一.Lucene.net的简单介绍
1.为什么要使用Lucene.net
使用like的模糊查询,模糊度太低,中间添加几个字就无法查找。同时会造成数据库的全文检索,效率低下,数据库服务器造成太大的压力,Lucenenet只是一个全文检索引擎开发包,并不是一个完整的搜索引擎,不像www.baidu.com这些成熟的搜索引擎,它只是一个开发的框架,可以实现某些产品
2.Lucene.net的作用
就是利用某种分词算法将文本文件进行切词,然后将分好的词放在索引库中,查询的时候从索引库中进行搜索
二.分词
Lucene.net的使用的时候需要对对文本进行分词,具体的分词算法:一元分词,二元分词和基于词库的分词,一元分词的Analyzer在Lucene.net中已经集成,二元分词算法的分析器网上也有很多,但是这两种分析器在实际的应用中作用并不是很大,主要有实际应用的还是按照词库进行分词的分析器,常用的就是盘古分词。引入Lucene.net.dll文件,接下来就这些分词算法进行演示。
一元分词
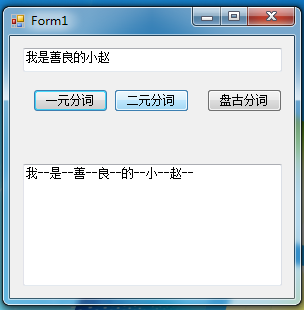
1 /// <summary>
2 /// 一元分词
3 /// </summary>
4 /// <param name="sender"></param>
5 /// <param name="e"></param>
6 private void button1_Click(object sender, EventArgs e)
7 {
8 textBox1.Text = string.Empty;
9 //分析器
10 string sentence = textBox2.Text;
11 if (!string.IsNullOrEmpty(sentence))
12 {
13 Analyzer analyzer = new StandardAnalyzer();
14 TokenStream tokenStream = analyzer.TokenStream("", new StringReader(sentence));
15 Lucene.Net.Analysis.Token token = null;
16 while ((token = tokenStream.Next()) != null)
17 {
18 textBox1.Text += token.TermText() + "--";
19 }
20 }
21 }
二元分词
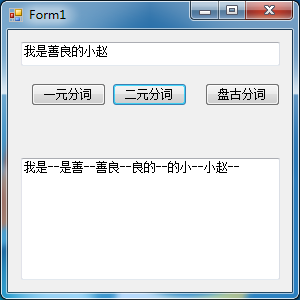
1 /// <summary>
2 /// 二元分词 算法分析器是网上写好的类
3 /// </summary>
4 /// <param name="sender"></param>
5 /// <param name="e"></param>
6 private void button2_Click(object sender, EventArgs e)
7 {
8 textBox1.Text = string.Empty;
9 string sentence = textBox2.Text;
10 if (!string.IsNullOrEmpty(sentence))
11 {
12 Analyzer analyzer = new CJKAnalyzer();
13 TokenStream tokenStream = analyzer.TokenStream("", new StringReader(sentence));
14 Lucene.Net.Analysis.Token token = null;
15 while ((token = tokenStream.Next()) != null)
16 {
17 textBox1.Text += token.TermText() + "--";
18 }
19 }
20 }
盘古分词(此时需要引入盘古分词的两个dll,同时添加票盘古分词的词库文件夹Dict)
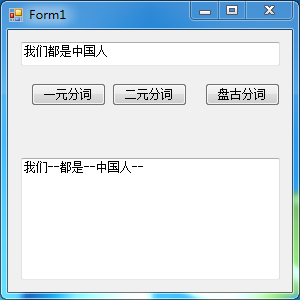
1 /// <summary>
2 /// 盘古分词,基于词库的分词
3 /// </summary>
4 /// <param name="sender"></param>
5 /// <param name="e"></param>
6 private void button3_Click(object sender, EventArgs e)
7 {
8 textBox1.Text = string.Empty;
9 string sentence = textBox2.Text;
10 if (!string.IsNullOrEmpty(sentence))
11 {
12 Analyzer analyzer = new PanGuAnalyzer();
13 TokenStream tokenStream = analyzer.TokenStream("", new StringReader(sentence));
14 Lucene.Net.Analysis.Token token = null;
15 while ((token = tokenStream.Next()) != null)
16 {
17 textBox1.Text += token.TermText() + "--";
18 }
19 }
20 }
盘古分词可能并没有包含你想要的词汇,所以可以通过盘古分词管理工具,对盘古分词的词库进行修改,添加相应的词。
三.使用盘古分词为Lucene.net创建索引库,并实现搜索(粗略的实现,里面一些锁的问题没有解决)
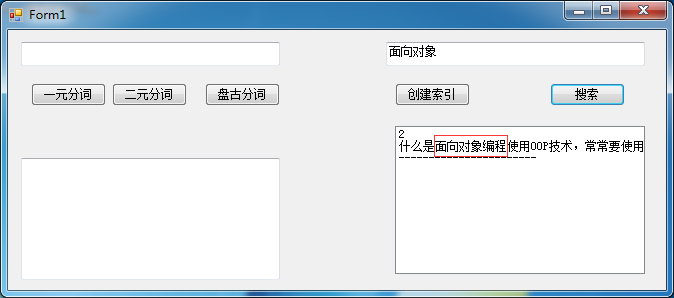
上面进行创建索引的时候,盘古分词的词库中并没有“面向对象编程”这个分词,所以使用它进行查询的时候,Lucene.net的索引库中没有这个词根,可以根据实际情况通过盘古分词管理工具,向词库中添加词汇,然后创建出索引库。
1 /// <summary>
2 /// 创建索引
3 /// </summary>
4 /// <param name="sender"></param>
5 /// <param name="e"></param>
6 private void button4_Click(object sender, EventArgs e)
7 {
8 //将创建的分词内容放在该目录下
9 string indexPath = @"D:LuceneTestDir";
