
1.简介
Memcached是一款高性能的分布式内存缓存服务器,最初由Brad Fitzpatrick编写,目前在Github上已开源,最近的版本是1.4.24。
11区的Mixi株式会社在memcached的使用上算是走在前列,Mixi是日本最大的社交网站,类似facebook。运营组的长野雅广负责其日常运营工作,并在日本的报纸上刊登了memcached的使用开发技术文章《memcached を知り尽くす》。
memcached有如下feature:
- 协议简单:
- 采用基于文本行的协议,而不是其他复杂的格式。
- 基于libevent的事件处理机制
- Memcached使用了基于libevent的事件处理,它将Linux的epoll、BSD的kqueue等事件处理功能封装成统一接口,即使对服务器 的连接数增加,也能发挥O(1)的性能。 libevent是一个基于事件驱动的,可用于开发可扩展服务的网络库,具有轻量级、跨平台等特点。
- 有自己的内存存储方式
- memcached使用了类似linux内核中的slab内存管理机制,能够尽量减少内存页间碎片,然而并不能很好的解决页内碎片的问题,这是目前存在的一个比较大的问题,由于还未对源码进行比较细致的研究,因此并不能十分肯定当前最新版本是否解决了这一问题。
- memcached不互相通信的分布式
- 虽然memcached是分布式缓存服务器,但memcached之间并不互相通信,服务端也并没有分布式功能。
2.基本架构
我们知道使用缓存服务器的目的是通过缓存数据库查询结果,从缓存或内存中直接读取数据而不是硬盘,减少数据库访问次数,减少I/O次数,从这个开源软件的名称就可见一斑。(这里就应该想到需要解决一致性问题)Memcached的数据原理如下图,首次访问数据时,通过RDBMS读取到浏览器(图中蓝色箭头所示),此时会将读取结果保存到memcached,以后的读取将从memcached获取数据(如绿色箭头所示),避免过多的数据库访问。客户端会通过数据的key来决定保存数据的memcached服务器,服务器选定后将保存数据的键和值。获取数据时也是选择同样的算法,通过将key传递给数据库,根据key选择服务器,就能选中与保存时相同的服务器,然后发送get命令获取数据。
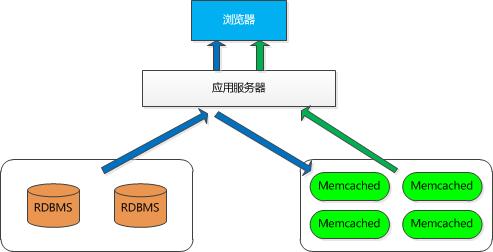
figure1
3.分布式算法
Memcached最令人脑洞大开的地方是其分布式算法。分布式算法有很多种,首先最容易想到的是hash函数,给定一个hash函数,通过计算数据的hash值,来判断数据需要存储到哪个对应的节点上。最常见的hash算法就是除留余数法,以服务器的台数为除数,并且通过一些设计上的改进使得数据能够尽量均匀分布到各个节点上,避免单个节点负载过重。Memcached的作者也提供了相应算法库,hash函数采用CRC32,算法如下所示:
1 use strict; 2 use warnings; 3 use String::CRC32; 4 5 my @nodes = (‘node1’, ‘node2’, ‘node3’); 6 my @keys = (‘tokyo’, ‘kanagawa’, ‘chiba’, ‘saitama’, ‘gunma’); 7 8 foreach my $key (@keys) { 9 my $crc = crc32($key); 10 my $mod = $crc % ( $#nodes +1); 11 my $server = $nodes[ $mod ]; 12 printf “%s = > %s ”,$key, $server; 13 }
这种算法一看似乎并没有什么问题,可是如果因为数据量的增大,我们需要在系统中增加服务器台数的话,那么所有数据的分布均需要重新计算,而且由于服务器台数增加将会导致同一数据在新的系统中存储的节点号改变,大量数据需要迁移,代价将十分巨大,数据部署的原则之一就是尽量减少迁移,尽可能均匀分布,因此单纯使用除留余数法并不是一种合适的方式。
来看另外一种算法:Consistent hashing
如figure2所示, Consistent hashing首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆上。然后用同样的方法求出存储数据的key的hash值,并映射到圆上。然后从数据映射到的位置按顺时针方向查找,将数据保存到找到的第一个临近服务器上。如果超过232仍然找不到服务器,就会默认保存到第一台memcached服务器上。
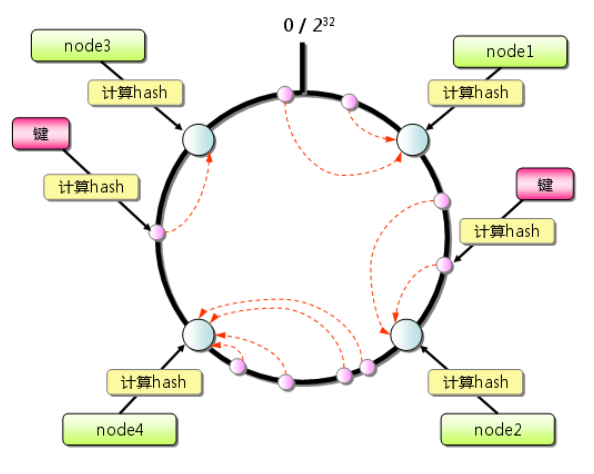
figure2

figure3
当数据增加,需要在node2和node4之间增加一个服务器节点时,如figure3所示,根据上述算法,node5之前的数据原本需要存储在node4中,此时,会将这些数据迁移到node5中,而并不影响其他数据的分布,node5之后的数据依旧分布在node4中,这样迁移代价大大降低,从而不失为一种高效的分布式算法。而且即使一台memcached服务器发生故障后,也不会影响其他的缓存,只是某些应当存储在故障节点的数据需要迁移到临近的下一节点上。不得不说看到这种分布算法真是大开脑洞,为了减少数据的重新分布,竟然能在实际应用中使用这种算法,开发者的智慧和潜力可谓无限巨大。当然memcached的hash算法并不止这么两种,只是我暂时只看了两种,另外,memcached的内存分配、管理机制也有独特之处,由于个人对这块比较熟,所以暂不讨论。
读完这本ebook,感觉现在11区的软件开发人员正在超越欧美,又如Ruby的作者是日本人松本弘行 。这本ebook一共才36页,一个上午不到就看完了,然而比我之前专门卖的国内的一些关于分布式、运维相关的书获得的收获都要大,因为其对一些常见的概念,一些并不复杂的算法均能够一两句话阐述清楚,这才是高手以及一个心态正常的Dev应该写出来的东西。反观国内的一些技术书籍,杂乱无章,故意将简单概念和算法复杂化以体现自身水平,其实适得其反,深入浅出和浅入深出的差距,呵呵。
本文算是《memcached全面剖析》的读书笔记,个人浅见,如果有误,希望不吝指正,下一步打算仔细研究下源码。
References
1.memcached官网地址:http://memcached.org/
2.memcached的Github地址: https://github.com/memcached/memcached
3.MIXI:https://mixi.jp/