
| • Test Report | • 测试报告 | 50 | 40 |
| • Size Measurement | • 计算工作量 | 10 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 1800 | 2125 |
解题思路
-
拿到题目之后我们先是对基础功能进行了分析,决定初步实现之后再考虑进阶需求。作业的基础功能:
- 统计文件的字符数:
- 统计文件的单词总数
- 统计文件的有效行数
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt
- 输出的单词统一为小写格式
我们打算将统计字符、单词数、行数以及词频作为四个相关联的函数。选择编程语言方面,一是对Java比较熟悉,二是考虑到进阶需求需要编写爬虫,而我的队友此前已有过用Java编写爬虫的经验,因此我们选定Java作为开发语言。
-
需求确定之后进入开发阶段,制定代码规范以及绘制类图、程序运行流程图,分配测试任务。查找资料方面,一般是上网搜索,有时也会翻看相关书籍。
设计实现过程
代码组织
-
基本需求
-
代码方面由于将主要功能分解成了几个函数,因此只有一个main类。

-
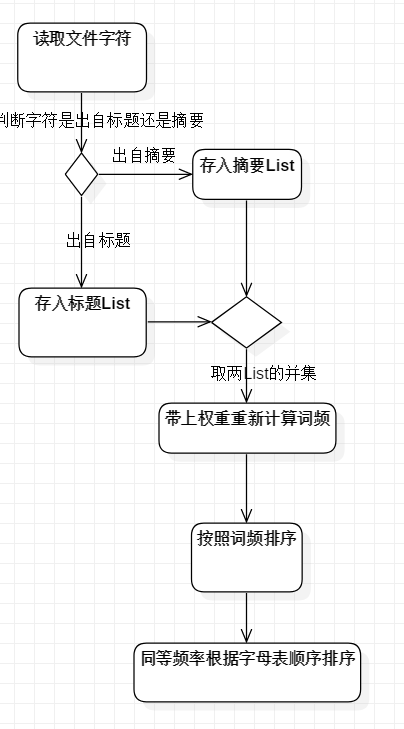
此类包含四个主要功能函数,topTenWords()统计出现频率最高的前十个单词,countLine()统计非空白有效行数,countWord()统计单词数,countChar()则统计字符数。由于单个函数的逻辑并不复杂,因此不对单个函数进行流程图分析,只给出整个类在读取文件并输出指定内容过程的主要流程图。由于四个函数间互有联系,后续函数需用到前边函数的结果,因此在运行过程中需遵循一定的函数顺序。

-
-
进阶需求
-
爬虫思路:主要使用jsoup(jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 )。先浏览CVPR2018官网,获取页面的全部代码,找到需要的内容(论文题目、摘要),利用获取class、id、tag的方法获取所需数据,然后将获取到的数据转换为字符串,设置格式后输出。
-
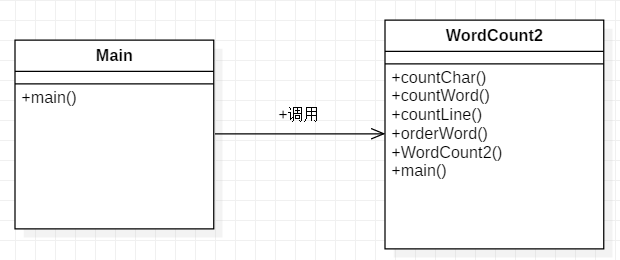
功能函数:共分成以下几个功能函数:countChar()统计字符、countWord()统计单词、countLine()统计行数、orderWord()统计单词权重、WordCount2()构造函数。类图如下:
-
由于进阶需求是基于基础需求的开发,因此主要功能逻辑与基础需求一致,主要区别在于加入了权重的计算,因此只重点给出计算权重的函数orderWord()的流程图。
- orderWord
-
单元测试
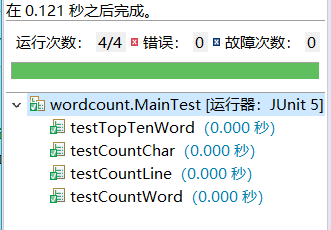
- 利用JUnit对每个函数即每个功能进行测试,确保此功能没有错误发生,避免在开发完成后进行统一测试难以找到错误。
- 部分单元测试过程截图展示
性能分析优化
利用JProfiler对程序进行性能监测。
-
overView
-
Memory
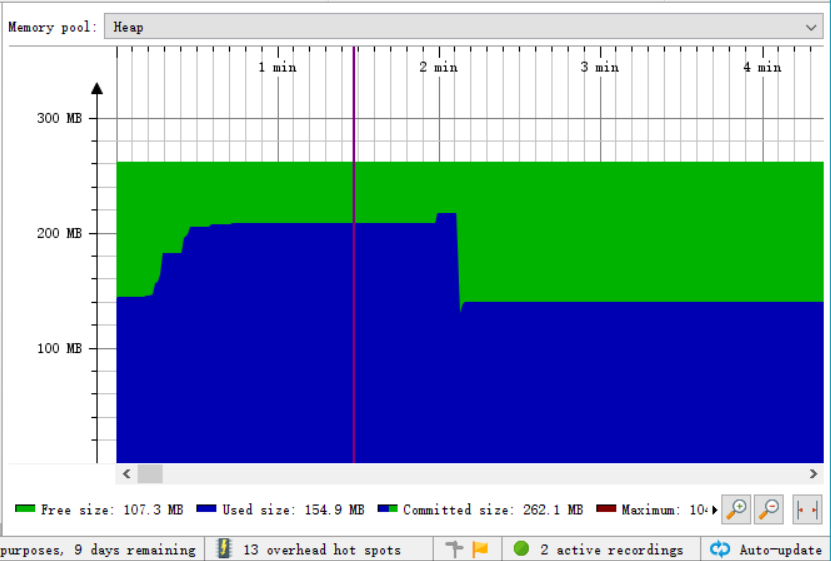
可看到内存的分配回收过程。
- CPUview
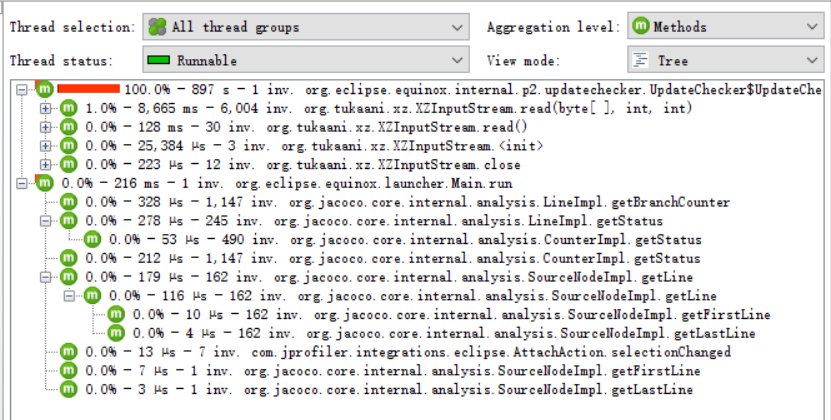
代码中最耗时的函数是countWord函数,在测试时也有所体现。
代码说明
-
基本需求
-
countChar函数
public int countChar() { int count=0; try { FileInputStream fileInputStream = new FileInputStream(file); int charInt = fileInputStream.read(); for (count = 0; charInt != -1; count++) { fileCharIntegers.add(charInt); charInt=fileInputStream.read(); } fileInputStream.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } //处理回车换行 13 10 为一个字符 for (int i = 0; i < fileCharIntegers.size(); i++) { if (fileCharIntegers.elementAt(i)==13) { if (i<fileCharIntegers.size() && fileCharIntegers.elementAt(i+1)==10) { count--; } } } return count; }代码说明:读取文件input.txt的内容,因为 算作一个字符,因此统计完字符数之后还需重新判断相邻两字符是否是 ,如果是将字符数-1。
-
countWord函数
