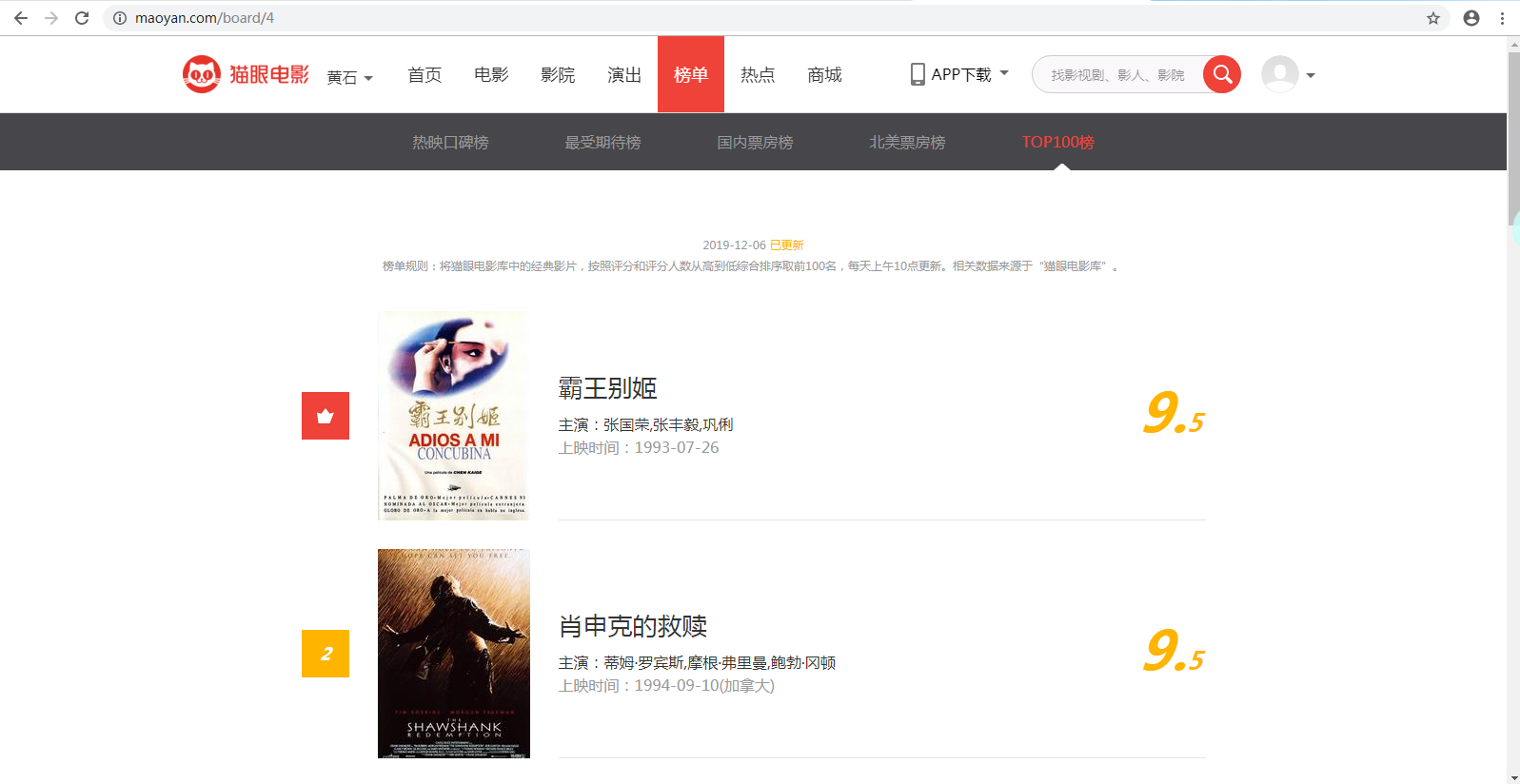
首先我们先找到它的首页:https://maoyan.com/board/4
点击“下一页”,可以看到第二页的URL为:https://maoyan.com/board/4?offset=10
此时我们可以分析出,第一页的URL为:https://maoyan.com/board/4?offset=0,输入URL到浏览器的地址栏,发现跳转到第一页。
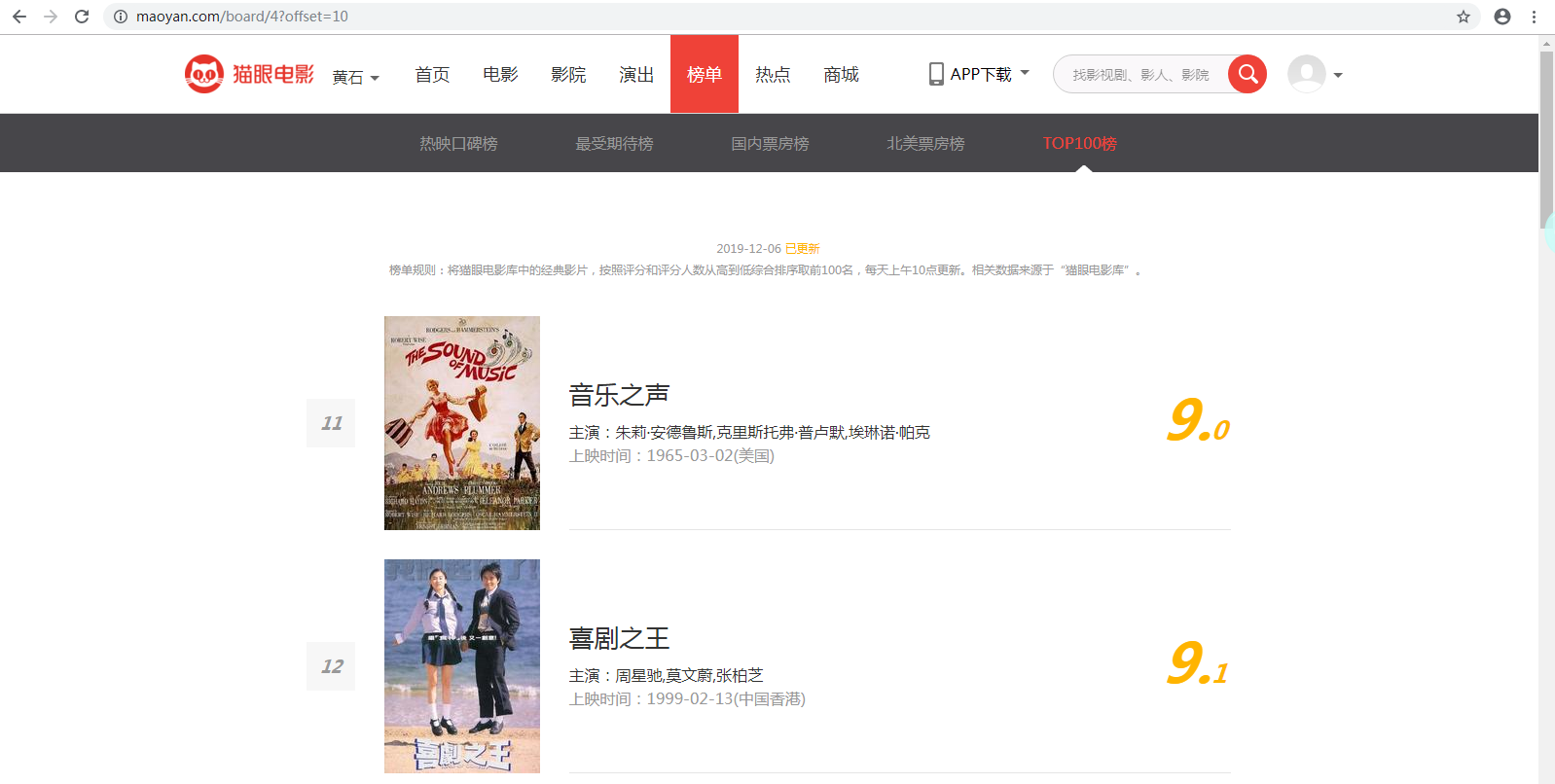
这时,我们可以得出,该网页的结构是:https://maoyan.com/board/4?offset=
然后查看网页上可以爬取的电影信息,可以看到电影名称、主演、上映时间和评分都是可以爬取的。选中信息,检查这些元素在HTML网页中的位置。

在了解了网页和要爬取的元素之后,我们就可以着手爬取了

根据思路,我们先爬取网页的源码:
def get_one_page(url): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' } response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: return None
