作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一、要求
选择一个热点或者你感兴趣的主题、爬取的对象与范围,爬取相应的内容并做数据分析与文本分析,形成一篇有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明的文章。
二、爬取说明
2019年春节长假,一部电影成了最热话题。《流浪地球》,这部被誉为开创了中国科幻电影元年的大作不但刷爆朋友圈收获满满口碑,票房上也连奏凯歌,堪称是中国史上第一部硬科幻片,原作者刘慈欣也更加广为人知。然而对于刘慈欣来说,流浪地球只是他众多作品中的一个,其实最让人感到惊叹和震撼的其实是他的另一部作品:《三体》三部曲---《三体》、《三体Ⅱ·黑暗森林》、《三体Ⅲ·死神永生》。《三体》作为三部曲的开篇之作,2006年,《三体》开始在《科幻世界》杂志上连载。并迅速成为刘慈欣科幻小说的“巅峰之作”。《三体》这部小说给我留下了深刻的印象,其硬科幻以及超乎想象的剧情是最为精彩的。为了获取读过三体的读者的评价,爬取了豆瓣读书的部分评价,对所爬取的数据进行简要分析。
以下是豆瓣读书短评原网页的结构:
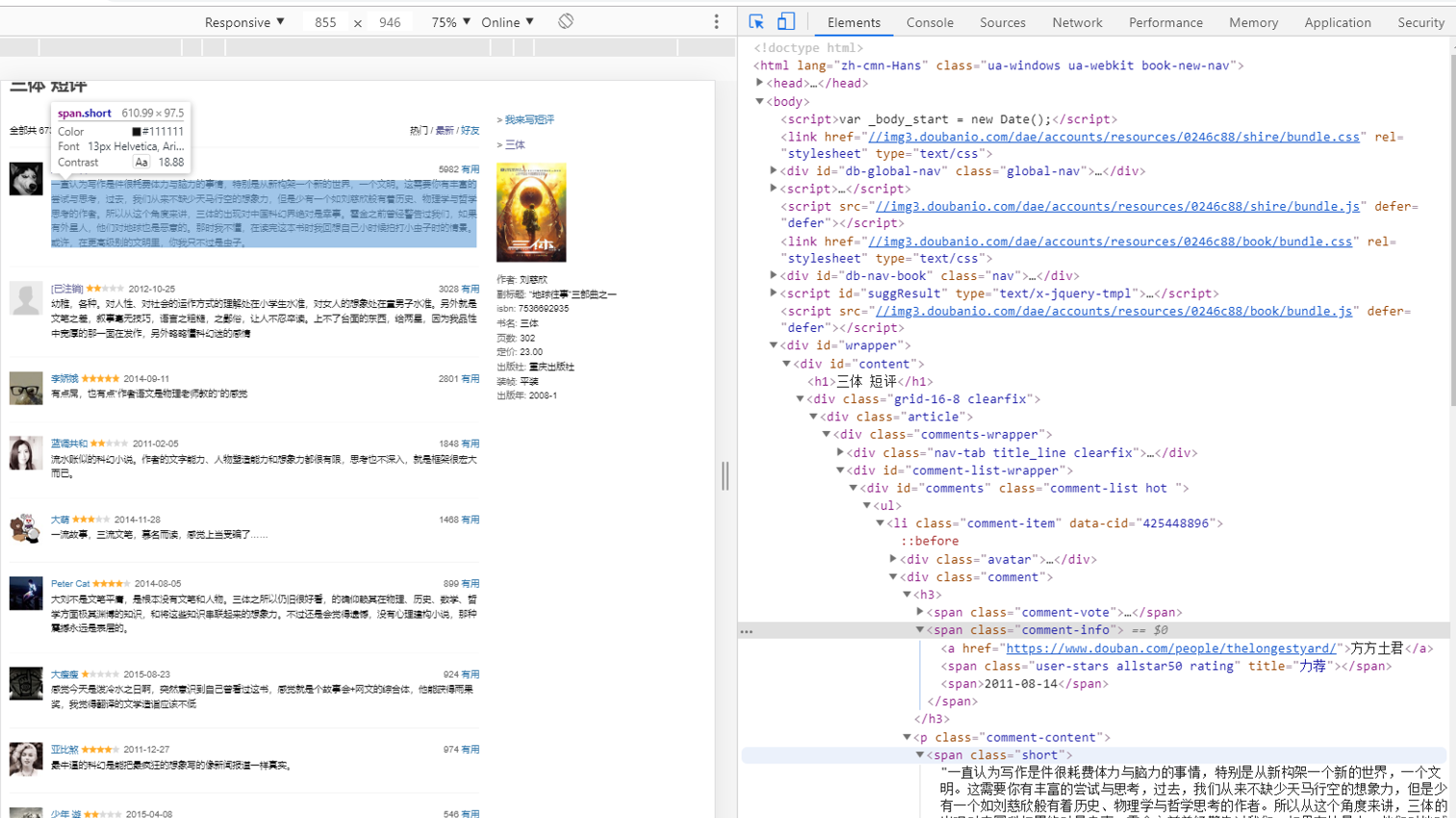
通过对网页结构,找到需要爬取的信息的id,对网页的元素进行筛选和保存:用户名username、用户居住地useraddress、点赞数agree、 评价好坏程度assess、评价时间comment_date以及评价内容。
三、源代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import sqlite3
st1_comment_Url = 'https://book.douban.com/subject/2567698/comments/hot?p=1'
UserAgent = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
]
Http_Ip=[
'47.92.5.85:3128'
#'104.129.11.35:3128',
#'115.159.31.195:8080',
#'111.43.70.58:51547'
]
Https_Ip=[
'111.177.181.152:9999',
'116.208.53.244:9999',
'175.165.129.19:1133',
'116.209.55.223:9999',
'47.92.5.85:3128'
]
headers={
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
proxies = {
"https": '74.208.83.188:80'
#"https": Https_Ip[random.randint(0,4)]
}
res = requests.get(st1_comment_Url, headers=headers, proxies=proxies)
res.encoding = 'utf-8'
#data = requests.get(st1_short_comment_Url,mheader).content