for (int i = 0; i < fileCharIntegers.size(); i++) { //四个英文字母开头 if (Character.isLetter((char)(int)fileCharIntegers.elementAt(i))){ countFourLetter++; sb.append((char)(int)fileCharIntegers.elementAt(i)); if (countFourLetter>=4 && i == fileCharIntegers.size()-1) { strings.add(sb.toString().toLowerCase()); } }else if (Character.isDigit((char (int)fileCharIntegers.elementAt(i))&&countFourLetter>=4) { sb.append((char)(int)fileCharIntegers.elementAt(i)); if (countFourLetter>=4 && i == fileCharIntegers.size()-1) { strings.add(sb.toString().toLowerCase()); } //System.out.println("the digit:"+sb.toString()); }else { if (countFourLetter>=4) { strings.add(sb.toString().toLowerCase()); } countFourLetter=0; sb.delete(0, sb.length()); } }代码说明:判断字符串是否由四个字母开头,之后对后续字符进行判断(是否是字母、数字或空白字符),判断完毕后转换为小写,存入map中。
-
countLine
while((string = d.readLine()) != null){ //System.out.println(count); char chars[] = new char[string.length()]; chars=string.toCharArray(); for (int i = 0; i < chars.length; i++) { //System.out.println(chars[i]); if ((int)chars[i] > 32 && (int)chars[i] != 127) { count++; break; } } }代码说明:由readLine函数读取行数,再进行是否包含空白字符的判断,若不是有效行则不计数。
-
topTenWord
for (int i = 0; i < strings.size(); i++) { map.put(strings.elementAt(i), 0); } //统计词频 for (int i = 0; i < strings.size(); i++) { int temp=map.get(strings.elementAt(i)); temp++; map.put(strings.elementAt(i), temp); } //输出出现频率最高的10个单词, map<key,value>以value排序 //通过ArrayList构造函数把map.entrySet()转换成list list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet()); //通过比较器实现比较排序 Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> mapping1, Map.Entry<String, Integer> mapping2) { return mapping2.getValue().compareTo(mapping1.getValue()); } });
代码说明:统计每个单词出现频率,建立单词与频率的映射,并按照频率高低及字母表(频率一致时参考字母表)排序,将前十个单词输出。
-
-
进阶需求
-
爬虫
public class Main { public static final String BASIC_URL = "http://openaccess.thecvf.com/"; public static final String CVRP_URL = "http://openaccess.thecvf.com/CVPR2018.py"; public static List<String> urList = new ArrayList<String>(); public static void main(String[] args) { try { /*重定向标准输出流*/ System.setOut(new PrintStream("result.txt")); getPaperUrl(); getPaperDetail(); } catch (FileNotFoundException e) { e.printStackTrace(); } } public static void getPaperDetail() { int size; size = urList.size(); // size = 10; for (int i = 0; i < size; i++) { try { Document doc = Jsoup.connect(urList.get(i)).get(); Element content = doc.getElementById("content"); Element paperTitle = content.getElementById("papertitle"); Element paperAbstract = content.getElementById("abstract"); System.out.println(i); System.out.println("Title: "+paperTitle.text()); System.out.println("Abstract: "+paperAbstract.text()+" "); } catch (IOException e) { e.printStackTrace(); } } } public static void