然后从源码中分析出我们所需的内容:
def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield { 'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] }
提取出数据后,将爬取出来的数据保存在文件里:
def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + ' ')
最后,将爬取的网页转到下一页(第二页),然后循环进行爬取,保存。
完整代码:
import json import requests from requests.exceptions import RequestException import re import time def get_one_page(url): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' } response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: return None def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield { 'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] } def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + ' ') def main(offset): url = 'http://maoyan.com/board/4?offset=' + str(offset) html = get_one_page(url) for item in parse_one_page(html): print(item) write_to_file(item) if __name__ == '__main__': for i in range(10): main(offset=i * 10) time.sleep(1)
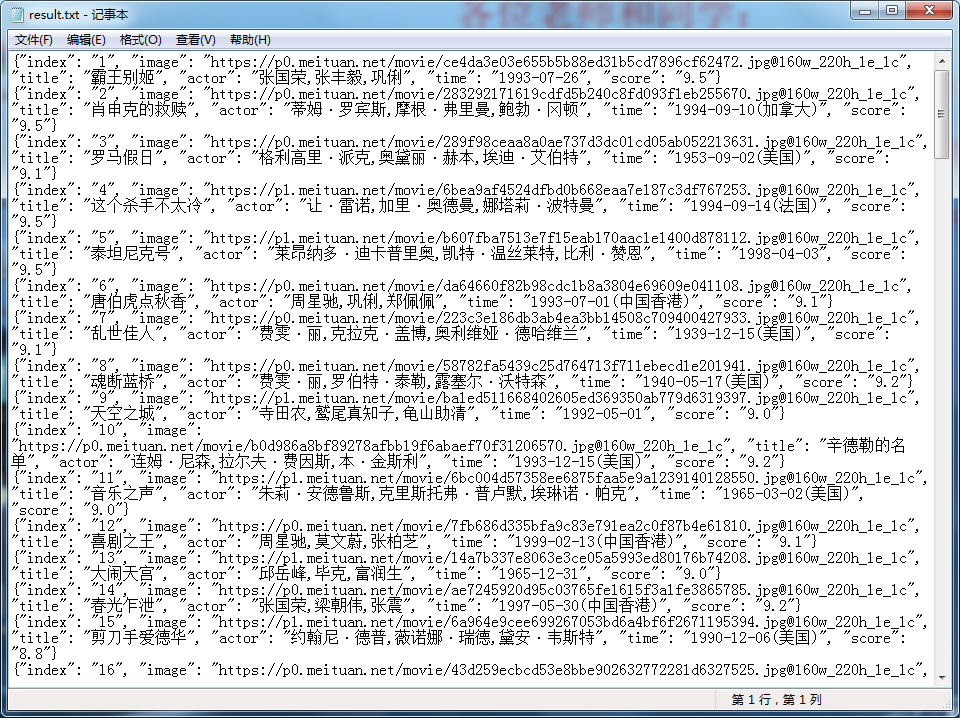
运行代码后,结果如下:

代码爬取了电影的信息,而且将它们以.txt的格式保存下来。