作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
一、列表,元组,字典,集合分别如何增删改查及遍历?
1、列表
list=['Jack','Lucy','Mary']
list.append('Pony')
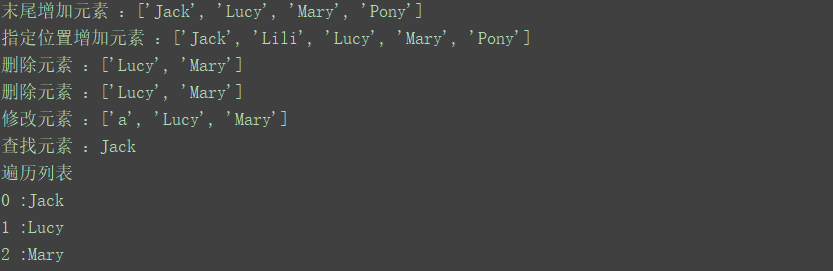
print("末尾增加元素 :{}".format(list))
list.insert(1,"Lili")
print("指定位置增加元素 :{}".format(list))
list=['Jack','Lucy','Mary']
list.remove('Jack')
print("删除元素 :{}".format(list))
list=['Jack','Lucy','Mary']
list.pop(0)
print("删除元素 :{}".format(list))
list=['Jack','Lucy','Mary']
list[0]='a'
print("修改元素 :{}".format(list))
list=['Jack','Lucy','Mary']
print("查找元素 :{}".format(list[0]))
print("遍历列表")
for l in list:
print("{} :{}".format(list.index(l),l))
2、元组
tup=('Jack','Lucy',0)
tup2=('Lili',)
tup3=tup+tup2
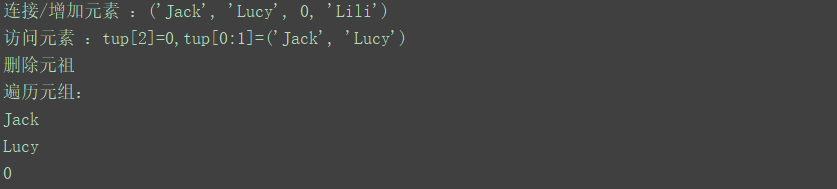
print("连接/增加元素 :{}".format(tup3))
tup=('Jack','Lucy',0)
print("访问元素 :tup[2]={},tup[0:1]={}".format(tup3[2],tup[0:2]))
tup=('Jack','Lucy',0)
print("删除元祖")
del tup
tup=('Jack','Lucy',0)
print("遍历元组:")
for t in tup:
print(t)
3、字典
dict={'Jack':90,'Mary':80,'Tony':70}
dict["abc"]=100
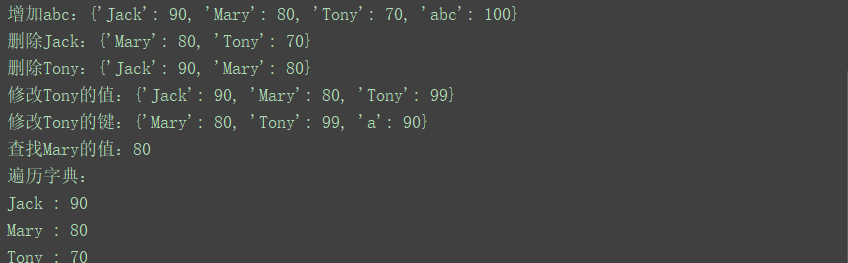
print("增加abc:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
del dict['Jack']
print("删除Jack:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
dict.pop('Tony')
print("删除Tony:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
dict['Tony']=99
print("修改Tony的值:{}".format(dict))
dict['a']=dict.pop('Jack')
print("修改Tony的键:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
print("查找Mary的值:{}".format(dict.get('Mary')))
print("遍历字典:")
for d in dict:
print("{} : {}".format(d,dict[d]))
4、集合
a=set('abcd')
a.add('z')
print("增加'z':",a)
a.update({1,2})
print("增加 1,2:",a)
b=set(('a','b','c'))
b.remove('a')
print("删除a :",b)
a=set('abcd')
a.discard('b')
print("删除a :",a)
a=set('Jack')
a.pop()
print("pop删除 :",a)
a=set('Jack')
a.clear()
print("清空集合 :",a)
a=set('Jack')
b=set(('1','2'))
c=set.union(a,b)
print("集合的合集",c)
print("遍历集合:")
for s in c:
print(s)

二、总结列表,元组,字典,集合的联系与区别。参考以下几个方面:括号、有序无序、可变不可变、重复不可重复、存储与查找方式。
列表:[],有序,可变,可重复,按值存储,序列中的每个元素都分配一个索引,按索引号查找,元素可以是任意类型,可切片
元组:(),有序,与列表类似,但不可变,添加元素时用逗号隔开,按索引号查找,可切片
字典:{},有序,可变容器模型,可存储任意类型对象,按key:value形式存储,但key不可重复,不可切片
集合:(),无序,不可重复,创建格式:set()或parame = {value01,value02,...},每个元素可以是列表,元组,字典,不可切片