soup = BeautifulSoup(res.text,'html.parser')
all_list = []
def get_address(url):#获取用户的居住地
res = requests.get(url,headers=headers,proxies=proxies)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
adr=''
for a in soup.select('div'):
if len(a.select('.user-info')) > 0:
if len(a.select('a'))>0:
adr=a.select('a')[0].text
c=a.select('a')[0]['href']
if adr=='':
print("已注销")
elif c=='#':
print("未设置地址")
else:
print(adr)
return adr
def comment_each(each_page_url): # 获取短评的信息
res = requests.get(each_page_url,headers=headers,proxies=proxies)
res.encoding = 'utf-8'
#data= requests.get(each_page_url,headers=mheader).content
soup = BeautifulSoup(res.text,'html.parser')
for item in soup.select('li'):
#time.sleep(random.random() * 2) # 设置爬取的时间间隔
if len(item.select('.comment-info')) > 0:
comment_dict = {} # 定义字典为局部变量,避免每次添加新元素时修改字典的内容
a = item.find('span',class_='comment-info')
address_url=a.select('a')[0]['href']
useraddress=get_address(address_url)
username = item.select('a')[0]['title']
agree = item.select('span')[1].text
comment_date = item.select('span')[3].text
if (comment_date == ''): # 评论时间的span不固定,稍加处理
comment_date = item.select('span')[4].text
assess = item.select('span')[3]['title']
else:
assess = "未评价"
comment_dict['username'] = username # 用户名
comment_dict['address'] = useraddress # 居住地
comment_dict['vote'] = agree # 点赞数
comment_dict['assess'] = assess # 评价好坏程度
comment_dict['date'] = comment_date # 评价的时间