10 //为Lucent.net指定索引文件(打开索引目录) FS指的是就是FileSystem
11 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());
12 //IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。
13 bool isUpdate = IndexReader.IndexExists(directory);
14 if (isUpdate)
15 {
16 //同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。
17 //如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决)
18 if (IndexWriter.IsLocked(directory))
19 {
20 IndexWriter.Unlock(directory);
21 }
22 }
23 //向索引库中写索引。这时在这里加锁。同时指定分词算法是盘古分词
24 //通过writer会将索引写到我们制定的文件夹目录下
25 IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);
26 for (int i = 1; i <= 7; i++)
27 {
28 //我们需要添加到Lucene.net索引库的文件
29 string txt = File.ReadAllText(@"D:测试文件" + i + ".txt", System.Text.Encoding.Default);//注意这个地方的编码
30 Document document = new Document();//表示一篇文档。
31 //Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number")取出值来.Field.Index. NOT_ANALYZED:不进行分词保存
32 document.Add(new Field("number", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
33
34 //Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询)
35
36 //Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。
37 document.Add(new Field("body", txt, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
38 writer.AddDocument(document);
39
40 }
41 writer.Close();//会自动解锁。
42 directory.Close();//不要忘了Close,否则索引结果搜不到
43 }
1 /// <summary>
2 /// 搜索
3 /// </summary>
4 /// <param name="sender"></param>
5 /// <param name="e"></param>
6 private void button5_Click(object sender, EventArgs e)
7 {
8 string indexPath = @"D:LuceneTestDir";
9 string kw = textBox3.Text;
10 if (string.IsNullOrEmpty(kw))
11 {
12 return;
13 }
14
15 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
16 IndexReader reader = IndexReader.Open(directory, true);
17 IndexSearcher searcher = new IndexSearcher(reader);
18 //搜索条件,可以同时制定多个搜索条件
19 PhraseQuery query = new PhraseQuery();
20 query.Add(new Term("body", kw));//body中含有kw的文章
21 query.SetSlop(100);//多个查询条件的词之间的最大距离.在文章中相隔太远 也就无意义.
22 //TopScoreDocCollector是盛放查询结果的容器
23 TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true);
24 //根据query查询条件进行查询,查询结果放入collector容器
25 searcher.Search(query, null, collector);
26 //得到所有查询结果中的文档,GetTotalHits():表示总条数 TopDocs(300, 20);//表示得到300(从300开始),到320(结束)的文档内容.
27 //可以用来实现分页功能
28 ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;
29 this.listBox1.Items.Clear();
30 for (int i = 0; i < docs.Length; i++)
31 {
32 //搜索ScoreDoc[]只能获得文档的id,这样不会把查询结果的Document一次性加载到内存中。降低了内存压力,需要获得文档的详细内容的时候通过searcher.Doc来根据文档id来获得文档的详细内容对象Document.
33 int docId = docs[i].doc;//得到查询结果文档的id(Lucene内部分配的id)
34 Document doc = searcher.Doc(docId);//找到文档id对应的文档详细信息
35 this.listBox1.Items.Add(doc.Get("number") + "
");// 取出放进字段的值
36 this.listBox1.Items.Add(doc.Get("body") + "
");
37 this.listBox1.Items.Add("-----------------------
");
38 }
39 }