getPaperUrl() { try { Document doc = Jsoup.connect(CVRP_URL).get(); // System.out.println(doc); Element content = doc.getElementById("content"); Elements ptitles = content.getElementsByClass("ptitle"); for (int i = 0; i < ptitles.size(); i++) { String link = ptitles.get(i).getElementsByTag("a").attr("href"); urList.add(BASIC_URL+link); // System.out.println(BASIC_URL+link); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }代码说明:获取整个网页HTML代码后再根据
<content><ptitle><a href>等标签获取文章标题、摘要、链接等内容,重定向输出后设置要求格式输出。 -
进阶需求主要功能函数
-
countWord
public int countWord() { numOfWord=0; for (int i = 0; i < titleList.size(); i++) { int countFourLetter = 0; StringBuffer sb = new StringBuffer(); for (int j = 0; j < titleList.get(i).length(); j++) { //四个英文字母开头 if (Character.isLetter(titleList.get(i).charAt(j))) { countFourLetter++; sb.append(titleList.get(i).charAt(j)); if (countFourLetter>=4 && j == titleList.get(i).length()-1) { if (titleWordMap.get(sb.toString())!=null) { int temp = titleWordMap.get(sb.toString()); temp++; titleWordMap.put(sb.toString().toLowerCase(), temp); }else { titleWordMap.put(sb.toString().toLowerCase(), 1); } numOfWord++; } }else if (Character.isDigit(titleList.get(i).charAt(j))&&countFourLetter>=4) { sb.append(titleList.get(i).charAt(j)); if (countFourLetter>=4 && j == titleList.get(i).length()-1) { if (titleWordMap.get(sb.toString())!=null) { int temp = titleWordMap.get(sb.toString()); temp++; titleWordMap.put(sb.toString().toLowerCase(), temp); }else { titleWordMap.put(sb.toString().toLowerCase(), 1); } numOfWord++; } //System.out.println("the digit:"+sb.toString()); }else { if (countFourLetter>=4) { if (titleWordMap.get(sb.toString())!=null) { int temp = titleWordMap.get(sb.toString()); temp++; titleWordMap.put(sb.toString().toLowerCase(), temp); }else { titleWordMap.put(sb.toString().toLowerCase(), 1); } numOfWord++; } countFourLetter=0; sb.delete(0, sb.length()); } } } for (int i = 0; i < abstractList.size(); i++) { int countFourLetter = 0; StringBuffer sb = new StringBuffer(); for (int j = 0; j < abstractList.get(i).length(); j++) { //四个英文字母开头 if (Character.isLetter(abstractList.get(i).charAt(j))) { countFourLetter++; sb.append(abstractList.get(i).charAt(j)); if (countFourLetter>=4 && j == abstractList.get(i).length()-1) { if (abstractWordMap.get(sb.toString())!