comment_dict['short_comment'] = item.select('.short')[0].text # 评价的内容
all_list.append(comment_dict)
if __name__ == '__main__':
for i in range(1, 2500):
comment_Url = 'https://book.douban.com/subject/2567698/comments/hot?p={}'.format(i) # 短评的网页链接
comment_each(comment_Url) # 将字典的元素添加到列表
print(i)
comdf = pd.DataFrame(all_list) # 格式化列表数据
comdf.to_csv(r'D:py_filest_short100.csv', encoding='utf_8_sig') # 保存为csv格式
with sqlite3.connect(r'D:py_filest_short9.sqlite') as db:#保存文件为sql
comdf.to_sql('st9',db)
四、结果
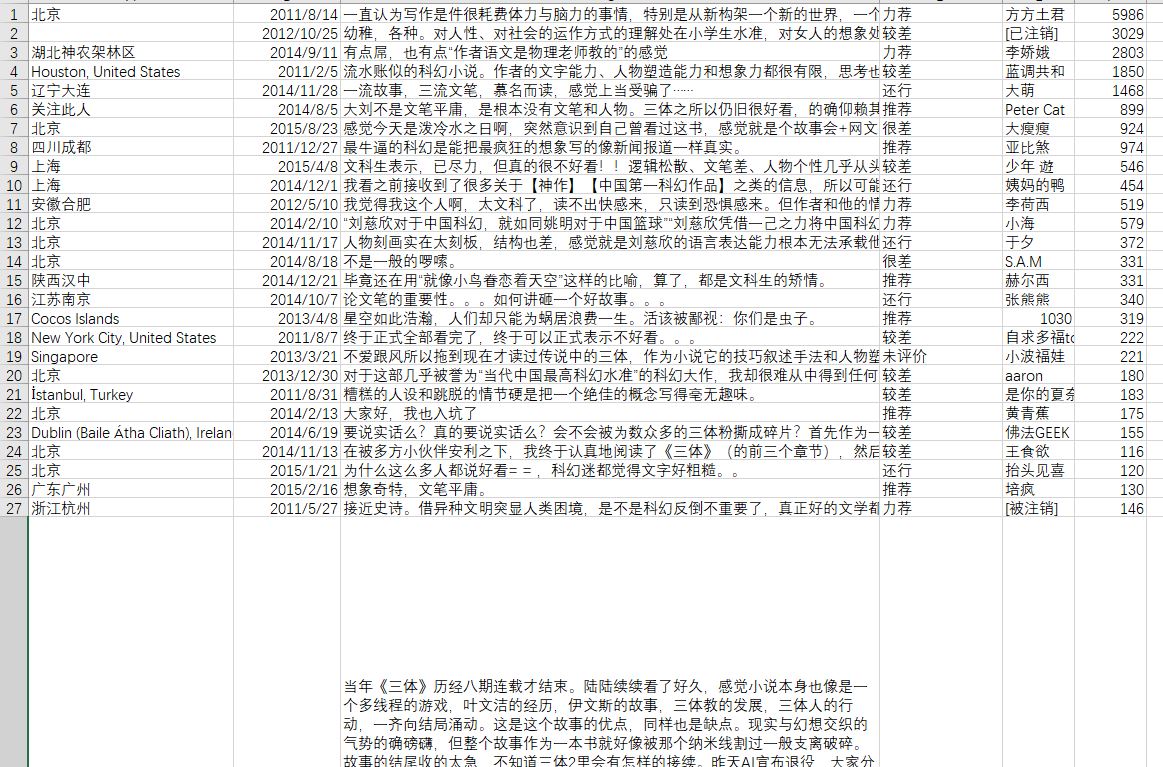
保存爬取的csv数据:
分析:
1、评论者居住地:

将前11位地址数量排序,从图片可看出大多数评论者都集中在北上广杭等一线城市。
2、评论时间:
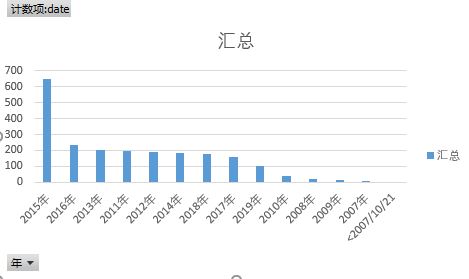
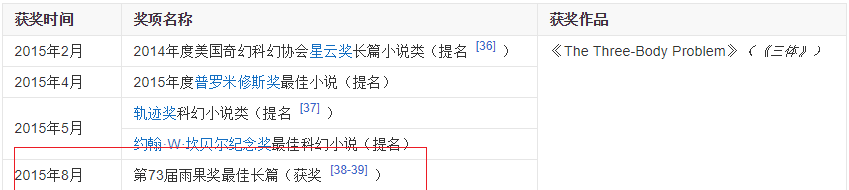
将评论时间排序,得出前13位排序结果,从结果看出,评论时间最多的是2015年,而这部作品获得雨果奖项时刚好是2015,这里可以简单说明大多数读者是在这部作品出名后慕名而读的。
通过上面的简单分析,三体这部作品即使是在得奖后招来许多读者阅读,但是反响效果却不差,大多数还是觉得这部作品好看,说明了了三体赢得了读者的许可。
保存到SQL:
生成词云:

五、总结
1、为了保证不被封ip,整个爬取数据的内容其实是比较缓慢的,而且效率极低,主要用了select筛选元素,其实要用获取数据请求的方式抓取效率才高,但是因为时间原因(期间被封了几次ip,找了代理依旧不能根本解决问题)就暂时抓取这么多数据。
2、从词云上看,《三体》这部小说整体的评价是不错的,大多数评论的关键词是:好看,还不错,神作、脑洞大开、四星半等称赞的词。但同时也存在不一样的声音:文笔太差、文笔一般等评价。不管怎么说,个人认为,硬科幻注定不会让所有人喜欢,但是改变不了我对本书的赞扬。这部小说情节和故事设定超乎想象,感觉作者来自未来,将历史、现实和未来联系在一起。其中我在书中令我影响深刻的是黑暗森林法则 - “1.生存是文明的第一需要。2.文明不断增长和扩张,但宇宙中的物质总量基本保持不变” 在书中通过这两句短短的话,作者发展出来了一个一个理论 - “宇宙就是一座黑暗森林,每个文明都是带枪的猎人,竭力不让脚步发出一点儿声音,因为林中到处都有与他一样潜行的猎人。如果他发现了别的生命,能做的只有一件事:开枪消灭之。在这片森林中,他人就是地狱,就是永恒的威胁,任何暴露自己存在的生命都将很快被消灭。” 最后,借用网友的一句话就是:把科幻小说写成新闻报道那样真实的也就只有刘慈欣了。