Redis 的概述和数据类型
NoSql 的学习笔记
一、NoSql 的入门和概述
-
为什么使用NoSql
省略
-
是什么
- 泛指 非关系型的数据库
- 产生就是为了解决大规模数据集合种类带来的挑战,尤其是大数据
-
能干嘛
-
易扩展
- 去掉了 关系型数据库的特性
-
大数据量高性能
-
多样灵活的数据模型
-
传统的RDBMS vs NoSql
-
RDBMS
-
高度组织化结构化数据
-
结构化查询语言(SQL)
-
数据和关系都存储在单独的表中。
-
数据操纵语言,数据定义语言
-
严格的一致性
-
基础事务
-
-
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
-
-
-
3V + 3 高
-
大数据时代的3V
- 海量Volume
- 多样Variety
- 实时Velocity
-
3高
- 高并发
- 高可扩
- 高性能
-
当下的使用
- MySQL和nosql 是结合使用的
-
NoSql 的数据模型简介
-
nosql 使用BSON 来设计的
{ "customer":{ "id":1136, "name":"Z3", "billingAddress":[{"city":"beijing"}], "orders":[ { "id":17, "customerId":1136, "orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}], "shippingAddress":[{"city":"beijing"}] "orderPayment":[{"ccinfo":"111-222-333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}], } ] } }
-
-
高并发的操作 不太建议有关联查询。
-
聚合模型
- kV 键值
- bson
- 列族
- 是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩
- 图形
- 例如 亲戚关系的宗谱
-
在分布式数据库中CAP 原理 CAP 和BASE
-
传统的ACID
- 原子性
- 一致性
- 独立性
- 持久性
-
CAP
- 强一致性Consistency
- 可用性Availability
- 分区容错性Partition tolerance
-
CAP 的取舍
- 现实是最多实现 两种,而 分区容错性(p) 是必须的
- CA 传统的oracle 数据库
- AP 大多数网站架构的选择
- CP Redis 、Mongodb
-
CAP 图
-
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
-
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
-
CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
-
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
-
-
-
BASE 是什么
- BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
- 基本可用 ,软状态,最终一致
-
分布式和集群式
- 分布式 是 : 不同的多台服务器 部署不同的服务模块,之间采用RPC/RMi 通信,
- 集群 是 : 不同的多台服务器 上面部署相同的 服务模块,通过分布式调度软件 进行统一的调度
-
二、Redis 的入门介绍
1. 安装
-
下载 redis…tar.gz 放入 自己安装的文件夹
-
解压
-
进入目录
-
进行编译 和安装 (其实不用Redis Test )
-
只要学习linux就会安装
-
查看默认安装目录 usr/local/bin
- redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何
- redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
- redis-check-dump:修复有问题的dump.rdb文件
- redis-cli:客户端,操作入口
- redis-sentinel:redis集群使用
- redis-server:Redis服务器启动命令
-
启动
- 不要使用默认的配置文件,切记,,任何新东西先备份 再操作
- 修改redis.conf文件将里面的daemonize no 改成 yes,让服务在后台启动
- 将默认的redis.conf拷贝到自己定义好的一个路径下,比如/myconf
- /usr/local/bin目录下运行redis-server,运行拷贝出存放了自定义conf文件目录下的redis.conf文件
-
关闭
- 单实例关闭:redis-cli shutdown
- 多实例关闭,指定端口关闭:redis-cli -p 6379 shutdown
2. 启动后的基础知识
- 单进程
- 单进程模型来处理客户端的请求。对读写等事件的响应 ,是通过对epoll函数的包装来做到的。Redis的实际处理速度完全依靠主进程的执行效率
- epoll是Linux内核为处理大批量文件描述符而作了改进的epoll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
- 数据库
- 默认16个数据库,类似数组下表从零开始,初始默认使用零号库
- select命令切换数据库
- dbsize查看当前数据库的key的数量
- flushdb:清空当前库 只在学习阶段使用
- Flushall;通杀全部库 只在学习阶段使用
- 统一密码管理,16个库都是同样密码,要么都OK要么一个也连接不上
- Redis索引都是从零开始
- 为什么默认端口是6379 可以配置文件改
三、 Redis 数据类型
1. Redis 的五大数据类型
- string(字符串)
- 以键值对的形式(最大支持512M)
- hash(哈希,类似java里的Map)
- list(列表)
- set(集合)
- zset(sorted set:有序集合)
- 在每一个元素 还关联一个 double类型的分数 —这个可以重复
2. 常见的数据类型操作命令
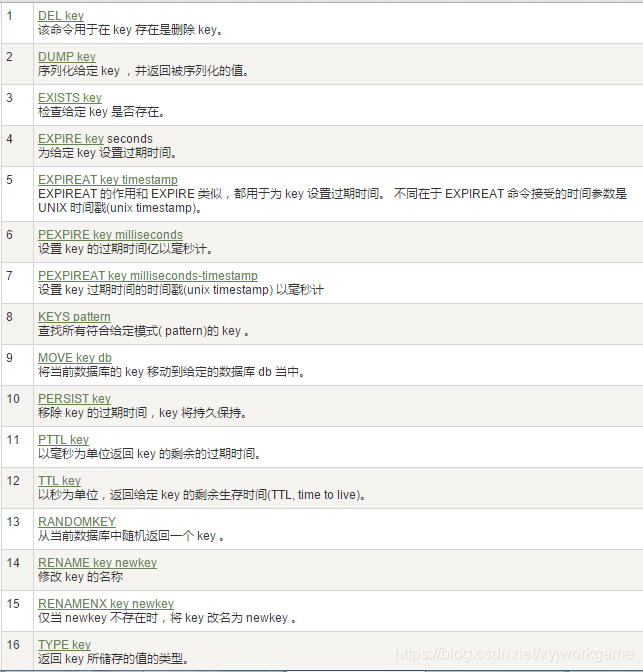
3. Redis 键(key)
4. 字符串
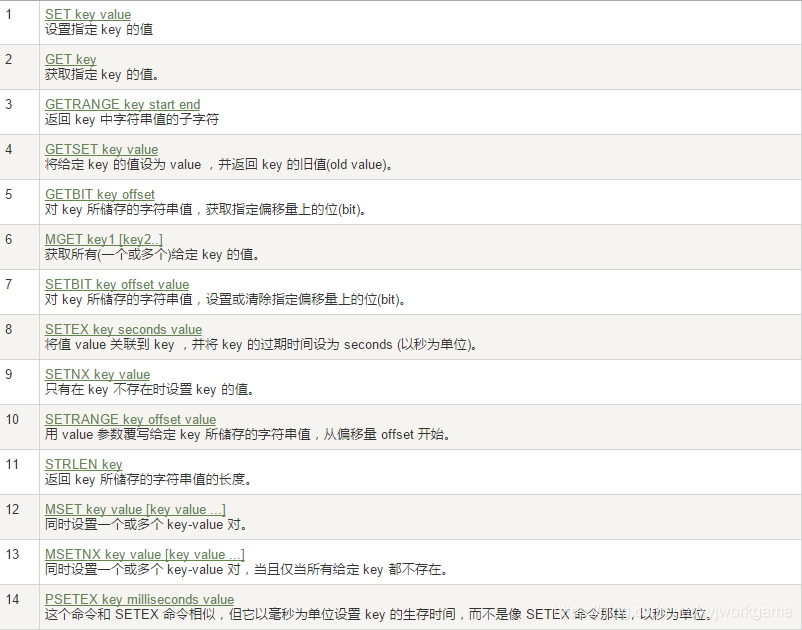

- 单值单value
5. 列表list
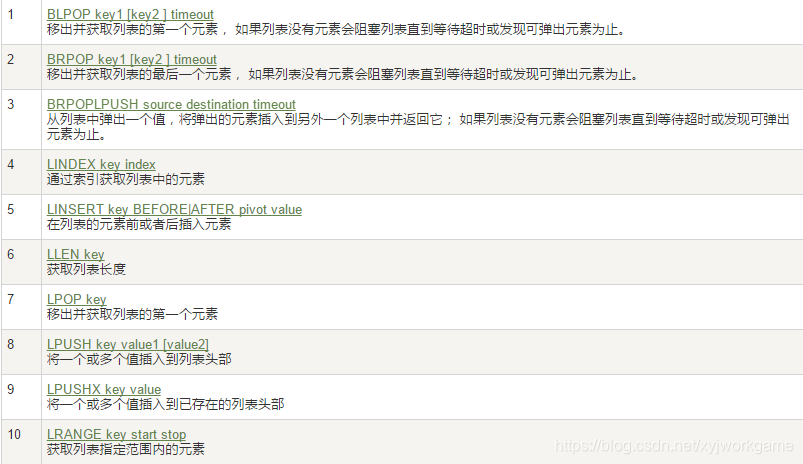
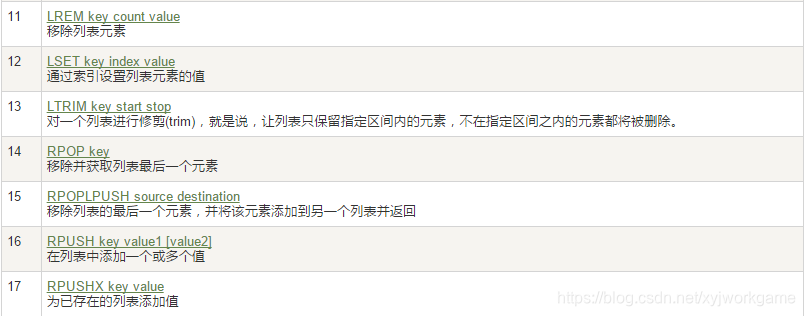
- 列表 对于头尾 的效率最高,而中间的效率很惨淡
6. 集合
1. 单值多value
2. 数学集合类
1. 差集 sdiff
2. 交集 sinter
3. 并集 sunion
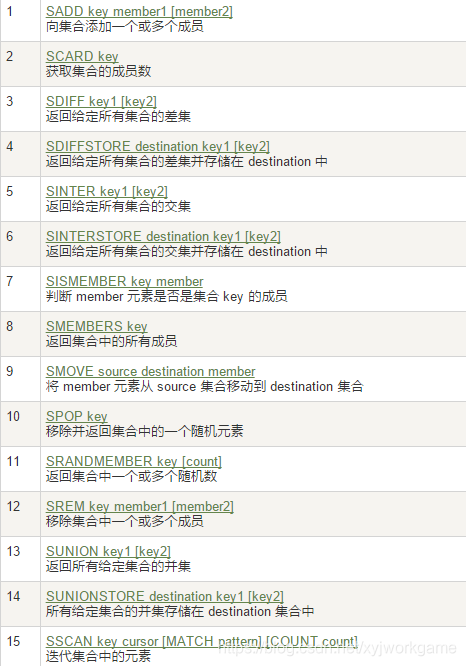
7. 哈希Hash
- KV模式不变,但V是一个键值对
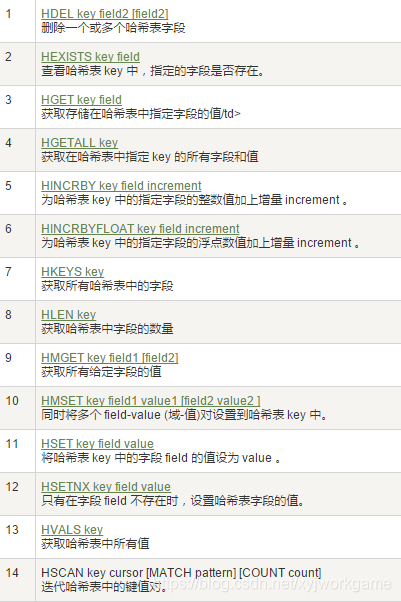
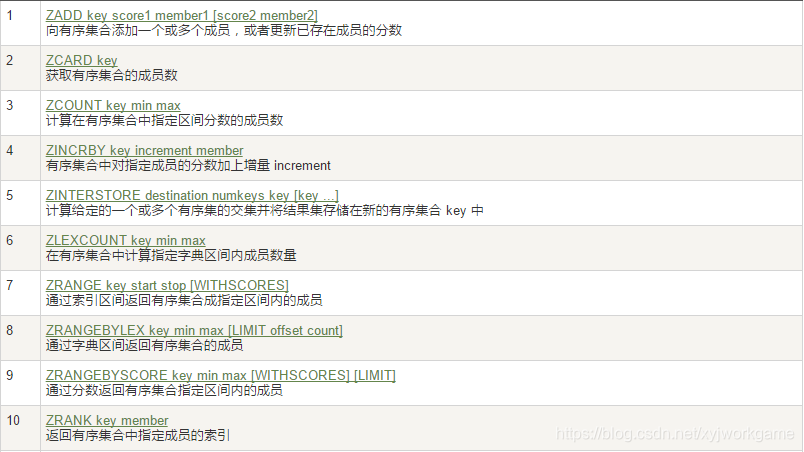
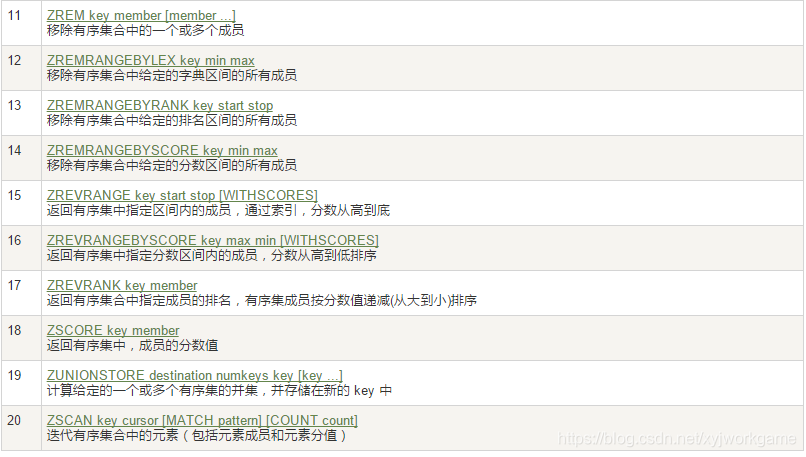
8.有序集合Zset
- 在set基础上,加一个score值。之前set是k1 v1 v2 v3,现在zset是k1 score1 v1 score2 v2