=null) { int temp = abstractWordMap.get(sb.toString()); temp++; abstractWordMap.put(sb.toString().toLowerCase(), temp); }else { abstractWordMap.put(sb.toString().toLowerCase(), 1); } numOfWord++; } }else if (Character.isDigit(abstractList.get(i).charAt(j))&&countFourLetter>=4) { sb.append(abstractList.get(i).charAt(j)); if (countFourLetter>=4 && j == abstractList.get(i).length()-1) { if (abstractWordMap.get(sb.toString())!=null) { int temp = abstractWordMap.get(sb.toString()); temp++; abstractWordMap.put(sb.toString().toLowerCase(), temp); }else { abstractWordMap.put(sb.toString().toLowerCase(), 1); } numOfWord++; } //System.out.println("the digit:"+sb.toString()); }else { if (countFourLetter>=4) { if (abstractWordMap.get(sb.toString())!=null) { int temp = abstractWordMap.get(sb.toString()); temp++; abstractWordMap.put(sb.toString().toLowerCase(), temp); }else { abstractWordMap.put(sb.toString().toLowerCase(), 1); } numOfWord++; } countFourLetter=0; sb.delete(0, sb.length()); } } } // System.out.println(titleWordMap); // System.out.println(abstractWordMap); return numOfWord; }代码说明:读入字符之后进行单词判断,然后根据标题和摘要标签进行分类存入List。
-
orderWord
public void orderWord(int weightOfTitle, int weightOfAbstract) { //title和abstract中的单词的并集 Set<String> titleSet = titleWordMap.keySet(); Set<String> abstractSet = abstractWordMap.keySet(); Set<String> totalSet = new HashSet<String>(); totalSet.addAll(titleSet); totalSet.addAll(abstractSet); //带上权重重新计算词频 Iterator<String> setIterator = totalSet.iterator(); while(setIterator.hasNext()) { String key = setIterator.next(); int titleValue = titleWordMap.get(key)!=null ? titleWordMap.get(key):0; int abstractValue = abstractWordMap.get(key)!=null ? abstractWordMap.get(key):0; totalWordMap.put(key,titleValue*weightOfTitle+abstractValue*weightOfAbstract); } //按照词频排个序 //通过ArrayList构造函数把map.entrySet()转换成list orderedWordList = new ArrayList<Map.Entry<String, Integer>>(totalWordMap.entrySet()); //通过比较器实现比较排序 Collections.sort(orderedWordList, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> mapping1, Map.Entry<String, Integer> mapping2) { return mapping2.getValue().compareTo(mapping1.getValue()); } }); } -
WordCount2
public WordCount2(String filePath) { try { DataInputStream dataInputStream = new DataInputStream(new FileInputStream(filePath)); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(dataInputStream)); String string; while((string=bufferedReader.readLine()) != null) { if (string.matches("^\d+")) {//论文编号 char[] cbuf = new char[10]; bufferedReader.read(cbuf,0,7); //title里的单词 String titleString = bufferedReader.readLine(); titleList.add(titleString); //System.out.println(titleString); //abstract里的单词 bufferedReader.read(cbuf,0,10); String abstractString = bufferedReader.readLine(); abstractList.add(abstractString); //System.out.println(abstractString); //空格两行不计 bufferedReader.readLine(); bufferedReader.readLine(); } } dataInputStream.close(); bufferedReader.