三、词频统计
要求:对文本进行预处理、去掉停用词并排序输出
源代码:
fo = open(r'G: estTheLittlePrince.txt', encoding='utf-8-sig')
theLittlePrinceTxt = fo.read()
txt = theLittlePrinceTxt.lower()
fo.close()
sep = ''' ,./:?/! '
" [] () ~ '''
stops = {'by', 'his', 'their', 'again', 'off', 'where', 'now', 'up', 'this', 'before', 'which', 'after', 'a', 'then',
"haven't", 'weren', 'll', 'down', 'or', 'no', "shan't", 'herself', 'in', 'some', 'such', "she's", 'does', 'nor',
'just', "won't", 'them', 'further', 'how', 'am', 'mightn', 'it', 'too', 'ourselves', 'is', 'couldn', 'themselves',
'should', 'ain', 'o', 'hadn', 'under', 'shan', 'him', "it's", 've', 'to', "don't", 'at', 'these', 'our', 'same', 'between',
"you'd", 'isn', 'yourselves', 'until', 't', "mustn't", 'didn', 'few', 'each', 're', 'through', 'above', 'all', "you're",
'been', 'hers', 'have', 'being', 'if', 'theirs', 'most', "doesn't", "hasn't", 'an', 'and', 'below', "couldn't", 'i', 'we',
"hadn't", 'mustn', 'about', "shouldn't", 'there', 'her', 'y', 'here', 'was', "isn't", "needn't", 'were', 'haven', 'out',
'ours', 'over', 'once', 'having', 'against', 'don', 'has', 'but', 'wouldn', 'with', 'other', 'doesn', 'itself', 'aren', 'when',
'as', "wasn't", 'myself', "you'll", 'because', 'the', 'so', "didn't", 'are', 'for', "you've", 'd', 'hasn', 'wasn', 'on', 'he',
's', 'of', 'they', 'needn', 'ma', 'while', 'than', 'from', "weren't", 'those', 'what', 'who', 'himself', "should've", 'will',
'whom', 'more', "mightn't", 'do', 'its', 'why', 'only', 'that', 'during', 'not', 'had', 'own', 'm', 'me', 'very', 'doing', 'can',
'be', 'my', 'both', 'into', "aren't", 'shouldn', 'won', 'yours', 'did', 'you', 'she', 'yourself', 'your', "wouldn't", 'any', "that'll"}
# 定义停用词
for s in sep:
txt = txt.replace(s, " ")
allWord = txt.split()
mset = set(allWord) # 去掉重复的单词,将文本转换为集合
mset = mset - stops # 去除停用词
mdict = {} # 定义字典,用于输出
for m in mset:
mdict[m] = allWord.count(m) # 统计每个字典的key的频数
mlist = list(mdict.items()) # 字典转换成列表
mlist.sort(key=lambda x: x[1], reverse=True) # 列表排序
print(mlist[0:10])
print(mlist[10:20]) #输出top20
import pandas as pd # 在默认目录生成csv文件
pd.DataFrame(data=mlist).to_csv('Little.csv', encoding='utf-8')
结果:


在线词云统计:
