参考博客:https://www.cnblogs.com/wupeiqi/articles/6229292.html + http://www.scrapyd.cn/doc/
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。

Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
建议先下载安装Anaconda,然后通过该工具安装scrapy。

二、命令行工具
1:全局命令


1:startproject 创建项目: scrapy strartproject scrapychina 2:genspider 根据蜘蛛模板创建蜘蛛 scrapy genspider example example.com 3:settings 查看到你对你的scray设置 蜘蛛的下载延迟:scrapy settings --get DOWNLOAD_DELAY 蜘蛛的名字:scrapy settings --get BOT_NAME 4:runspider 运行蜘蛛除了使用:scrapy crawl XX之外,我们还能用:runspider scrapy runspider scrapy_cn.py 区别:前者是基于项目运行,后者是基于文件运行,也就是说你按照scrapy的蜘蛛格式编写了一个py文件,那你不想创建项目,那你就可以使用runspider,比如你编写了一个:scrapyd_cn.py的蜘蛛 5:shell 主要是调试用。比较重要 scrapy shell http://www.scrapyd.cn 6:fetch 模拟我们的蜘蛛下载页 scrapy fetch http://www.scrapyd.cn >d:/3.html 7:view 和fetch类似都是查看蜘蛛看到的是否和你看到的一致 scrapy view http://www.scrapyd.cn 8:version 查看scrapy版本 scrapy version
2:项目命令
crawl
check
list
edit
parse
bench
三、牛刀小试
1:创建项目、爬虫
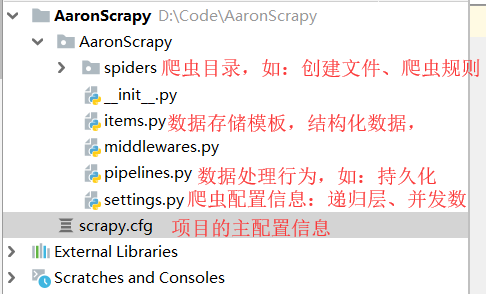
scrapy startproject AaronScrapy
cd AaronScrapy
scrapy genspider chouti chouti.com
2:运行爬虫
scrapy crawl chouti
需要注意的是,要将setting中的遵守机器人协议关掉。通俗来说, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页 不希望 你进行爬取收录。在Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
当然,我们并不是在做搜索引擎,而且在某些情况下我们想要获取的内容恰恰是被 robots.txt 所禁止访问的。所以,某些时候,我们就要将此配置项设置为 False ,拒绝遵守 Robot协议 !
# -*- coding: utf-8 -*- import scrapy # import sys # import io # sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') # A:首先我们需要创建一个类,并继承scrapy的一个子类:scrapy.Spider 或者是其他蜘蛛类型,后面会说到,除了Spider还有很多牛X的蜘蛛类型; class ChoutiSpider(scrapy.Spider): name = 'chouti' # B:然后定义一个蜘蛛名,name=“” allowed_domains = ['chouti.com'] start_urls = ['http://dig.chouti.com/'] # C:定义我们需要爬取的网址,没有网址蜘蛛肿么爬 def parse(self, response): print(response) print("Hello,Scrapy")
3:我们来扒一下cnblogs中我一共写了哪些随笔
# -*- coding: utf-8 -*- import scrapy from scrapy.selector import Selector # import sys # import io # sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') # A:首先我们需要创建一个类,并继承scrapy的一个子类:scrapy.Spider 或者是其他蜘蛛类型,后面会说到,除了Spider还有很多牛X的蜘蛛类型; class ChoutiSpider(scrapy.Spider): name = 'cnblogs' # B:然后定义一个蜘蛛名,name=“” allowed_domains = ['cnblogs.com'] start_urls = ['https://www.cnblogs.com/YK2012/default.html?page=2'] # C:定义我们需要爬取的网址,没有网址蜘蛛肿么爬 def parse(self, response): HeaderTitle= response.css('#Header1_HeaderTitle')[0] autor= HeaderTitle.css('::text').extract_first() #作者 articles = response.css('div.day') for article in articles: time=article.css('.dayTitle a::text').extract_first() # 时间 title = article.css('.postTitle2::text').extract_first() #标题 fileName = '%s-随笔.txt' % autor # 爬取的内容存入文件,文件名为:作者-随笔.txt f = open(fileName, "a+") # 追加写入文件 