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
-
-
测试
-
测试环节我们使用白盒测试用例设计方法来设计测试用例。白盒测试有六种覆盖标准:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和路径覆盖,发现错误的能力呈由弱至强的变化。 通过研究需求,我们认为应重点测试的情况有以下几种:
- 空白行是否被算作有效行计入行数
- 换行符数目的计算
- 单词的大小写不同是否被认为是不同的单词
- 字符数的认定
- 空白文档或只含分隔符、换行符等的文档的数据统计
-
部分测试代码
public class MainTest { Main wordcount = new Main("D:\学习\软工实践\wordcount\input.txt"); @Test public void testCountChar() { int numOfChar=wordcount.countChar(); int testChar=33; assertEquals(testChar,numOfChar); } @Test public void testCountWord() { int numOfWord=wordcount.countWord(); int testWords=2; assertEquals(testWords,numOfWord); } @Test public void testCountLine() { int numOfLine=wordcount.countLine(); int testLine=4; assertEquals(testLine,numOfLine); } @Test public void testTopTenWord() { List<Map.Entry<String, Integer>> list = wordcount.topTenWord(); String[] testWord= {"snakesre5","name"}; String[] testNum= {"1","1"}; for(int i=0;i<10&&i<list.size();i++) { assertEquals(testWord[i],list.get(i).getKey()); assertEquals(testNum[i],list.get(i).getValue()); } } } -
一些测试样例
编号 测试用例 预期结果 运行结果 1 空白文档 characters:0
words:0lines:0characters:0
words:0lines:02 含三个换行符 characters:3
words:0lines:0characters:3
words:0lines:03 三个换行符+ Namecharacters:7
words:1lines:1<name>:1characters:7
words:1lines:1<name>:14 hiasind asiwdb edfgEfDG AsiWdBASIWDB aSiWdBcharacters: 61words: 7lines: 3<asiwdb>: 4<asind>: 1<edfg>: 1<efdg>: 1characters: 61words: 7lines: 3<asiwdb>: 4<asind>: 1<edfg>: 1<efdg>: 15 hnji o.xsijml9648 ijml974878964152sdcf @)754^&*()characters: 55words: 3lines: 5<ijml9648>: 1<ijml9748>: 1<sdcf>: 1characters: 55words: 3lines: 5<ijml9648>: 1<ijml9748>: 1<sdcf>: 1
总结
- 221600306
- 在此次结对过程中,比较实际地应用了版本控制,虽然看了commit message书写的博客,但是由于经验不足,还是不太能够熟练地表达代码的更改,详略或许不太得当。
- 此次作业我负责功能代码的编写,队友负责测试及博客的撰写。结对过程中我与队友互相充当了对方的领航员,保持了良好的交流合作,一起熬夜写代码也不失为一次难忘的体验!
- 221600307
- 这次作业最大的收获是学会了如何对代码进行性能分析和怎样在开发过程中、后进行测试,在之后的学习工作中一定能够更好的对代码进行优化。遇到的主要困难是之前没有做过测试,如何设置测试数据、怎样才能全面地对程序进行覆盖不遗漏错误是非常值得思考的。再加上对JProfiler不熟悉,使用的过程中看懂各种分析也花费了一点时间。
- 对队友的评价:我的队友代码能力很强,在我做测试无处下手时也给了我很大帮助。我们不是第一次结对,每一次结对完成任务的过程中都很少出现分歧,她是一个非常好的合作者,相信在过去及未来的合作学习中我们还能从对方身上学到更多。