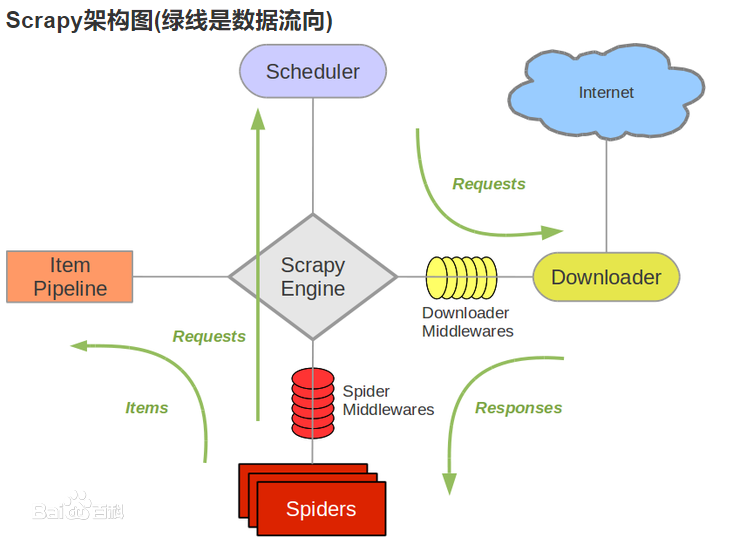
今天开始学习scrapy,对于scrapy我的理解是这样的:假如把我以前写的Python爬虫比作无门无派的散人,scrapy就是名门正派出来的弟子,它提供了一个爬虫框架,这个框架可以完成大多数的爬虫需求,下面就是演示图(摘自百度):
1、下载scrapy
linux:(sudo)pip install scrapy,可以把所有scrapy相关的依赖全部下载上。
Windows:只要有pip,命令同上,但最后还需要下载一个pypiwin32(如果报错ModuleNotFoundError:No module named win32api),同样使用pip下载。
2、创建scrapy项目
这是很麻烦的一步,因为pycharm没法创建scrapy项目,所以无论是Windows还是linux都需要使用命令创建,可以使用命令scrapy查看所有的scrapy可使用命令。
scrapy genspider [项目名] [网站域名] ,切换到想创建项目的的位置,输入以上命令即可。这里我推荐使用pycharm的Terminal,因为它的默认显示的路径就是在你目前项目的路径下,所以直接用Terminal直接输入命令即可。网站域名直接输入www.后面的就可以了,例如填写baidu.com即可,因为scrapy会负责填写上http之类的前缀协议。网站域名起到的作用是限制范围,将爬虫限制到想要爬取的域名之下,不至于出现爬的爬的就跑丢的情况。
3、创建爬虫
进入创建的scrapy项目中,输入 scrapy crawl [爬虫名] ,就可以得到如下Python文件:
# -*- coding: utf-8 -*- import scrapy class GzbdSpider(scrapy.Spider): name = 'gzbd' allowed_domains = ['nhc.gov.cn'] start_urls = ['http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml'] def parse(self, response): pass
name是刚才输入的爬虫名字,名字必须唯一,因为名字是scrapy识别爬虫的唯一代码,避免出现同一scrapy项目下scrapy无法识别用户想要运行哪个爬虫的尴尬问题。同时,上述代码自己打也是没有问题的,不仅如此,连同整个scrapy项目也是一样,手动创建文件夹,文件也是可以的,只要规格和名字与用命令创建的一样就行。