f.write(time.strip()+" "+title.strip()) # 写入标签 f.write(' ') # 换行 f.close() # 关闭文件操作 # < a href = "https://www.cnblogs.com/YK2012/default.html?page=20" > 下一页 < / a > pages = response.css('#homepage_top_pager .pager a') next_page = None for page in pages: if(page.css('::text').extract_first().strip()=="下一页"): next_page=page.css('::attr(href)').extract_first().strip() if next_page is not None: next_page = response.urljoin(next_page) yield scrapy.Request(next_page, callback=self.parse)
4:下载图片
4.1 定义item 用于存储文件夹名称和路径
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class AaronscrapyItem(scrapy.Item): # 定义爬取的字段 # name = scrapy.Field() name = scrapy.Field() ImgUrl = scrapy.Field() pass
4.2 创建蜘蛛文件
# -*- coding: utf-8 -*- import scrapy from AaronScrapy.items import AaronscrapyItem class DownloadtestSpider(scrapy.Spider): name = 'DownloadTest' allowed_domains = ['lab.scrapyd.cn'] start_urls = ['http://lab.scrapyd.cn/archives/55.html', 'http://lab.scrapyd.cn/archives/57.html', ] def parse(self, response): item = AaronscrapyItem() #实例化Item imgurls = response.css(".post-content img::attr(src)").extract() #这里是一个集合,含有多张图片 item['ImgUrl'] = imgurls name = response.css(".post-title a::text").extract_first() item['name'] = name yield item
4.3 图片下载中间件的编写
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy import Request from scrapy.pipelines.images import ImagesPipeline import re class AaronscrapyPipeline(ImagesPipeline): def get_media_requests(self, item, info): # 循环每一张图片地址下载 for imge_url in item['ImgUrl']: print(imge_url) yield Request(imge_url,meta={'name':item['name']}) def file_path(self, request, response=None, info=None): # 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字 image_guid = request.url.split('/')[-1] # 提取url前面名称作为图片名。 name= request.meta['name'] #接收上面Meta传递过来的图片名称 # 过滤Windows字符串,否则会有乱码 name=re.sub(r'[?\*|“<>:/]', '', name) #分文件夹存储的关键 filename=u'{0}/{1}'.format(name,image_guid) return filename # def process_item(self, item, spider): # return item
4.4 设置,启动图片下载
#图片存储位置 IMAGES_STORE = 'D:ImageSpider' #启动图片下载中间件 ITEM_PIPELINES = { 'ImageSpider.pipelines.ImagespiderPipeline': 300, }
4.5 效果展示

需要注意的是:
1:[scrapy] WARNING: File (code: 302): Error downloading file from
如果在settings文件中没有设置MEDIA_ALLOW_REDIRECTS参数的话,默认会将值赋值成False 及如果在下载的过程中如果有重定向过程,将不再重定向。
于是我再settings文件中 设置 MEDIA_ALLOW_REDIRECTS =True 问题完美解决!!
2:有些页面上设置了防盗链
防盗链的本质,其实很简单,防盗链的核心是判断你请求的地址是不是来自本服务器,若是,则给你图片,不是则不给,知道了这么一个原则我们就可以破解了,我们每下载一张图片都先伪造一个妹子服务器的请求,然后在下载,那它肯定会给你返回图片,于是我们就能顺利拿到图片!那问题的重点就归结为如何伪造请求地址,scrapy实现起来灰常简单,就是写一个Middleware,代码如下:
def process_request(self, request, spider): referer = request.url if referer: request.headers['referer'] = referer